La bontà di essere in corso
L'unica edizione a stampa del Codice Pelavicino risale al 1912 ( ): contiene diversi errori, omette larghe parti del testo e non è certamente in
linea con gli attuali criteri di edizione critica di una fonte medievale. Negli anni ‘40
del XX secolo l’Istituto Storico Italiano per il Medioevo chiese a Geo Pistarino di
procedere con una nuova edizione del Codice, ma il lavoro si trascinò per anni senza
concludersi ( ). Nel 2014 proposi al Capitolo della
cattedrale di Sarzana con il supporto dell'Accademia "G. Capellini" il passaggio a
un'edizione digitale basata su immagini e in progress, da attuarsi per mezzo
del software open source EVT tramite codifica della trascrizione, con accesso
all'immagine digitale del codice, al testo, all'apparato critico e agli strumenti di
corredo ( ). Il lavoro, condotto per
6 anni da un’équipe di lavoro interdisciplinare guidata dalla sottoscritta si è
chiuso
- limitatamente a quanto concerne l’edizione di tutti i 529 documenti
del codice - nel 2020 ( ).
Nel 2014, nello spiegare ai committenti la bontà della proposta, motivammo il passaggio
al digitale puntando soprattutto su ragioni pratiche: insistemmo sul fatto che
l'edizione basata su immagini consentiva l’accesso in sicurezza a una fonte che, per
unicità e preziosità, non poteva essere resa comunemente consultabile; inoltre l'accesso
simultaneo all'immagine facsimile e alla trascrizione, oltre che al regesto e
alle note al testo, avrebbe permesso al lettore un controllo diretto e puntuale sul
lavoro fatto dagli editori e quindi una trasparenza, nel processo di edizione, che la
pubblicazione tradizionale impediva. La seconda ragione che adducemmo era invece
relativa alle tempistiche di edizione. Gli studiosi della Lunigiana medievale
aspettavano da lungo tempo una nuova edizione che però - se condotta nel modo
tradizionale - era assai difficile da programmare. La scelta del digitale avrebbe invece
consentito un’edizione parziale e progressiva dei documenti del Codice, in modo da
fornire il testo in tranche successive. Ricordiamo infatti che il contenuto del
manoscritto non è unitario, ma costituito in gran parte dalla la copia tardo duecentesca
di 529 documenti. L’essere in progress, lungi dal costituire un fattore
negativo e squalificante, avrebbe quindi avuto un duplice e benefico effetto di fornire
rapidamente agli studiosi materiale di loro interesse e contemporaneamente incentivare
gli stessi editori a proseguire il lungo processo di trascrizione e codifica. Un terzo
beneficio - non previsto agli esordi - è derivato dal fatto che proprio la comunicazione
periodica degli obiettivi parziali ha sollecitato il coinvolgimento di altri
ricercatori, accademici e appassionati, che hanno reso il progetto in sé una materia
viva, un’edizione fertile
, come si cercherà di spiegare nella parte finale di
questo articolo.
Per quanto riguarda i criteri e i metodi di edizione agli inizi le idee erano confuse,
in parte anche per il background stesso dei responsabili dell’edizione, in
parte tradizionale
, in parte informatica umanistica
, con ancora scarsa
esperienza nel dialogo reciproco. Intendevamo da un lato appoggiarci ai criteri di
edizione scientifica delle fonti documentarie sopra citati, pur modificati dalla scelta
del supporto, dall’altro procedere a una codifica del testo in XML secondo le linee
guida della TEI P5 e utilizzare uno strumento di edizione che prevedesse la
consultazione contemporanea dell’immagine del manoscritto, della trascrizione del testo,
dell’apparato critico e delle note, oltre che l'accesso a strumenti di corredo
tradizionali.
Per l’edizione basata su immagini (image based edition) si è deciso di usare EVT, un software open source, nato per la visualizzazione Vercelli Book, ma sviluppato per diventare uno strumento adattabile a diversi progetti. L’edizione è stata però affiancata anche da un sito in Wordpress che presenta testi sulla storia e descrizione del codice, sulle peculiarità delle scelte editoriali, sul gruppo di lavoro e su materiali di corredo, in analogia con quanto accadeva nel cartaceo, di norma dotato di una corposa introduzione iniziale e di tabelle in appendice.

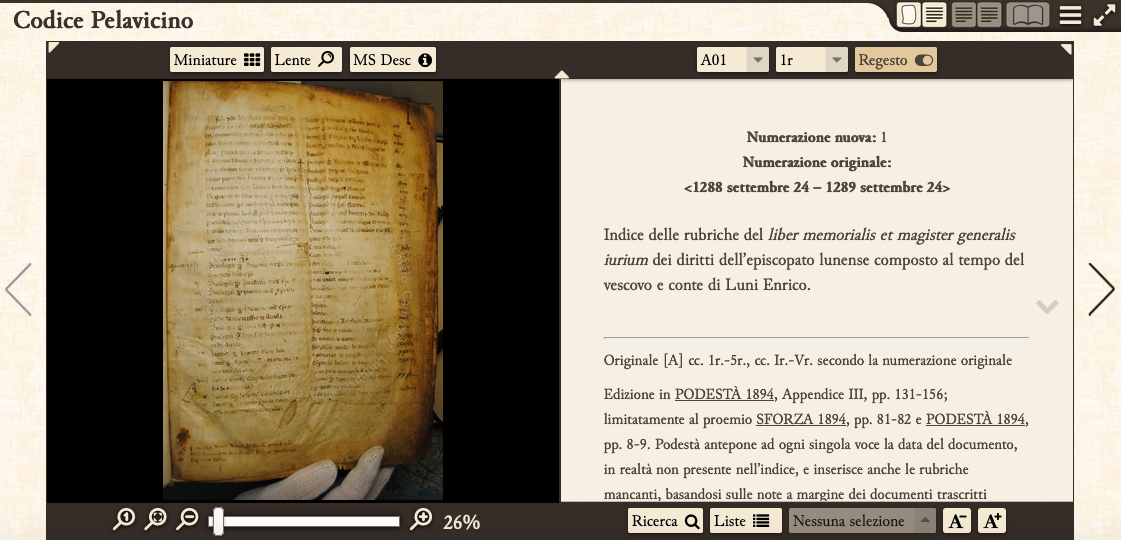
EVT, usato qui nella versione 1.3 (attualmente si sta lavorando alla 3), presentava
infatti alcune caratteristiche molto interessanti. In primo luogo, consentiva di
lavorare sui dati indipendentemente dalle funzionalità fornite dal software per
la loro visualizzazione. In parole povere potevamo concentrarci sulla codifica a
prescindere dall’esito finale: la visualizzazione sarebbe infatti stata poi
personalizzata attraverso fogli di stile CSS. Altro grande pregio riguardava
l’aggiornamento: una volta configurato e inserito il materiale nelle cartelle
appropriate, il lancio
di uno script predisposto consentiva a EVT di
produrre l’edizione in maniera automatica. L’aggiornamento continuo dell’edizione
diventava così un’operazione semplice e ripetibile alla bisogna. Last but not
least EVT 1.3 presentava un ambiente di navigazione estremamente intuitivo per
l’utente finale, facile da usare, con un layout chiaro e una gestione efficace
dello spazio disponibile.
Liste e apparati
Una volta iniziato e predisposto il flusso di lavoro che portava dalla trascrizione
alla codifica, dalla validazione e controllo dell’XML alla pubblicazione, ci siamo
immediatamente resi conto che era possibile arricchire l’edizione tradizionale
con funzionalità nuove. Ad esempio, alla consueta codifica di nomi propri
(antroponimi e toponimi) e date - che oggi nel campo delle DH sono dette Named
Entities - aggiungemmo i mestieri (in realtà voce che comprende anche titoli
come nobilis e uffici come castaldus) e le monete, ma senza
prevedere un trattamento particolare per queste voci. Antroponimi, toponimi e date
(dei documenti) andavano a confluire in apposite liste di consultazione (indici),
mentre tutte le altre entità
, compresi i mestieri e le monete, venivano
evidenziate nel testo con colori diversi per facilitare al lettore l’individuazione e
la lettura. In sostanza la codifica serviva - e serve ancora - solo per aiutare
l’utente nella lettura del singolo documento.

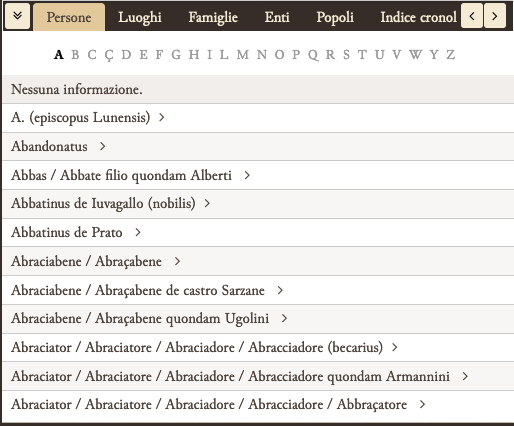
Un altro elemento da noi sottoposto a una codifica peculiare riguardò i signa dei notai redattori o autenticatori, al fine di valorizzare una delle ricchezze del Codice, la riproduzione di decine e decine di signa tabellionum. In questo caso, tuttavia, non riuscimmo a trovare una soluzione totalmente interna a EVT che consentisse una consultazione utile. Su EVT venne semplicemente creato un collegamento che, unendo fra di loro i tag che identificano i signa (<ptr/>) e le riproduzioni dei simboli notarili presenti nelle carte del manoscritto, permetteva una corrispondenza di tipo hot spot, in modo da mostrare il signum ed eventuali informazioni aggiuntive.
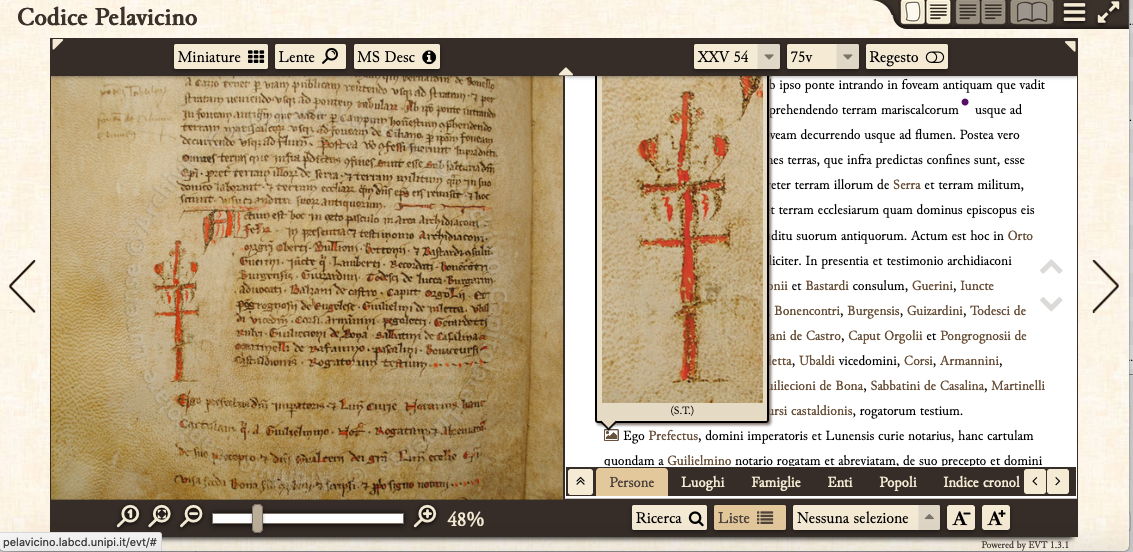
In aggiunta venne deciso anche di sviluppare, sul sito, una pagina HTML con l’indice di tutti i notai e i rispettivi signa, in modo da fornire agli utenti un ulteriore strumento per la consultazione. Attraverso le regole di trasformazione XSLT, applicate alla lista XML delle persone e dei signa, è stato possibile creare un unico documento da poter integrare nel tema Wordpress del sito web ( ) che desse conto del nome del notaio, di quanto si conosceva del suo periodo di attività e dei signa che lo caratterizzano nel codice.
Come è facilmente intuibile, la soluzione adottata per i signa, aveva già
fatto emergere fin dal 2014 il nodo relativo al trattamento dei dati presenti nel
Codice. Per i notai, infatti, si era reso necessario separare l’area dell’edizione
vera e propria
dotata di alcuni strumenti di corredo (EVT), dall’area in
cui alcuni dati codificati potevano essere trattati in maniera diversa (il sito).
Precisiamo che la soluzione individuata ci appare oggi ancora valida e funzionale -
dato che è possibile visualizzare in maniera semplice i simboli / disegni usati nei
signa e la loro datazione, ma anche lontana dall’essere ottimale, in
quanto non consente di estrapolare in maniera automatica i dati. In sostanza il
ricercatore non ha a disposizione un’interfaccia per scoprire quali notai abbiano
rogato in un delta temporale o quali qualifiche esprimano nell’escatocollo al variare
degli anni o ancora per distinguere - sempre in maniera automatica - tra notai
roganti e notai autenticanti.
Navigare nel tempo
Il problema si è riproposto, più o meno nei soliti termini, per altri aspetti, essenziali alla ricerca storica, che emergevano a mano a mano che l’edizione avanzava.
Per le date, ad esempio, è stato predisposto un indice cronologico ascendente e discendente, che però è agganciato al solo tag <docDate>, ossia alla data topica e cronica di ogni singolo documento, e non alle altre date presenti all’interno dei singoli testi. Questa limitazione sottrae di fatto al lettore una parte importante dell’informazione, quali ad esempio la citazione interna di documenti anteriori o, come è già stato rivelato da uno studio specifico, la presenza di autenticazioni e soprattutto di passaggi in mundum da scheda notarile attuati in date e in periodi peculiari ( ). In un primo momento si è pensato di trattare questi eventi allo stesso modo delle named entities, ossia creando una nuova lista nell’intestazione del file principale e utilizzando l’elemento <listEvent>, che permetteva di definire un elenco di descrizioni su tipologie di eventi. Purtroppo, questa soluzione, considerate le caratteristiche dei documenti e il tipo di eventi da trattare, non è stata percorribile per le difficoltà incontrate nel definire un’ontologia di eventi: in alcuni casi la tipologia è infatti chiara, in altri invece è problematica, in altri ancora estremamente difficile, al punto da costringere l’editore a una vera e propria forzatura del testo.
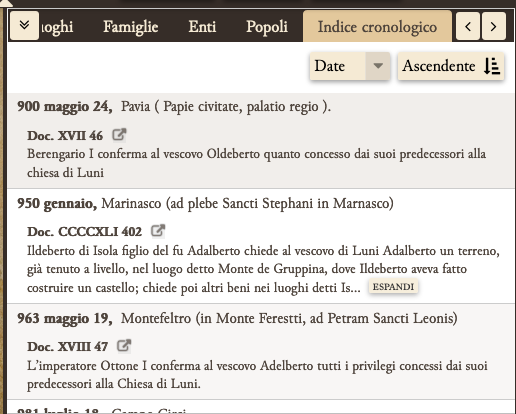
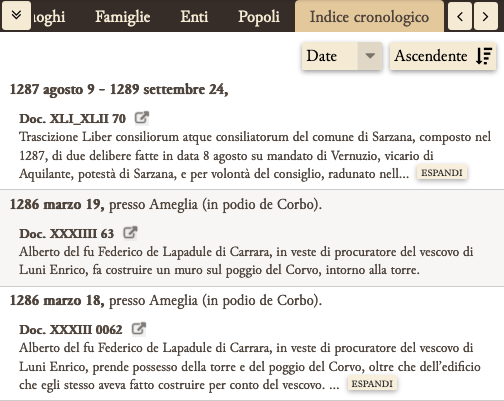
Per ovviare al problema abbiamo distinto gli eventi tra quelli che avevano una data chiaramente espressa e quelli che potevano essere datati da elementi relativi interni e poi abbiamo descritto le caratteristiche dell'evento entro un semplice tag <note>, messo in relazione con il tag <date>. Per quanto riguarda gli eventi riconoscibili nei passaggi in mundum e nelle autentiche, nonostante la codifica non prevedesse la marcatura delle diverse parti del documento, abbiamo deciso di dare una <div> specifica alla parte dell’escatocollo contente tali eventi, in modo da poterli poi efficacemente pubblicare in modo automatico, nel sito dell’edizione, da un plugin di Wordpress (TimelineJS) per la creazione di timeline.

Nella timeline del Codice Pelavicino è così possibile consultare i diversi
eventi espressi nel manoscritto - ovviamente se correttamente marcati -, evidenziando
anche la tipologia dell’evento di appartenenza tra documento
, mundum
,
autentica
ed evento
generico ( ). La
navigazione in questa freccia del tempo negli eventi, e soprattutto nelle diverse
tradizioni del documento, può diventare uno strumento ermeneutico per l'editore e
rappresentare un servizio aggiuntivo che solo l'edizione digitale può offrire al suo
pubblico specialistico. Anche in questo caso, però, come per i notai, la separazione
dello strumento di corredo dall’edizione al sito è stata necessaria, per consentire
una consultazione altrimenti impossibile o estremamente complicata interna a EVT.
Analogamente avvertiamo che non è possibile ricercare ed elaborare in tempo reale i
dati marcati, come, ad esempio, recuperare in forma tabellare i documenti che hanno
avuto un passaggio in mundum a più di 10 anni dalla redazione del documento
originale o quali documenti sono stati autenticati dopo la morte di Federico II.
Questione di scelte
Va da sé che il problema si sta replicando, mutatis mutandis, per molti altri elementi del testo che vorremmo valorizzare e rendere fruibili al lettore - l’appetito vien mangiando -, alcuni già marcati (come mestieri e monete), altri ancora da marcare, come ad esempio i censi.
I mestieri, per ora codificati con un semplice <roleName> ed evidenziabili in indaco nella lettura su EVT, potrebbero ad esempio essere gestiti all’interno di un glossario terminologico, la cui creazione è in fase sperimentale, ma che - di nuovo - ha trovato una sua prima collocazione entro il sito, e non in EVT.

Per la codifica delle monete è stato adattato il tag TEI <measure>, genericamente usato per qualsiasi unità di misura e per i quali sono previsti tre eventuali attributi: @type, nel nostro caso utilizzato per descrivere l’autorità emittente / tipologia (imperiales, Ianuenses, Parmense ecc.), @quantity, che contiene la quantità espressa in cifre arabe e @unit, che informa circa il nominale nelle cinque possibili casistiche riscontrate: denarius, solidus, mezanus, marca e libra. Anche in questo caso la marcatura attualmente consente solo di evidenziare la moneta e di restituirne le caratteristiche in pop up in maniera standardizzata.

Si tratta, com'è evidente dalla , di un servizio utile alla lettura, ma totalmente ininfluente a livello di trattamento dei dati, in quanto non è attualmente possibile sapere ad esempio, quale fosse l’ammontare medio di un canone per abitazione o per terreno agricolo col variare del tempo, e nemmeno avere un dato numerico accorpato per pagamenti fatti con nominali diversi. Tuttavia, i dati dei pagamenti (in particolare vendite e canoni) - come si intuisce dall’esempio proposto - presentano già una forma semi-strutturata. Le liste di censi, ad esempio, abbondanti nel codice, presentano dati più o meno costanti: il nome dei locatari (con varie denominazioni relativamente alla condizione e all’epoca), la posizione / nome del podere / tenuta / bene, l’ammontare del censo in natura, in moneta o misto. La caratteristica semi-strutturata di questi dati emerge dalla stessa scrittura delle liste nel codice, in quanto talvolta sono trascritte in forma tabellare oppure è evidente che erano espresse in forma tabellare nell’antigrafo.


Il problema a questo punto è aperto. Che si tratti di dati fondamentali per lo studio della Lunigiana medievale è palese. Altrettanto evidente è che, proprio la loro natura di dati semi-strutturati li renderebbe idonei a un trattamento che consenta la loro elaborazione in database con possibilità di valutare in termini numerici costi, valute, quantità, misure.
Ma quale soluzione adottare? La scelta iniziale - uno dei pregi di EVT - di operare
la codifica del testo senza pensare alla visualizzazione del dato è una strada ancora
percorribile? O si deve pensare a una codifica personalizzata
e finalizzata
appunto a rendere i dati computabili? Si deve pensare a un output interno
all’edizione o è meglio mantenere questi servizi di query sul sito, al di
fuori dall’edizione vera e propria? E ancora cosa marcare? Solo i dati che presentano
caratteristiche idonee a un simile trattamento (censi) o anche contenuti più
scomposti (transazioni in moneta)?
Sono domande che richiedono indubbiamente una risposta tecnica, un software idoneo e
una scelta di codifica che restituiscano al lettore ricercatore quanto desidera nella
collocazione più appropriata. Ma a monte spingono questioni che toccano problematiche
più ampie riguardanti il significato e l’utilità dell’edizione di una fonte storica,
i ruoli e le competenze degli editori, il differente approccio al testo tra filologi
e storici ( ) e il pubblico che si vuole raggiungere.
Personalmente ritengo che, per individuare possibili risposte, sia indispensabile
tenere in maggior considerazione l’ultimo fattore che era certamente ritenuto
secondario nelle edizioni cartacee tradizionali: il pubblico, anzi i
pubblici.
Se il Codice diventa un post
Sappiamo perfettamente che l’edizione di una fonte storica di qualsiasi genere può interessare diverse categorie di utenti e se avviene sul Web l’accesso è teoricamente universale. Sappiamo altrettanto bene però che tale universalità è limitata da diversi fattori quali il digital divide, la lingua, la complessità dei contenuti proposti, l’interfaccia di navigazione.
In molti casi, l’operazione culturale che soggiace all’edizione digitale di una fonte
o di un corpus di fonti tende a diventare autoreferenziale e di conseguenza
povera di pubblico. Sovente è infatti spesso lo stesso editore ricercatore (o il
gruppo di ricerca) che, conoscendo perfettamente la sua fonte, crea un ambiente di
consultazione unico, specifico e complesso, che risulta di conseguenza anche elitario
e chiuso. Spesso in questa tipologia di edizioni le possibilità di ricerca interna
sono estremamente raffinate e di altissima qualità, ma restituiscono risultati
interessanti solo per pochi, con interfacce di navigazione complesse, che necessitano
una formazione propedeutica. Da un altro punto di vista, un’edizione troppo
semplice
, dotata di pochi, essenziali, strumenti di corredo, restituisce
agli studiosi - come abbiamo visto - solo una minima parte dei contenuti che in
realtà il testo potrebbe dare.
Senza arrivare a una progettazione completamente centrata sull'utente (UCD, User Centered Design), credo che porsi il problema delle principali categorie di utenza a cui l’edizione si rivolge o si potrebbe potenzialmente rivolgere, risulterebbe estremamente per cercare una o più soluzioni alle domande prima enucleate.
Sempre partendo come esempio dal Codice Pelavicino proviamo quindi a disegnare tre tipologie plausibili di utenti: l’appassionato di storia locale (ma anche insegnanti di scuola), lo storico di professione, il ricercatore di altre discipline umanistiche.
Il primo utente mediamente non conosce il latino, ma non ne è nemmeno spaventato al
punto da non avvicinarsi alla trascrizione di un documento medievale: gli interessa
la storia locale, quella dei posti dove vive, e quindi è abituato a leggere saggi
storici di diverso livello qualitativo, oltre alle mappe, storiche o contemporanee
che siano. L’edizione digitale del Codice Pelavicino si è rivolta a questa tipologia
di utenti fin dall’inizio e l’ha raggiunta con discreto successo grazie, in primo
luogo, all’interfaccia di EVT e, in secondo, alla promozione dell’iniziativa su
diversi canali comunicativi. Nel software di edizione la navigazione tra i
documenti è possibile da più punti di accesso: la carta, il singolo documento, gli
indici e il motore di ricerca per stringa di caratteri. Il passaggio dall’apparato
critico in italiano (data, regesto, edizioni, note) alla trascrizione in latino con
note al testo è semplice e la navigazione è facilitata dall’organizzazione intuitiva
e razionale degli spazi, oltre che dalla possibilità di evidenziare alcune named
entities. Questa semplicità
di fondo è centrale e non deve essere
sacrificata a favore dell’ampliamento eccessivo delle tipologie di esplorazione.
Nell'equilibrio sempre delicato tra possibilità di ricerca e complessità della
maschera, la scelta deve a mio avviso sempre prediligere la semplicità e
l’intuitività della navigazione.
Il coinvolgimento degli appassionati di storia locale è stato raggiunto - come accennato - anche tramite altre modalità: la costruzione del sito come un blog, con pubblicazione periodica delle novità inviate anche tramite newsletter e l’invito ben formulato, nel sito stesso, a partecipare all’edizione. Lungi da diventare indice di debolezza scientifica o di imprecisione degli editori, l’aggiornamento tramite blog / newsletter non solo sui progressi fatti, ma anche e soprattutto sui problemi incontrati nella codifica, sui dubbi di lettura e sulla necessità di un controllo, ha di fatto coinvolto il pubblico dei non addetti ai lavori a livelli non prevedibili. Attualmente la casella di posta elettronica in cui sono stati immagazzinati i commenti del pubblico ammonta a circa 500 unità.
In un secondo tempo, abbiamo provato ad allargare ulteriormente la platea degli
utenti ricorrendo a Facebook, social ritenuto idoneo perché frequentato per di più da
ultraquarantenni e perché vi si trovano gruppi interessati alla storia della
Lunigiana. Su questi gruppi sono state quindi postate
comunicazioni generiche,
come l'annuncio della pubblicazione di nuovi documenti, e specifiche, quali richieste
d'aiuto per l'individuazione di termini e toponimi. La risposta del pubblico è stata
estremamente positiva: da un lato i contributi raccolti sono risultati mediamente di
ottimo livello e hanno portato miglioramenti all'edizione, dall'altro l'edizione in
sé è stata oggetto di scambi autonomi e di discussione all'interno del social,
portando di fatto alla promozione e alla disseminazione del prodotto culturale.
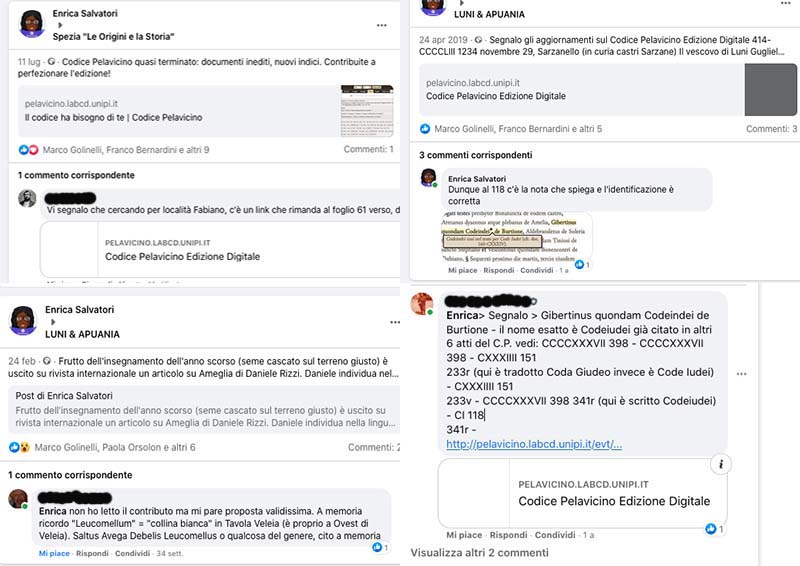
L'insieme di questa attività di comunicazione, che combina la semplicità dell'interfaccia utente, in EVT e sul sito, con diversi canali di comunicazione, di fatto configura il Codice Pelavicino Edizione Digitale come un progetto di digital public history, in quanto presenta un prodotto culturale legato alla nostra storia, pensato appositamente per favorire la partecipazione attiva del pubblico ( ; ; ). Comporta tuttavia anche conseguenze di non poco conto: i lettori partecipano, ma solo a patto di ricevere una qualsivoglia ricompensa, nel nostro caso attenzione, considerazione, rispetto. Questo si traduce, nel concreto, in un notevole aggravio del lavoro di edizione, in parte dedicato a considerare tutte le osservazioni, rispondere, correggere o implementare l’edizione grazie ai suggerimenti pervenuti, riconoscendo contemporaneamente la paternità del suggerimento. Se si guarda ad esempio ai toponimi, solo l’interazione con questo tipo di pubblico ha permesso di individuare la posizione del 30% dei micro-toponimi attestati, a fronte ovviamente di un’opera continua di interazione, controllo e correzione. Un lavoro che, se continuerà negli anni futuri, tenderà a trasformare il Codice Pelavicino in una never ending edition, sempre aggiornata, ma anche costantemente fluida .
La seconda tipologia di utente a cui conviene pensare, relativamente al Codice Pelavicino, è lo storico, che - come già ampiamente spiegato nel corpo dell’articolo - è interessato a estrarre dati dalla fonte e contemporaneamente vederli nel loro contesto. Di fronte al Codice Pelavicino il medievista si porrà quindi domande tutte caratterizzate dalla variabile temporale con oggetti diversi. Prendendo ad esempio le liste dei censi, che elencano dati già semi-strutturati, un loro trattamento potrebbe poterci dire a quanto ammontavano le rendite dei beni vescovili e come erano distribuite, quali erano i luoghi e le date di raccolta dei censi, quale era il valore medio degli affitti dei terreni a uso agricolo nelle vicinanze di un luogo e qual era il rapporto tra censo in moneta e censo in natura .
È chiaro che queste fonti sono interessanti soprattutto per indagini di tipo economico-insediativo, ma si potrebbero ovviamente valutare anche altri aspetti, come la percentuale di eredi di un locatario defunto rispetto alla presenza di tenutari e tenutarie espressamente nominati. Uno storico del paesaggio riterrebbe inoltre di estrema utilità che i toponimi fossero categorizzati per categorie (idro-, geo-, fito-, zoo-, antro-, agio- toponimi, nomi relativi all’uso del suolo, alle attività produttive e alle forme di popolamento e alla viabilità) e geo-referenziati in modo da poterli visualizzare in mappa, magari anche in layer sovrapponibili.
La risposta alla ineludibile moltiplicazione delle domande credo debba essere duplice: da un lato l’assunzione di responsabilità dell’editore, dall’altro l’apertura dei dati.
Riguardo alla prima istanza credo che chi cura l’edizione scientifica digitale di una fonte e che quindi ne conosce bene struttura e potenzialità debba, banalmente, scegliere quali funzioni di ricerca mettere a disposizione tra quelle più promettenti, anche e soprattutto in relazione alla trattabilità dei dati. Di fronte alla grande varietà delle possibilità di ricerca credo che si debba innanzitutto abbandonare da subito, concettualmente, la possibilità di accontentare tutte le esigenze.
Una simile scelta è stata fatta ad esempio da Andrea Nanetti ( ) per l’edizione del privilegio Religiosam vitam di papa Gregorio X per il Monte Sinai (1274) collocato in uno spazio partizionato e interattivo che consente di leggere il documento dai punti di vista dello storico e del diplomatista, esplorare con un video e un grafico ad albero il suo tenor formularis; consultare diritti e patrimonio del monastero con servizi di localizzazione e visualizzazione di voci di Wikipedia. Si tratta di un rilevante numero di servizi, che non ha alcuna pretesa di essere esaustivo e che però appare idoneo a trattare un solo documento alla volta, almeno nella formula della image based edition.
La scelta dei servizi deve poi avvenire - come già sottolineato - preservando il più possibile la semplicità e l’intuitività della navigazione. Questa esigenza ha per ora prodotto nel Codice Pelavicino lo sdoppiamento dei luoghi di pubblicazione; strada scelta anche per l’edizione critica digitale collaborativa dei documenti dell’abbazia di S. Maria della Grotta (da qui SMG) che attualmente consta di tre versioni: l’edizione digitale nativa su monasterium.net; il PDF dei soli testi, generati con una trasformazione dedicata; l’edizione cartacea in open access .
La problematica più rilevante di queste scelte polimorfe non risiede nell’apparente
confusione dei piani - basta infatti una buona strutturazione delle informazioni
nella pagina principale dell’edizione per ovviare all’impasse - ma nel fatto
che il continuo (inevitabile e anche auspicabile) aggiornamento dell’edizione debba
portare ad una modifica in tempo reale e contemporanea di tutte le sue
manifestazioni
. In ogni caso rileviamo come le edizioni del Codice
Pelavicino e di SMG non presentino attualmente strumenti di ricerca dei dati
semi-strutturati.
L’apertura dei dati sembra, infine, essere l’unica risposta logica alla moltiplicazione delle domande che potrebbe porre uno storico e, con lui, la terza categoria di utente, il ricercatore delle scienze umane.
Prendendo sempre come riferimento il Codice Pelavicino, un linguista troverebbe più interessante analizzare statisticamente l’uso dei termini che indicano le diverse tipologie di censi, le misure delle merci, le monete in relazione alle forme antroponimiche o ancora la traccia di espressioni volgari o l’uso di lettere per produrre particolari fonemi. Un diplomatista troverà invece manchevole il fatto che i 529 documenti del codice non siano classificati per tipologia (lista di censo, memoria, diploma, instrumentum venditionis ecc.) e che la loro struttura interna (protocollo, testo ed escatocollo) non sia stata codificata opportunamente in modo da estrapolare forme diverse - ad esempio - di invocatio. Uno storico del diritto troverebbe viceversa estremamente utile ritrovare in tempo reale le citazioni - e sono numerose - di testi del diritto canonico e del diritto civile sparsi nelle sentenze copiate nel manoscritto.
Se accettiamo il fatto che non si possono estrarre tutti i dati possibili e non si possono prevedere tutte le forme di interrogazione di una fonte, quello che è possibile e doveroso fare è consentire agli studiosi la possibilità di elaborare autonomamente la fonte stessa.
L'edizione digitale del Codice Pelavicino è formata da 529 file XML corrispondenti ad
altrettanti documenti del codice, raggruppati in un file master e collegati
a un file bibliografia, entrambi in XML. A prescindere dal sistema di
pubblicazione scelto, questi materiali possono essere banalmente resi disponibili,
scaricabili dal sito, in modo che altri studiosi possano procedere - se lo desiderano
- a cambiare, implementare, correggere la codifica proposta al fine di condurre
ricerche peculiari. A questo fine si potrebbe addirittura sfruttare la strutturazione
doppia dell’edizione - EVT e sito - in modo che l'image based edition
mantenga la versione dell’editore, mentre il sito sia più aperto a contributi esterni
e ospiti o dia conto, via via, delle ricerche condotte anche da altri studiosi sulla
medesima materia grezza
.
Si tratta di una soluzione semplice, già praticata da SMG, che però non è ancora particolarmente praticata nel mondo delle scienze umane: in buona parte perché richiede un rilevante mutamento di mentalità nella comunità scientifica di riferimento e in parte perché manchiamo ancora una infrastruttura che garantisca l'ospitalità dei dati secondo i principi FAIR (findable, accessible, interoperable, reusable) idonea alle peculiarità delle ricerche in ambito umanistico .