3. The encoding process according to Menota Handbook v. 3.0
The Medieval Nordic Text Archive (www.menota.org) aims at preserving and publishing Nordic languages (at the moment Old Norwegian, Old Swedish and Old Icelandic) and Latin medieval texts in digital form according to its guidelines described in the Menota Handbook. This is a detailed manual of how to encode medieval manuscripts in XML and it includes all necessary schemas in compliance with the latest version P5 of the TEI Guidelines. Therefore, Menota aims at adapting and developing encoding standards for a more complete analysis and thus representation of the texts, which can be indeed encoded on one or more levels: the facsimile level (a very close transcription), the diplomatic level and the normalized level.
For this pilot project, I transcribed the text on fol. 25v with runic characters on the facsimile level, <me:facs>, and transliterated them into the Latin alphabet at the <me:dipl> level. Subsequently, I provided a linguistic annotation, more specifically a morphological analysis. Since the word is the basic unit in any transcription, its relative <w> element may contain further information about its dictionary entry, by means of the attribute @lemma, and about its grammatical form, by means of the attribute @me:msa. See 2.3 Linguistic annotation for more details.
The encoding process I followed consists of two steps: individuating the runes and punctuation marks by going through fol. 25v and listing them at the beginning of the XML file. These steps were preceded by a previous check of the character entities listed in the Menota Entity List, a list of entities, each of which assigned to a unique code point, and edited by Odd Einar Haugen of the University of Bergen. As a matter of fact, if a character is not listed in the Menota list, it can be encoded by means of a suitable character entity and then declared at the beginning of the XML file, within the <!ENTITY> declaration at the end of the list of additional entities. In this case, only few characters of fol. 25v (two runes and few punctuation marks) were already included in the list and were in need of an entity declaration.
Listing and inserting runes
Although the selection of characters in the Latin alphabet for encoding Medieval Nordic texts provided by the Unicode Standard is a large one, the runic characters offered in the Unicode Standard is limited and not comprehensive of all the runic characters used both in the epigraphic context and manuscript tradition. Nevertheless, the aim of this pilot project was to investigate and check whether one or more runes, together with punctuation marks, were in need of a better representation than the one proposed and accepted by the Unicode Standard.
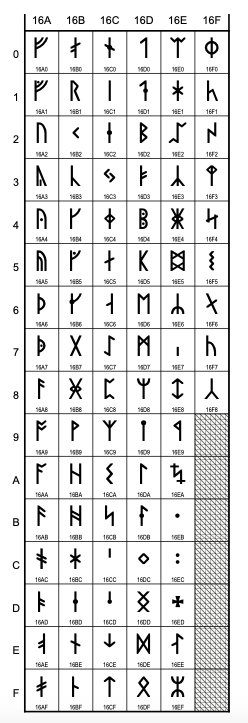
For this reason, the first step consisted of listing the whole set of the specific dotted runes of the folio. To this purpose, I used the Unicode runic chart, which contains the accepted runic characters.
The runes used in this text are the following in order of appearance: ᚢ, ᚦ, ᚠ, ᛁ, ᚮ, ᚱ, ᛂ, ᛅ, ᛋ, ᛐ, ᛆ, ᚿ, ᛑ, ᚴ, ᚯ, ᛔ, ᛚ, ᚼ, ᛘ, ᛎ, ᛕ, ᛦ, ᚵ. However, the Menota list contains only the following two runic characters:
<!ENTITY fMedrun "ᚠ"><!-- RUNIC LETTER FEHU FEOH FE F -->
<!ENTITY mMedrun "ᛘ"><!-- RUNIC LETTER LONG-BRANCH-MADR M -->
They were included since they are used as abbreviation signs in Old Norse manuscripts in the Latin alphabet, the f rune being an abbreviation of fé n. ‘wealth, property’, and the m rune an abbreviation of maðr m. ‘man’. However, for the encoding of a full runic manuscript, many more runes were needed. Therefore, the remaining runes needed an entity declaration to be added at the beginning of the Menotic XML file. The final result was the following:
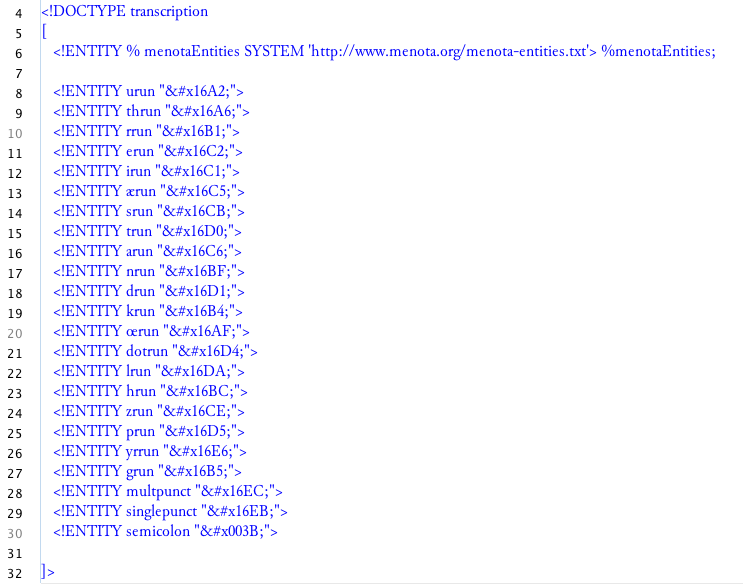
According to the above list, each entity has a descriptive name and corresponds to
its code point retrievable from the Unicode Standard runic chart: for instance,
<!ENTITY urun ᚢ
> refers to RUNIC LETTER URUZ UR U, hence the
descriptive name urun (u- since this rune is a symbol for /u/, and
-run refers to ‘rune’ and it follows the naming of the runes already
included in the Menota list, i.e. fMedrun) and the code point is 16A2 in the
hexadecimal number system.
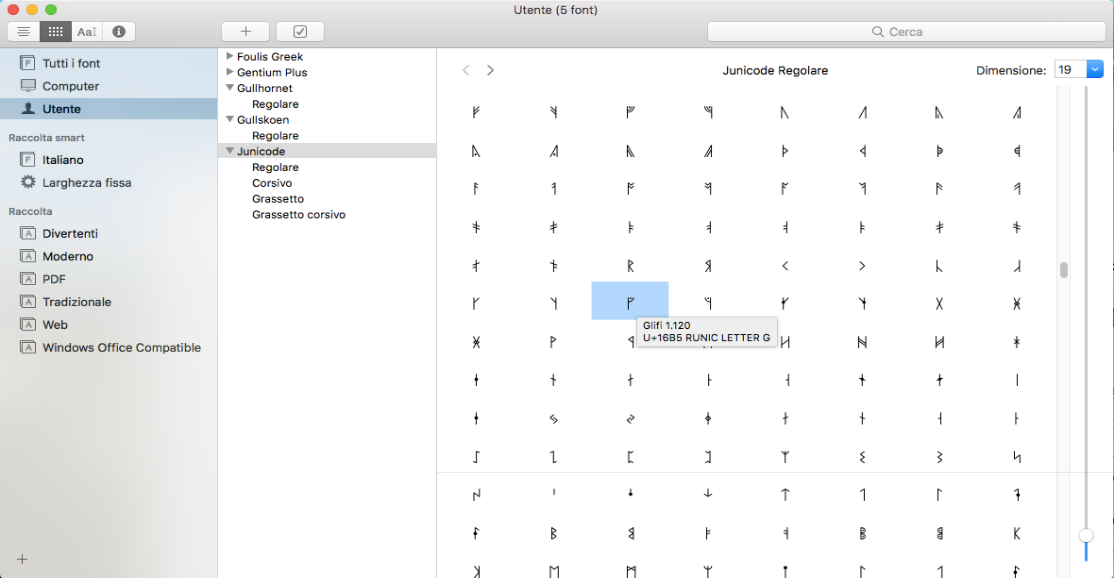
As for inserting the runic characters in the XML file, there were two main options: either by inserting the hexadecimal Unicode number, or by clicking on the characters of the Junicode font by means of the PopChar application or Font Book, which is a timesaver for longer projects than this. As one can see from the below image which represents the screen of the Font Book, it is possible to choose the rune to insert and by pointing the pointer on it, one can see the code point and the name of the character.
However, since the selected text is not long and difficult to transcribe, the runes have been inserted in the XML file by means of hexadecimal Unicode inputs. During the transcription process, I found that, among the runes, the z rune in the word manz (fol. 25v: 7) does not clearly resemble the one written in the selected folio.

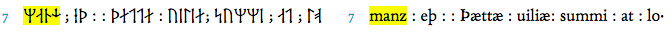
According to the handwritten rune on the folio, the z rune is a combination of a half long vertical or stave running from the top of the line and a right-oriented short oblique stroke or branch. Nonetheless, the only Unicode accepted character for this rune adds also a left-oriented short oblique stroke. For this reason, one should remember that the set of the runes used in the codex is the dotted runic sequence, or better alphabet, where the dots functions as diacritical marks by altering the sound values of the rune, i.e., for instance, by transforming a voiceless consonant into its voiced respective (as exemplified in ch. 2 above).
The d rune taken into consideration in this case is the result of adding a short horizontal stroke across the stave of a t rune; it is still usually referred to as a dotted rune.

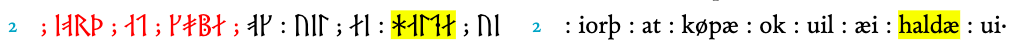


One the basis of these comparisons and from the encoding perspective, one must try
and decide whether the above-mentioned handwritten runes are characters or only
glyphs. The Unicode Standard describes characters as the abstract
representation of the smallest component of written language that have a semantic
value
, while glyphs are defined as the shapes that
characters can have when they are rendered or displayed
.
As Haugen (2013) pointed out, there is also a tendency among linguists to distinguish
between graphemes and graphs
with roughly the same meaning as the character-glyph distinction of Unicode
. However, according to Haugen (2013) two or more glyphs can be
considered representations of the same character if they carry the same semantic
meaning; similarly, they can be considered as variants glyphs of the same
character.
All Unicode charts collect, indeed, the characters, their respective code points and their descriptive names; more specifically, what the user sees is a glyph of a character. Moreover, in the creation and publication of the Unicode runic chart, runes were very likely included on the basis of whether the curved or straight branches would cause a change in meaning. In the runic chart, each character is represented by a glyph with curved or straight branches; nevertheless, as one reads in the page preceding the chart, the glyphs change accordingly to the font one decides to use, thus it seems that a curved branch differentiate from a straight branch just for non-distinctive variation. The concept of variant is not clearly defined in the Unicode Standard, but Haugen (2005) gave a fine explanation of its importance and he defines it as fundamental when encoding specific kind of scripts, especially old scripts, including runes. Therefore, a variant can be defined as a type of a character with non-distinctive features, as in the abovementioned distinction between curved and straight branches. He also stated that the Unicode Standard would consider the straightness and the curvature of a branch as non-distinctive: this means that a character may be rendered by a curved- or a straight-branched glyph, without any distinction between the two. Despite its vagueness, the Unicode Standard underlines that the glyphs are only indicative, still they are the only means to understand what the attributes of a character actually are. Since the descriptive names of the runes in the chart are often non-informative, the shape is an essential part of a character; without the shape there would be no character. Eventually, according to Haugen (2005), users of the Unicode Standard are left to deliberate on the glyphs and to find out themselves which features of a character are actually distinctive or not.
Therefore, with reference to the analysis made in this chapter and in compliance with the main aim of the project, the runes of the folio correspond, in my opinion, to the runic characters collected until now in the runic chart, apart from z rune.
3.2 Listing and inserting punctuation marks
As for the punctuation marks not yet listed in the Menota entity list, the same procedure has been applied to the punctuation marks, which represent an important aspect of the structure of the text of folio 25v. By examining the text, I have identified two well-types of punctuation, the colon and the semicolon, and a third type, which is a cluster of colons and dots (see ). As far as possible, one should use existing code points in the Unicode Standard, so one could easily argue that the colon- and semicolon-shaped punctuation marks could be used for the two first of these. That is what I decided to do in my pilot project, but it is also possible to claim that these punctuation marks belong to a specific runic system and thus should be encoded with specific entities.
For the punctuation cluster, I chose to use a combination of a colon, a middle dot and another colon, all of which are in the Unicode Standard. However, I think that there should be a single Unicode character for the punctuation cluster, and that the code point for this character should be added to the entity list.
The following images display the three different types of punctuation marks, and an example of the encoding of the semicolon mark.




The punctuation marks colon and semicolon are used indifferently to mark the space between words; however, the original distinction of both punctuation marks in the transcription on the facsimile level has been kept, whereas their rendering in the diplomatic level has been uniformed to a colon. The punctuation cluster signals the end of a topic and the beginning of a new one: this is the reason why the first rune following the punctuation cluster is a rubric and appears bolder with respect to the following runes. Together with the z rune, this particular punctuation cluster also need another sign for the rendering.

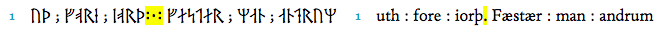
The following image refers to the XML encoding of the abovementioned cluster and the f rune as a capital:

3.3 Linguistic annotation
Menota offers the possibility to analyse the document from a morphological point of view, which can eventually lead to a syntactic analysis, as well. The basic unit of the transcription is the <w> element, each containing a single word of the text. Within this element, information about the dictionary entry and the grammatical analysis of the word in question can be provided by means of two attributes: @lemma, stating the lexical form on the basis of entries in standard dictionaries, and @me:msa, stating the morphosyntactic form.
In order to analyse a word from a lexical point of view, Menota recommends the online Gammeldansk ordbog for Old Danish texts; additionally, for a grammatical analysis, it is necessary to follow a model containing all possible forms of each lemma. Menota suggests a set of name tokens included in the attribute @me:msa in order to assign word classes (parts of speech) to words: e.g. xNC for noun, common, xAJ for adjective, xPE for pronoun, personal, and so on. For the transcription of the selected document, I have considered only the following word classes: Noun, common; Adjective; Pronoun, personal; Pronoun, indefinite; Numeral, cardinal; Verb; Adverb; Preposition (apposition); Conjunction, coordinating; Infinitive marker.

In order to double check the correctness of the lexical entries’ findings of the Gammeldansk ordbog, I have used the online Den Dansk ordbog.
The final result has been published in the Menota Test Catalogue available at http://clarino.uib.no/menota-test/catalogue: both the facsimile and diplomatic encodings are easily searchable and comparable to the high-quality image of the folio at the right of the screen. Moreover, by simply clicking on a word, the morphological information appears together with other data (folio, shelfmark).