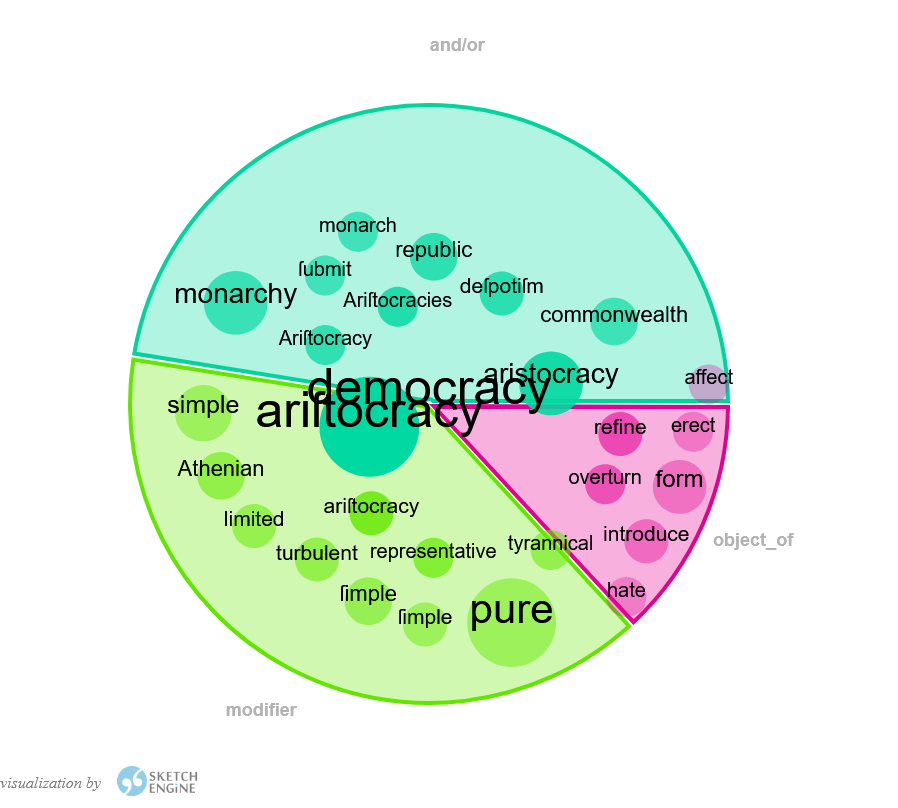
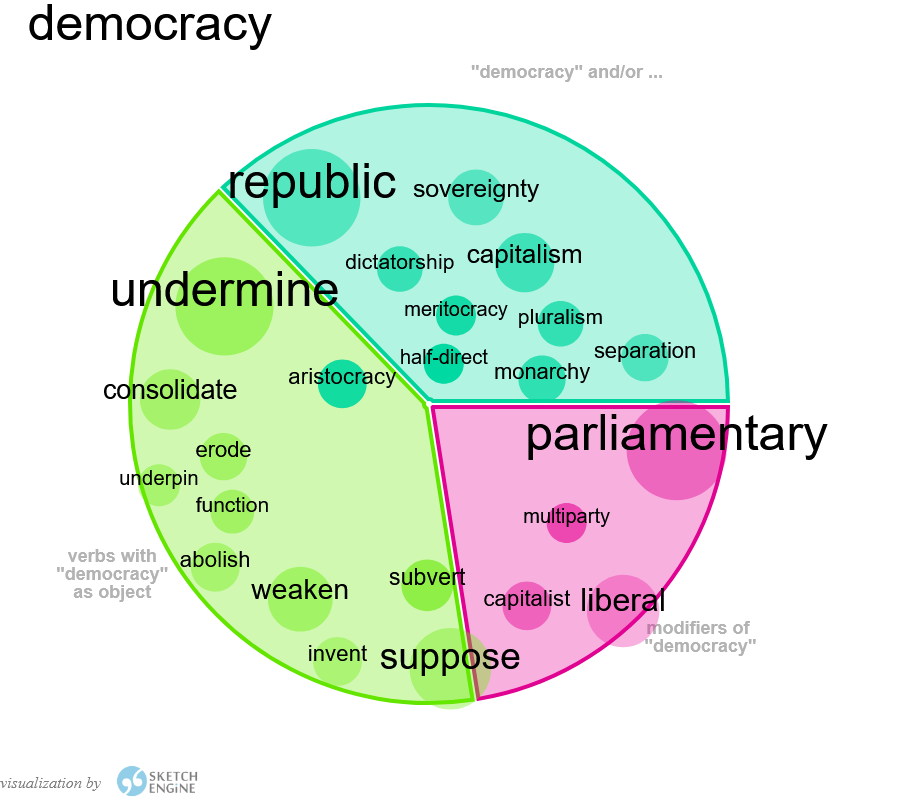
Descrizione e uso delle risorse testuali
Nella seconda sezione di questo articolo presentiamo dapprima una rassegna degli
strumenti e delle risorse disponibili online che permettono l’accesso a testi in
pubblico dominio. Poi illustriamo brevemente le modalità e i risultati di una ricerca
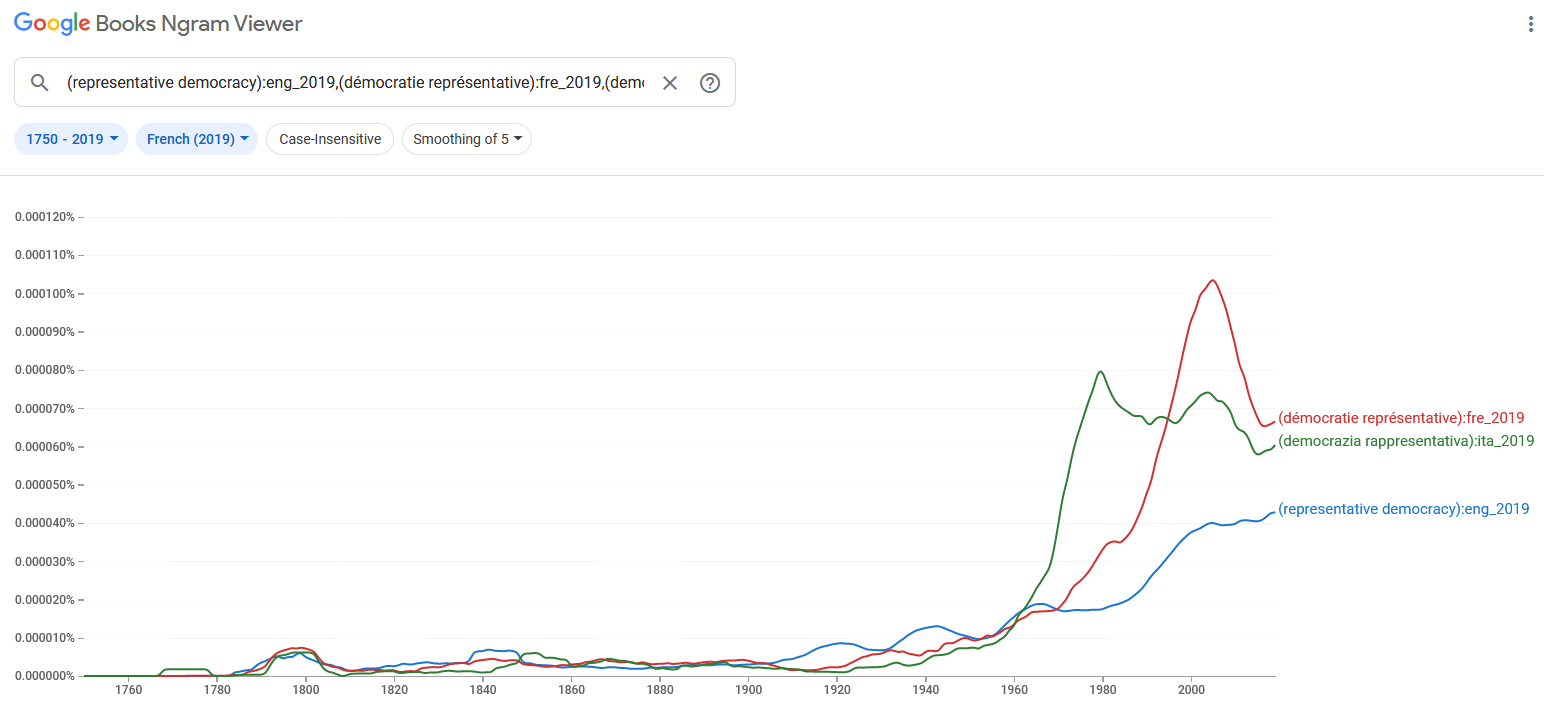
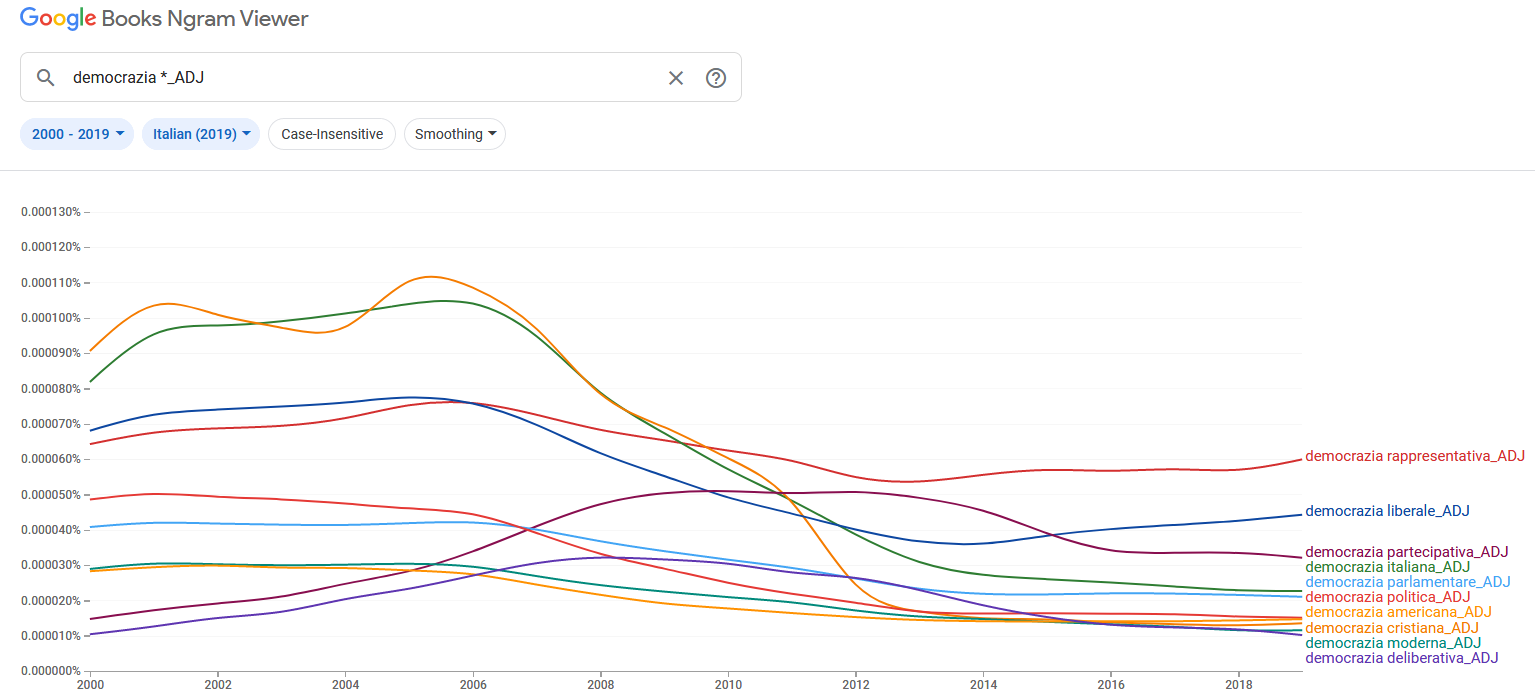
riguardante l’uso del termine democrazia rappresentativa
nell’arco di tempo che
va dal suo primo apparire nei dati da noi verificati, il 1778 (anno in cui il sintagma
compare per la prima volta in un testo stampato a Londra in lingua francese ( ), fino al 1799, data che rappresenta un’importante cesura
storica non solo perché segna la fine del XVIII secolo ma anche per le ripercussioni a
livello internazionale del colpo di Stato napoleonico del 9 novembre 1799.
Banche dati testuali e archivi digitali online
La principale risorsa per quanto riguarda la ricerca sui testi digitali nel pubblico dominio è costituita dal progetto Google Books, iniziato nel 2005 dall'omonima azienda proprietaria del noto motore di ricerca con il proposito di catalogare e indicizzare l'intero patrimonio librario mondiale. Utilizzando un’interfaccia simile a quella del motore di ricerca generale dell’azienda, qualsiasi utente ha accesso ad un database testuale contenente i testi di decine di milioni di libri. La consistenza del corpus, quantificata nel 2009 in 12 milioni di volumi – stimati corrispondere a circa il 15% di tutti i libri prodotti fino ad allora ( : 177) – ha raggiunto nel 2019 i 40 milioni ( ). I testi contenuti in questo database rappresentano indubbiamente il più ampio corpus di libri digitalizzati a livello internazionale e costituiscono una considerevole frazione di tutti i libri mai pubblicati.
Il progetto Google Books è stato accolto in modo critico sotto tre aspetti:
controversie sul diritto d’autore ( : 48-52), dibattito
sulla privatizzazione delle conoscenze e dubbi relativi alla
qualità del prodotto. Per quanto riguarda in particolare quest’ultimo aspetto,
diversi studiosi hanno criticato l’utilità del progetto ai fini della ricerca
accademica, lamentando una scarsa qualità dei dati per quanto riguarda sia
l’accuratezza dei testi digitalizzati che l’affidabilità dei
metadati associati ai testi stessi. In riferimento alla prima versione di Google
Books (rilasciata nel 2009) Nunberg ( ) sosteneva
che il problema fosse così esteso, in particolare per quanto riguarda l’affidabilità
dei metadati, da costituire un disastro
per la ricerca. Altre critiche
riguardano la presenza sproporzionata di testi scientifici, soprattutto nei decenni
più recenti, e la possibilità che determinati autori influenzino in modo troppo
pesante i dati con l’utilizzo di specifiche parole o sintagmi ( : 2). Google Books, di cui è di recente uscita
una nuova versione, sostiene di avere aumentato l’accuratezza dei testi, sia per
quanto riguarda ad esempio la standardizzazione dei caratteri in testi storici (vedi
oltre), sia per quanto riguarda quella dei dati bibliografici. Pur presentando un
margine di errore le cui dimensioni non sembrano essere stimabili, Google
Books rappresenta indubbiamente un enorme contributo alla digitalizzazione
delle conoscenze e un’utile risorsa nell’ambito della nostra ricerca.
Accanto a Google Books, altre grandi banche dati testuali e archivi digitali
di testi storici realizzati da enti bibliotecari pubblici e privati hanno messo a
disposizione dei ricercatori il patrimonio librario di pubblico dominio. Per quanto
riguarda gli Stati Uniti, il consorzio di biblioteche accademiche
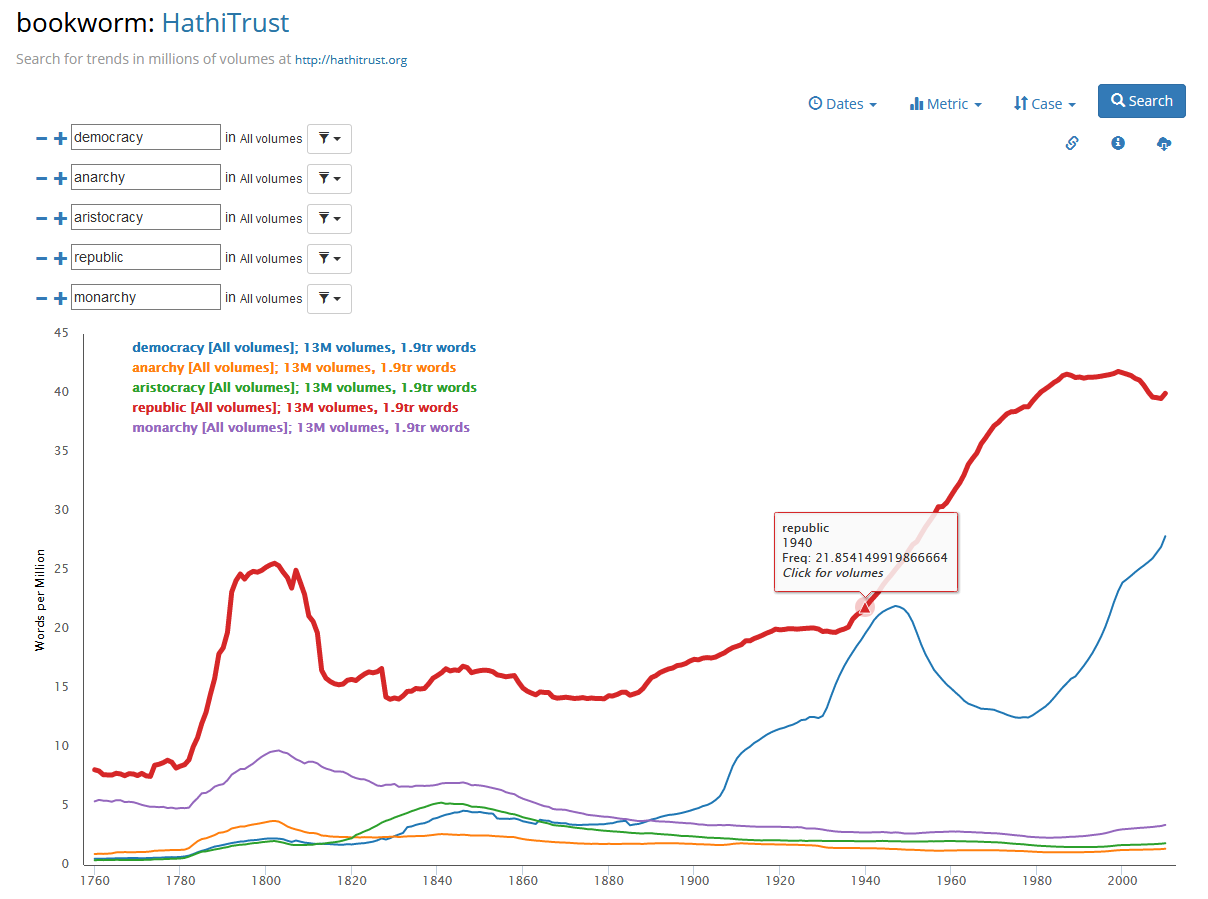
HathiTrust, fondato nel 2008, fornisce accesso a un patrimonio di circa 8,5
milioni di titoli, mentre
Gallica
, un database sviluppato dalla Bibliothèque Nationale de France a partire dal
1997, contiene oltre un milione di titoli pubblicati tra il 1751 e il 2000. Il contenuto di Google Books si sovrappone in parte ai
contenuti di altri archivi digitali (compresa buona parte dei contenuti di
HathiTrust) in quanto questi ultimi hanno aderito al progetto della
multinazionale americana. La British Library, ad esempio, ha in
corso un progetto di digitalizzazione di circa 250.000 libri pubblicati tra il 1700 e
il 1870 ( ), mentre circa un milione di titoli del
patrimonio presente nelle biblioteche nazionali di Roma e Firenze sono gradualmente
inseriti nel database di Google Books a seguito di un accordo, risalente al
2010. Dato che la BnF non aderisce al progetto di Google
Books, la sovrapposizione tra Gallica e quest’ultimo è minore, e si
limita sostanzialmente a testi conservati in altre biblioteche francesi, mentre Google Books contiene anche testi depositati
presso biblioteche in altre aree francofone. Nella nostra ricerca si è visto, ad
esempio, che una parte notevole delle occorrenze di démocratie représentative
provenivano da testi stampati in Svizzera. Il database di Gallica contiene
una frazione considerevole del patrimonio bibliotecario francese; il periodo
quantitativamente più rappresentato nel corpus è quello che va dal 1851 al 1900,
mentre il cinquantennio di nostro interesse (1751-1800) contiene un numero
decisamente minore di testi, rappresentativi però, verosimilmente, di una percentuale
maggiore sul totale dei testi editi in quel periodo.
Per quanto riguarda il patrimonio di libri storici in lingua inglese, una notevole risorsa è costituita dai documenti digitali conservati nell’Oxford Text Archive della Bodleian Library dell’università di Oxford. A differenza di Google Books e delle collezioni presenti nelle biblioteche digitali, che permettono di visualizzare i documenti scannerizzati e di ricercare e scaricare i documenti in formato PDF e spesso anche in formato solo testo, i testi contenuti nell’Oxford Text Archive sono codificati secondo gli standard TEI XML e sono scaricabili individualmente in vari formati, ma non sono ricercabili a testo libero. Un corpus contenente le collezioni Early English Books Online (EEBO) – Phase I (libri stampati tra il 1473 e il 1700), ECCO - Eighteenth Century Collections Online (libri stampati tra il 1701 e il 1800) e Early American Imprints, Series I: Evans (libri stampati in America tra il 1640 e il 1821), per un totale complessivo di circa 33.000 testi (dattiloscritti piuttosto che scannerizzati), è però consultabile sulla piattaforma di servizi lessicografici Sketch Engine (vedi oltre).
Negli ultimi tempi si registra lo sviluppo di progetti relativi alla digitalizzazione di un altro tipo di documenti storici, ovvero le pubblicazioni periodiche. Il progetto Chronicling America della Library of Congress di Washington fornisce l’accesso a un corpus di giornali storici americani contenente oltre 2,5 milioni di copie da oltre 3.400 diversi quotidiani pubblicati negli Stati Uniti tra il 1777 e il 1963. The British Newspaper Archive è un progetto che prevede la digitalizzazione della collezione di quotidiani della British Library, il cui corpo centrale è costituito da giornali pubblicati principalmente nel XIX secolo, ma contenente anche documenti pubblicati a partire dal 1700 e fino al 1950. Alla fine del 2020 il corpus consisteva in oltre 40 milioni di pagine. Un'altra importante risorsa è costituita dalla collezione di quotidiani storici Retronews, creata dalla Bibliothèque Nationale de France e contenente la digitalizzazione di circa 1000 periodici pubblicati tra il 1631 e il 1950. L’accesso a Chronicling America è gratuito, mentre The British Newspaper Archive e Retronews sono accessibili dietro pagamento di una sottoscrizione mensile.
A conclusione di questa rassegna, citiamo alcune importanti banche dati e archivi digitali accessibili online che contengono pubblicazioni nel pubblico dominio, ovvero il Project Gutenberg, l’Internet Archive, il Corpus of Historical American English ed Europeana. Queste iniziative non sono risultate utili alla nostra ricerca per diversi motivi: il Project Gutenberg, progetto precursore iniziato nel 1971 all’alba di Internet, attualmente ospita oltre 60.000 testi, la maggior parte dei quali in formato solo testo e relativi alla lingua inglese. I testi contenuti in Project Gutenberg non contengono però metadati ( ) e non è possibile limitare la ricerca a determinati periodi. L’Internet Archive, un progetto no-profit iniziato nel 1996 con lo scopo di conservare siti e altri materiali pubblicati su Internet, dal 2005 ha iniziato a digitalizzare libri e altri documenti. All’inizio del 2021 il sito conteneva oltre 5 milioni di testi, di cui solo una piccola parte (apparentemente circa 130.000 documenti) risalenti a prima del XIX secolo. Le ricerche nell’Internet Archive non hanno prodotto dati utili alla nostra ricerca. Il Corpus of Historical American English (COHA), creato da Mark Davies ( ) ed accessibile come parte delle risorse linguistiche messe a disposizione dallo studioso, contiene circa 107.000 testi (oltre 400 milioni di parole) in inglese americano pubblicati tra il 1810 e il 2009, suddivisi per fasce decennali e in 4 componenti, fiction (circa metà del corpus), riviste e quotidiani (a partire dal 1860), e libri di non fiction. Il corpus, interrogabile per fasce temporali e separatamente per ciascuna componente, è annotato linguisticamente e permette elaborate ricerche, anche se nel caso della nostra indagine non è stato utile per via dell'arco cronologico preso in esame. Infine, il progetto Europeana, lanciato nel 2008 dall’Unione Europea con il proposito di costruire un’infrastruttura di rete che colleghi il patrimonio culturale conservato nelle biblioteche nazionali europee. Il progetto si propone di rendere accessibili attraverso un’unica interfaccia contenuti digitali di oltre 1000 istituzioni europee; tuttavia, l’interfaccia di ricerca di Europeana non permette la ricerca a testo libero, in quanto si basa su un diverso approccio culturale che privilegia l’esplorazione delle collezioni ospitate per temi e argomenti.
Ricerca e analisi dei risultati
Le banche date e gli archivi digitali online contengono riproduzioni digitali di diversi oggetti, testi, suoni e immagini, e l’esplorazione di una biblioteca digitale può essere affascinante e complessa come quella di una biblioteca fisica. Per quanto riguarda la ricerca nei testi storici, soprattutto se riguardante diverse lingue, il ricercatore si deve confrontare con le opportunità e restrizioni offerte dalle diverse risorse consultate, che variano per quanto riguarda l’interfaccia utilizzata e le modalità di visualizzazione e accesso ai dati.
Non è chiaro quanti dei testi pubblicati fino alla fine del XVIII secolo siano
contenuti nei database e negli archivi digitali. Secondo una stima i titoli pubblicati in lingua inglese tra il 1473 e il 1800 ammontano a circa
480.000, il 7% circa dei quali contenuti nelle tre English
Historical Book Collections disponibili presso l’Oxford Text
Archive. È evidente perciò che molti testi contenenti occorrenze di
representative democracy
, anche importanti dal punto di vista
storiografico, potrebbero non essere presenti in nessuno dei database analizzati,
oppure non essere recuperabili in base ai criteri temporali utilizzati. In secondo luogo, è inevitabile che le copie digitali non
restituiscano tutte le occorrenze contenute negli originali cartacei, in quanto il
processo di acquisizione automatizzato dei testi comporta problemi di riconoscimento
dei caratteri (ad esempio la s
in parole come rappresentativa
, che nel
Settecento è spesso visualizzata come f
, parole ed espressioni che vanno a
capo di riga o di pagina, spazi tra le parole, ecc.) e problemi di indicizzazione che
non sempre vengono risolti. È possibile, ad esempio, che una ricerca di
representative democracy
(limitatamente a un determinato arco di tempo)
produca risultati diversi se effettuata su copie digitalizzate dello stesso documento
provenienti però da fonti diverse. Inoltre, è inevitabile che una certa percentuale
di dati sia corrotta cioè, ad esempio, che non tutte le occorrenze del termine
democrazia rappresentativa
presenti nei testi originariamente riprodotti in
formato immagine e/o testuale dalle copie depositate nelle diverse biblioteche e
musei siano richiamate in queste copie digitali. Il fatto che la maggior parte delle
numerose occorrenze infine rinvenute non fossero mai state richiamate all’attenzione
della ricerca storica conferma però sicuramente la validità dell’indagine.
Sia le biblioteche digitali pubbliche come HathiTrust e Gallica che
Google Books permettono di ricercare parole ed espressioni a testo
libero, di accedere ai singoli risultati di una ricerca (in molti casi consentendo di
visualizzare direttamente le singole occorrenze di un’espressione all’interno di un
testo) e di scaricare il testo in formato PDF ricercabile (e in molti casi anche in
formato testo). Essendo state progettate secondo criteri più specificamente
biblioteconomici rispetto a Google Books, HathiTrust e
Gallica permettono ricerche più puntuali e un migliore accesso ai testi e
ai metadati (consentendo ad esempio di scaricare i dati aggregati di una ricerca)
rispetto a Google Books, più ‘fluttuante’ e opaco in termini di accuratezza
e di verifica dell'esatta consistenza del corpus. Il corpus di testi delle
English Historical Book Collections dell’Oxford Text Archive
disponibile su Sketch Engine è invece annotato per lemma e
part-of-speech e l’interfaccia del software di interrogazione permette
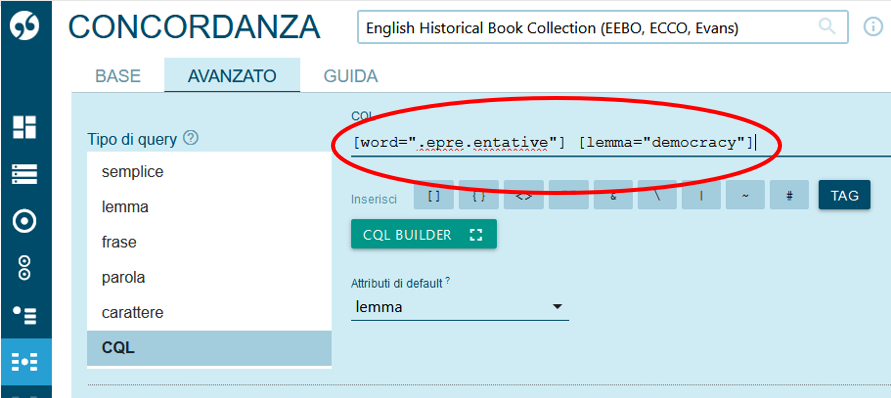
sofisticate ricerche. L’espressione di ricerca evidenziata in Figura 1, ad esempio, è
stata utilizzata per individuare tutte le occorrenze dell’espressione
representative democracy
. La sintassi di ricerca specifica tutte le
occorrenze di representative
inizianti con qualsiasi carattere (allo scopo di
comprendere sia maiuscole che minuscole), che comprendano una s
o qualsiasi
altro carattere (allo scopo di includere anche parole contenenti la s
settecentesca) seguite da tutte le forme del lemma democracy
(cioè in forma
singolare e plurale, contenenti lettere maiuscole o minuscole).
Attraverso le ricerche condotte sulle diverse risorse abbiamo infine individuato
occorrenze del sintagma democrazia rappresentativa
e equivalenti nelle altre
due lingue, per l’arco cronologico 1778-1799, in 43 testi in lingua inglese, in 89 in
lingua francese e in 16 in lingua italiana.
A questo risultato si è arrivati attraverso un considerevole processo di controllo e
scrematura dei risultati delle ricerche, che hanno riguardato tutte le forme
singolari e plurali del termine nelle tre lingue, tenendo conto per quanto possibile
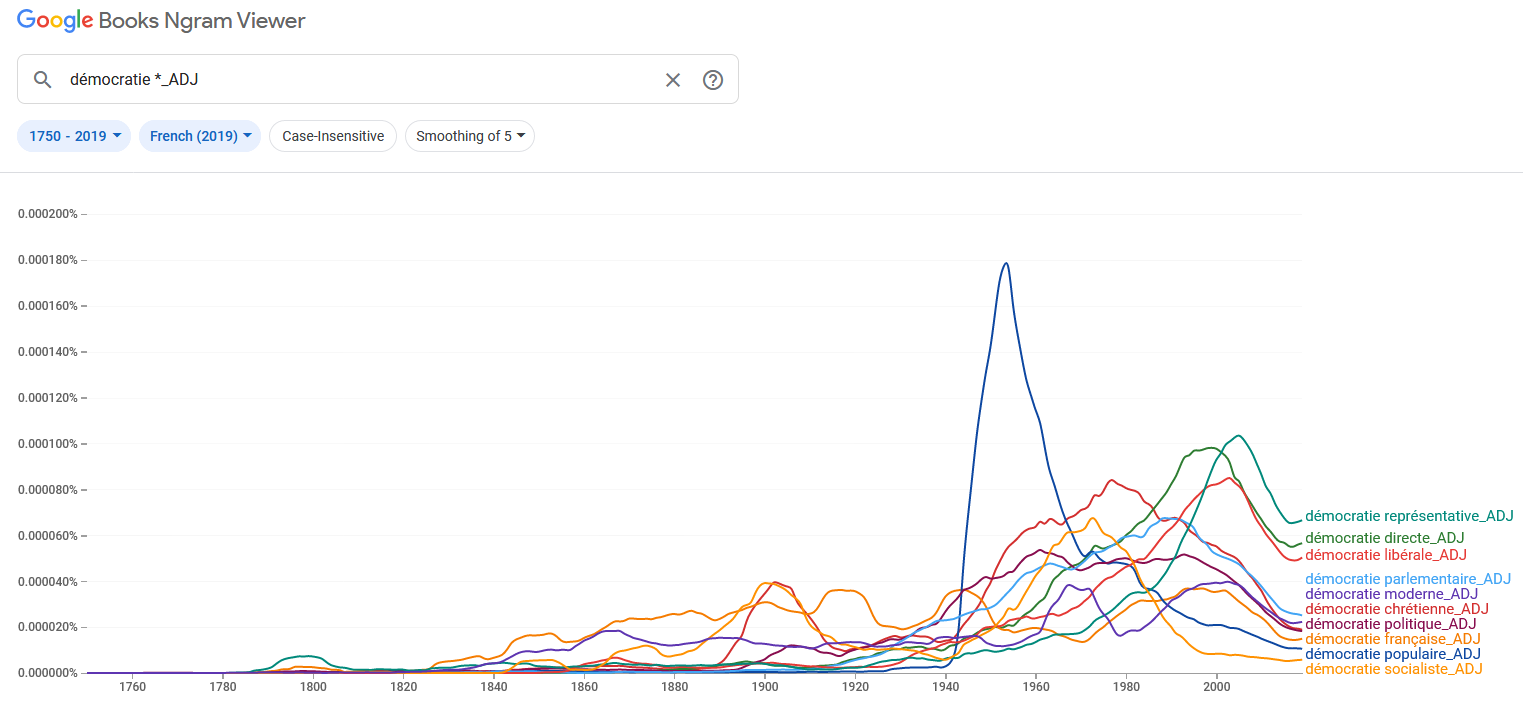
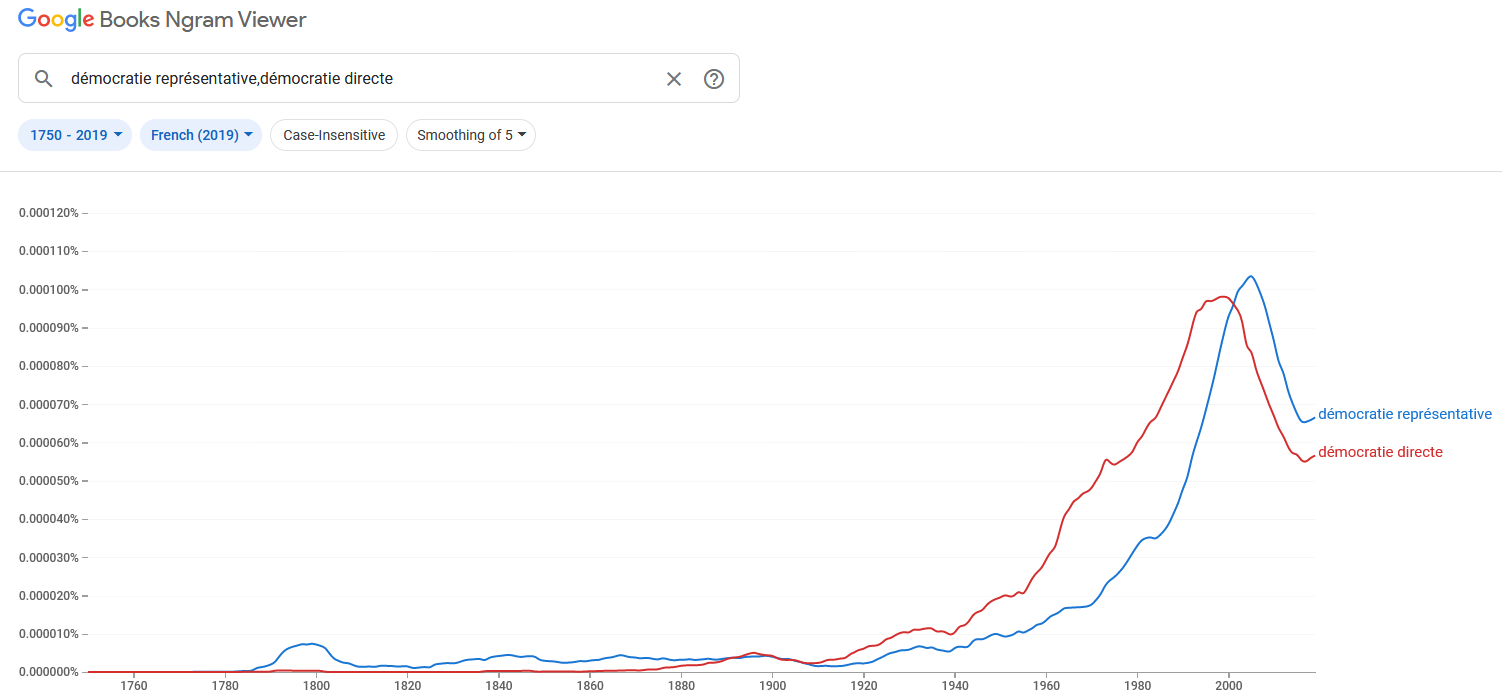
delle diverse grafie. Inoltre, si è operata anche la ricerca di altri termini
(democrazia diretta
, repubblica rappresentativa
ecc.), suggeriti sia
dalla frequentazione e familiarità con i testi dell’epoca sia da evidenze
lessicometriche (vedi sezione successiva). Dato che, a parte per i corpora storici
contenuti in Sketch Engine, i software di ricerca non permettevano ricerche
con espressioni regolari, le stringhe di ricerca utilizzate nelle interfacce delle
diverse risorse hanno generato notevoli sovrapposizioni in termini di risultati. Ad
esempio, occorrenze della forma singolare e plurale possono essere contenute nello
stesso testo. Inoltre, come si è detto i contenuti di database e archivi possono
sovrapporsi, per cui la stessa copia digitale può essere contenuta in vari database,
con uguale o diversa classificazione. La presenza di duplicati si verifica non solo
quando lo stesso libro, proveniente dalla stessa biblioteca, è accessibile da due
interfacce diverse, ma anche quando due interfacce diverse (o anche la stessa
interfaccia) rimandano a copie digitali dello stesso testo a stampa provenienti da
biblioteche diverse. Per quanto riguarda le ricerche condotte su Google
Books, in particolare, va segnalato il fatto che, in molti casi, uno stesso
testo è presente più volte; non solo in diverse, e a volte parecchie, edizioni, ma
anche, in qualche caso, con più copie dello stesso volume digitalizzate da
istituzioni diverse. Si sono verificati, inoltre, alcuni casi in cui un documento
reperito attraverso la ricerca del sintagma nel testo si rivelava, a una più attenta
analisi, non contenere l’espressione cercata; in altri casi non è stato possibile
verificare se il documento la contenesse effettivamente. Nella nostra ricerca abbiamo
incluso nelle analisi successive solo le occorrenze per le quali è stato possibile
reperire il testo completo che le contiene e verificarne il contesto ideologico,
escludendo ad esempio quelle per le quali non era possibile la visualizzazione o era
possibile solo una visualizzazione di frammenti (Google Books
snippet view).
Invece, pur non approfondendole sotto il profilo qualitativo, non abbiamo considerato come falsi positivi le citazioni letterali all'interno di altri contesti testuali di documenti già presi in considerazione (l'esempio più tipico è quello delle recensioni di volumi pubblicate all'interno di periodici), così come le nuove edizioni di testi già analizzati apparse nell'arco cronologico indagato, dal momento che si tratta, in entrambi i casi, di testimonianze significative della circolazione del sintagma.
La consultazione di una così ampia quantità di testi in diverse lingue ci ha permesso
di gettare luce sui diversi significati attribuiti al termine democrazia
rappresentativa
dagli attori sociali dell’epoca in diversi contesti geografici
e culturali. Si è evidenziato, ad esempio, come all'espressione representative
democracy
nel contesto americano fosse spesso preferita la più neutra
republic
, mentre in quello britannico essa fosse utilizzata principalmente
da radicali filo-giacobini e/o in riferimento al contesto rivoluzionario francese.
Démocratie représentative
fu usata in modo sporadico, prima di diventare
notevolmente diffusa nel periodo del Direttorio (1795-1799), in Francia come in
Svizzera; in Italia, il sintagma democrazia rappresentativa
era utilizzato con
una certa frequenza durante il triennio rivoluzionario 1797-1799, con accezione tanto
apprezzativa quanto derogatoria (cfr. ). È ipotizzabile,
quindi, che l'aggettivazione possa aver consentito la riappropriazione in chiave
moderna di un termine – democrazia - identificato con una forma di governo antica e
ritenuta inadatta a Stati di grande estensione territoriale.
Inoltre, si è verificato come, perlomeno in questa fase iniziale, il termine
democrazia rappresentativa
(o meglio, i suoi equivalenti in inglese e
francese) fossero in competizione con altri termini che non attecchiranno, come
démocratie representée
, o scompariranno dall’uso nel corso degli anni, come
representative republic
e come si riscontrassero, prima della sua
affermazione, espressioni alternative come democracy by representation
o
démocratie par représentation
. È interessante infine notare come le
traduzioni di alcuni testi, in particolare dall'inglese al francese ( ; ), e viceversa ( ; ; ; ), possano aver
contribuito all’affermazione del termine democrazia rappresentativa
.