3. A comparative error analysis between DeepL and Yandex
In order to compare the effectiveness and reliability of DeepL and Yandex, we perform a manual comparative error analysis of the translations provided by the two Machine Translation tools. We detect the errors committed by the two translation tools and provide a brief linguistic analysis. Moreover, each error is marked as belonging to one or more of the error categories that are listed above. A universal approach to the problem of properly setting error analysis has not been implemented yet and different scholars proposed their own error typology. A significant step towards error analysis standardization has been carried out with the implementation of the Multidimensional Quality Metrics (MQM) by the German Research Centre for Artificial Intelligence (DFKI) from 2012 to 2014 ( ). When setting the comparative error analysis discussed in the present paper, we decided to refer to MQM with regard to its tree structure, as well as some of its specific error categories. Indeed, we have selected a number of error categories of the MQM model and developed other specific ones according to the linguistic features of the texts and the language pair under examination. In particular, we added Theme-rheme pattern category, as well as Untranslated elements and Transliteration subcategories. Moreover, some primary error categories branch into one or more subcategories, which constitute more specific types of issues that fall within a certain error category.
- Grammar
- Syntax
- Use of the articles
- Lexis
- Acronym
- Terminology
- Domain-specific terms
- Culture-specific references
- Theme-rheme pattern
- Accuracy
- Omission
- Untranslated elements
- Consistency
- Orthography
- Spelling
- Capitalization
- Transliteration
- Format
3.1 Dataset
For the purposes of our research, we have selected and translated from Russian into Italian three highly specialized and three popular-science medical texts. The titles of the selected texts, along with the number of translated words for each text, are listed below:
-
Ведение детей с заболеванием, вызванным новой коронавирусной инфекцией (SARS-CoV-2) (133 words) ( )
-
Коронавирус SARS-Cov 2: сложности патогенеза, поиски вакцин и будущие пандемии (197 words) ( )
Moreover, the following three Russian popular-science texts have been selected:
3.2 Qualitative analysis of the results
Once we marked all the errors, two tables have been compiled to provide a visual overview of the quality of the translations provided by the two translation tools. For the mentioned table to be easily readable and understandable to the intended readers, it has been divided according to the translation tool and the text type that is displayed. Therefore, a total of four tables has been inserted. Each table shows how the erroneous fragments are displayed in the source document, in the provided translations, and a specifically made human translation, used as reference translation. Each erroneous fragment has been further associated with one or more of the above-mentioned error categories and then summed according to the error category within which it falls. A number of example relevant translation errors along with their corresponding error categories have been listed and briefly commented in the following lines, with the aim of providing a deeper understanding of the methods of our comparative error analysis as well as DeepL’s and Yandex’s strengths and weaknesses. For a better understanding of the contextual information, the fragments of the original text containing the translation errors under examination have been inserted at the beginning of each subsection, and the portion of text analysed highlighted in bold and reported in the corresponding table.
3.2.1 Grammar - Syntax
При сравнении этих данных со статистикой по другим странам обращает на себя внимание и вызывает неизбежные вопросы исключительно низкий уровень летальности от коронавируса в России ( ).
|
Original document |
Yandex’s translation |
Human translation |
|
обращает на себя внимание и вызывает неизбежные вопросы исключительно низкий уровень летальности от коронавируса в России. |
richiama l'attenzione e solleva questioni inevitabili eccezionalmente basso tasso di mortalità da coronavirus in Russia. |
attira l'attenzione e solleva inevitabili domande il tasso di mortalità estremamente basso da coronavirus in Russia. |
The sentence under examination provides an interesting starting point for discussion as Yandex’s version does not result in compliance with Italian grammatical rules, especially with regard to its erroneous word order. Indeed, the main verb of the sentence and its subject are not only displayed in an order that does not respect Italian grammatical rules, according to which the verb, except for in some special cases, usually follows the corresponding subject, but they are also completely disconnected from one another (Treccani, 2020). This undoubtedly contributes to distorting the meaning of the whole translation variant and preventing it from being acceptable.
3.2.2 Grammar - Use of the articles
Актуальность. Вакцина против коронавируса SARS-Cov-2 рассматривается как наиболее перспективное средство для укрощения вызванной им нынешней пандемии и воспрепятствования возникновению новой ( ).
|
Original document |
Yandex’s translation |
Human translation |
|
Вакцина против коронавируса |
Il vaccino contro il coronavirus |
Un vaccino contro il coronavirus |
The Russian term Вакцина and consequently its Italian equivalent vaccino denote a non-specific and still theoretical entity. In other words, since a vaccine against coronavirus had not been developed yet when the article under examination was written, the name describing it refers to a general concept, i.e. the fact that only a vaccine may restrain the existing pandemic to exacerbate and prevent the emergence of a new one. As a result, an indefinite article would more appropriately contribute to conveying the original grade of definiteness meaning ( ).
3.2.3 Lexis
Ведение детей с заболеванием, вызванным новой коронавирусной инфекцией (SARS-CoV-2) ( ).
|
Original document |
DeepL’s translation |
Human translation |
|
Ведение детей |
Conduzione di bambini |
Gestione dei bambini |
The Russian term ведение is translated with the Italian noun conduzione. Although it can be considered as a possible translation variant for the Russian term under examination (academic.ru), gestione more frequently comes in association with the Italian term bambini (Tiberii, 2018), i.e., the proper translation of the Russian term детей, and perfectly suits the specific context of the source text. This example undoubtedly confirms that the ability of a Machine Translation Tool in properly rendering contextual information plays a major role in the assessment of the quality of the translation tool itself.
3.2.4 Acronyms
В обзоре отражены последние рекомендации международных ассоциаций/консенсусов и наблюдения врачей различных специальностей по вопросу прерывания/продолжения терапии ГИБП с оценкой последствий в случае прерывания биологической терапии ( ).
|
Original document |
Yandex’s translation |
Human translation |
|
ГИБП |
GIBP |
della terapia dei preparati biologici geneticamente modificati |
The Russian acronym ГИБП, which stands for генно-инженерные биологические препараты ( ), and can be translated into English as genetically engineered biological products, is translated with its transliteration, namely GIBP. Although it does adhere to the transliteration rules, since no equivalents can be found neither in Italian nor in English scientific literature, it cannot be considered a correct translation equivalent. A good variant could be instead the translation into Italian of all the words that constitute the Russian acronym.
3.2.5 Culture-specific references
Исследовательская группа из Высшей школы экономики и Сколтеха, совместно со специалистами НИИ гриппа им. А.А. Смородинцева в Санкт Петербурге и ИППИ им. А.А. Харкевича РАН установили, что коронавирус SARS-CoV 2 независимо проникал на территорию России не менее 67 раз, главным образом в конце февраля и начале марта 2020 года ( ).
|
Original document |
DeepL’s translation |
Human translation |
|
ИППИ им. А.А. Харкевича РАН |
dell'A.A. Kharkevich IPPI RAS |
dell’Istituto delle questioni di trasmissione dell’informazione A.A. Harkevič Rossijskaja Akademija Nauk |
The translation tool totally fails in properly rendering the Russian acronyms ИППИ and РАН, which stand for Институт Проблем Передачи Информации and Российская Академия Наук. Indeed, neither Italian nor English equivalents for DeepL’s translation version can be found. In this case, the English noun that appears on the institute’s website (iitp.ru/en/about) as well as a translation into Italian of each word constituting the acronyms may represent good translation options. Moreover, in the translation versions, not only the acronyms but also the Russian proper noun Харкевича are inappropriately transliterated. Indeed, in this case a transcription has been performed and, although a universal rule does not exist, being the document under consideration a scientific paper, the scientific transliteration would undoubtedly be more appropriate.
3.2.6 Theme-rheme pattern
Проблема: Многие в России считают, что переболели COVID-19 ещё в декабре 2019 года или в январе 2020. Можно ли узнать, когда действительно в России началась эпидемия коронавируса и откуда его к нам завезли? Ответ дала биоинформатика ( )
|
Original document |
DeepL’s translation |
Human translation |
|
Ответ дала биоинформатика. |
La bioinformatica ha dato la risposta. |
La risposta è stata data dalla bioinformatica |
In the original document, denoting the Russian term биоинформатика a new piece of information, it is located at the end of the last sentence and consequently brought into sharper focus than the other terms. The same does not apply to the translated text, which, although lexically correct, does not reflect the original theme-rheme pattern and consequently fails in fully conveying the source meaning.
3.3 Quantitative analysis of the results
In the present section, the obtained results have been analysed, with regard to specialized texts and popular-science texts, as well as overall translation quality. Afterward, the total number of translation errors has been counted and shown by means of several graphs in order to provide a visual and direct understanding of the data displayed in the previous section. More specifically, before delving into the actual comparison between DeepL’s and Yandex’s translation performances, careful attention has been devoted to analysing the results obtained for each translation tool with regard to the two text types under examination, namely specialized and popular-science texts. The graphs display the translation errors occurring in each error category separately, in descending order of number of translation errors. Subsequently, the two translation tools’ performances have been compared on the basis of the number of errors occurring in the translations of the three specialized texts, the three popular-science texts, and in all texts, considered as a whole. Two different coloured columns have indeed been used to represent the two translation tools, where translation errors have been shown according to the error category to which they belong.
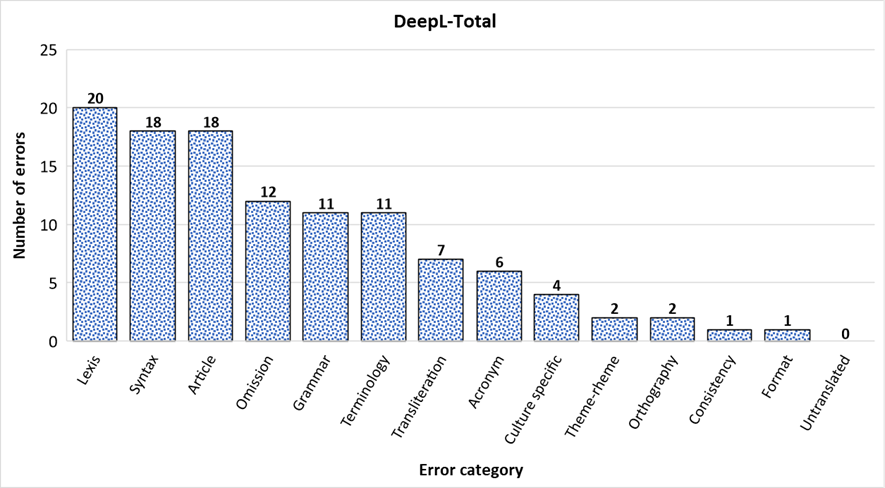
3.3.1 Analysis of DeepL translation
With a total of 113 errors, DeepL displays an undoubtedly non-uniform error distribution. Indeed, starting from the left side of the graph, three error categories, namely Lexis, Syntax, and Article Usage clearly stand out for their high number of translation errors, followed by Omission, Grammar, Terminology, Transliteration, and Acronym. On the contrary, while Culture-Specific References, Theme-Rheme Pattern, Orthography, Consistency, and Format seem to display a minor, even negligible amount of translation errors, no translation errors are marked as belonging to the Untranslated Elements category. When considering the language pair at stake, consisting of two highly different natural languages, both in terms of syntactical structure and article usage, it does not come as a surprise that the majority of the errors committed by DeepL fall in these two error categories. This may rather mean, generally speaking, that the translation tool under examination still encounters considerable difficulties in properly rendering two of the most challenging aspects of Russian-Italian translation. As for lexis, we will see later on in the present section, when considering DeepL’s translation performances with regard to specialized texts and popular-science ones separately, that the highly-specialized terms displayed in the specialized articles are proven to make a major contribution to these results.
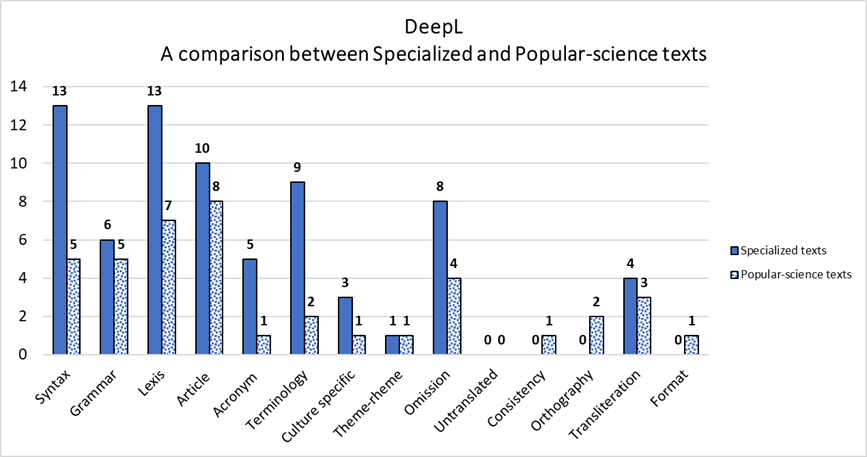
When comparing DeepL’s translation performances with regard to specialized and popular-science texts, with a total of 72 and 41 errors, respectively, we can easily notice that it performs significantly better in translating popular-science-texts. It indeed commits a higher number of translation errors with regard to specialized texts in nine out of fourteen selected error categories, except for Theme-Rheme Pattern, Untranslated Elements, Consistency, Orthography, and Format. However, those last categories display a small overall number of translation errors. Moreover, other error categories, namely Grammar, Article Use, Culture-Specific References, and Transliteration feature a narrow gap between the two text types under examination. On the contrary, Syntax, Lexis, Acronym, Terminology, Omission visibly stand out as a significant disparity can be observed in the renderings of specialized and popular-science texts. When analysing Acronym and Terminology categories, we need to consider that, since the total number of occurrences of these elements throughout specialized and popular-science texts may significantly differ, the results are likely to be biased accordingly. As for Syntax, Lexis, and Omission, we may assume that the translation tool encounters considerable difficulties in rendering the significantly more elaborate syntactical structure and the specific lexis and terminology characterizing Russian specialized medical articles when compared to popular-science ones.
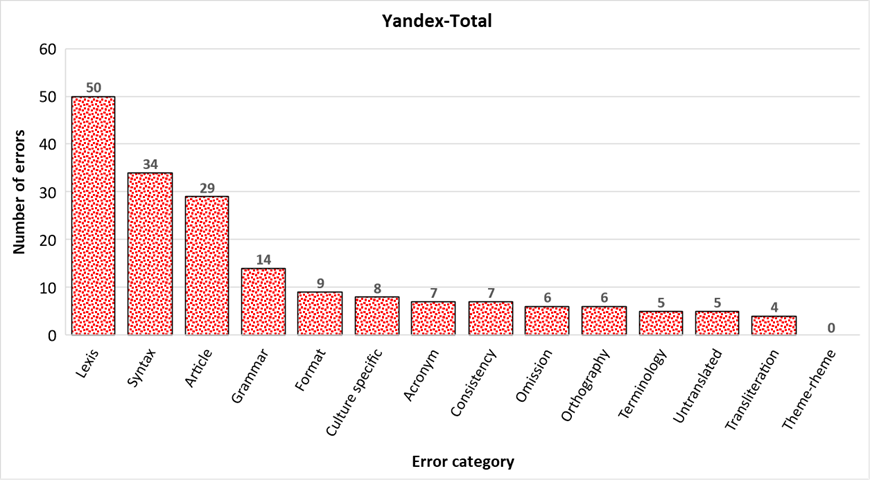
3.3.2 Analysis of Yandex translation
Yandex seems to distribute its total 184 errors quite uniformly, except for three error categories, namely Lexis, Syntax, and Article Usage, which display a significantly higher number of translation errors when compared to the other error categories. As mentioned with regard to DeepL’s translation performance, Syntax’s and Articles’ great amount of translation errors may be explained by the profound difference in syntactical structure and article usage between Russian and Italian. On the contrary, Lexis constitutes the error category displaying the greatest amount of translation errors and further analysis is needed, in this case, to determine whether this is due to a particular type of text or to the fact that the translation tool under examination encounters serious difficulties in properly rendering Italian lexis, independently of the text type. Apart from that, the other error categories do not seem to feature a great number of translation errors. Moving left to right across the graph, we can indeed easily notice that Grammar, Format, Culture-Specific References, Acronym, and Consistency, although collocated immediately after the Article Usage category, are divided from it by a huge gap, whereas they are clearly closer, by the number of translation errors, to the error categories occupying the right side of the graph, namely Omission, Orthography, Terminology, Untranslated Elements, and Transliteration, which display a small number of translation errors. Finally, no errors are marked as belonging to the Theme-Rheme Pattern category.
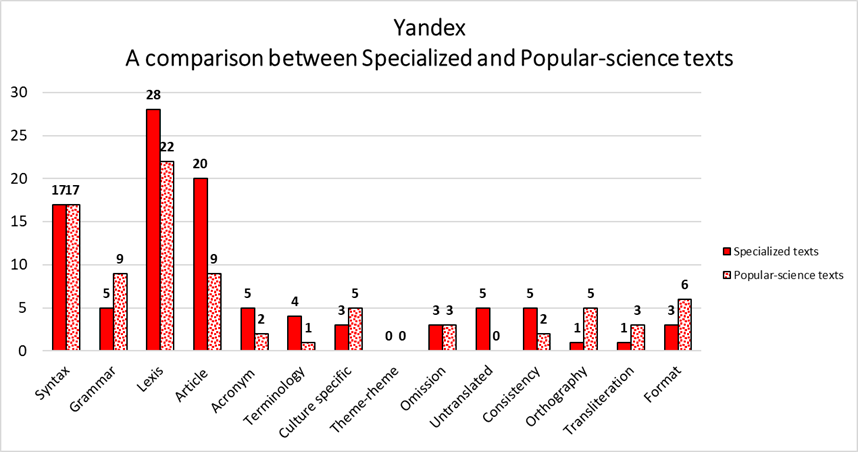
With a total of 100 errors in specialized texts’ translations and 84 in popular science's ones, Yandex seems to provide a better translation performance with regard to popular-science texts. Nonetheless, it follows a significantly different pattern when compared to DeepL’s translation performances. A small gap is indeed observed in each error category, except for Article Usage, which displays 20 errors in specialized texts and just 9 in popular-science ones. As for the other error categories, a better translation performance with regard to popular-science texts can be observed in Lexis, Acronym, Terminology, Untranslated Elements, and Consistency. On the other hand, Syntax, Omission, and Theme-Rheme display the same amount of translation errors, whereas Yandex seems to better render specialized texts’ Grammar, Culture Specific References, Orthography, Transliteration, and Format. Starting from saying that the results obtained in Acronym, Terminology, Culture-Specific References, and Transliteration may be biased by the actual number of times that these elements occur throughout the texts under examination, the ones related to Grammar, Article Usage, Untranslated Elements, Consistency, Orthography, and Format undoubtedly constitute a good starting point for a more detailed analysis of Yandex’s behaviour and patterns in translating Russian-Italian specialized and popular-science medical texts.
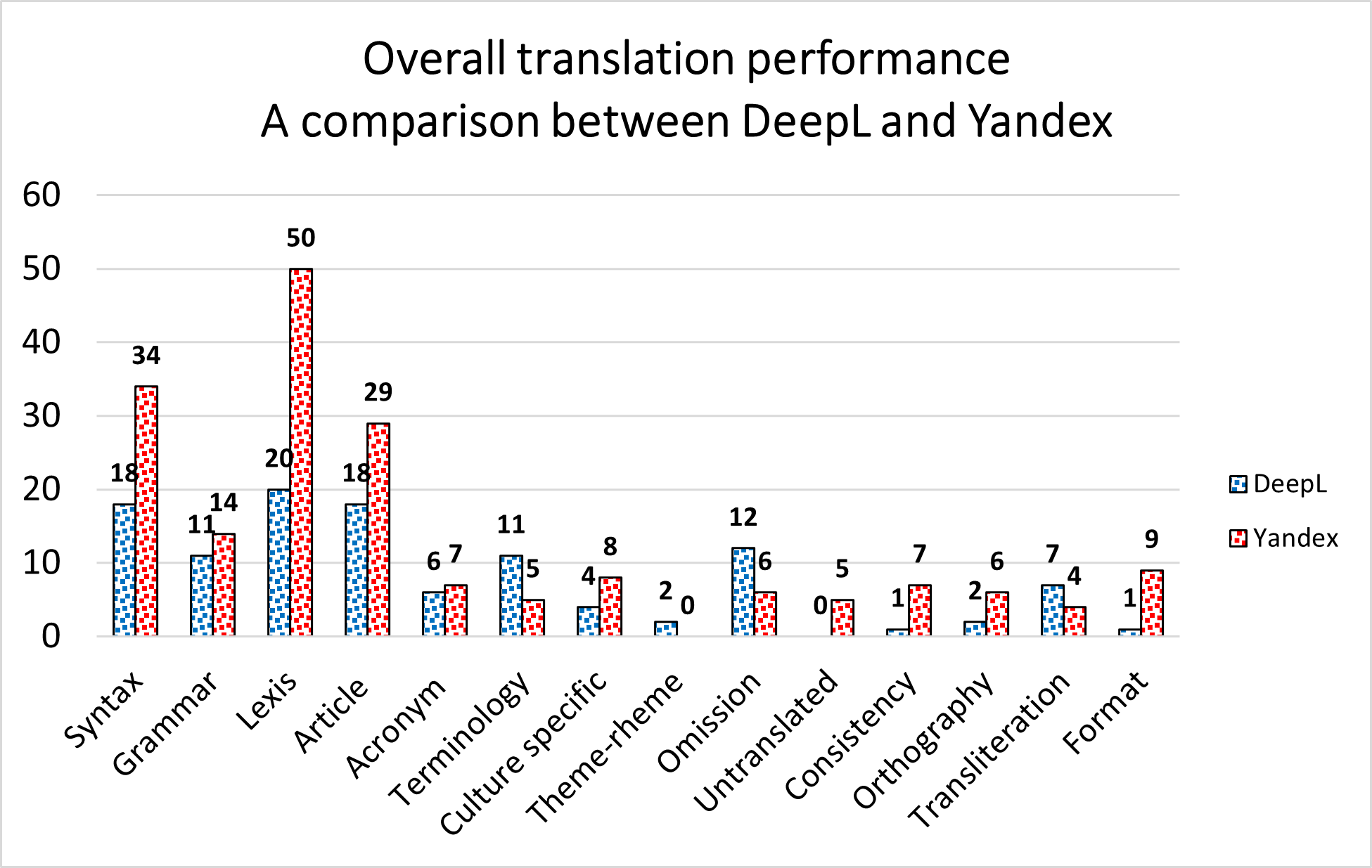
3.3.3 A Side-by-Side Comparison
When comparing the two translation tools under examination on the basis of their overall translation performances, it can be observed that they both collect a significant amount of translation errors in three error categories, namely Lexis, Syntax, and Article Usage, in order of the number of translation errors. However, these categories, first and foremost Lexis, display a wide gap between DeepL’s and Yandex’s translation performances. We can easily say that, although Syntax and Article Usage clearly constitute two of the major weakness of both translation tools, in all probabilities because of the profound difference between Russian and Italian syntactical structure and article usage, DeepL seems to be able to better render into Italian the Russian syntactical structure and is proven to remain more compliant with Italian grammatical rules when it comes to properly insert the Italian articles, non-existent in Russian grammar. As for Lexis, DeepL, once again, provides a better translation performance, however, further analysis is needed to detect whether Yandex’s high amount of translation errors are related to a specific text type.
Moreover, Yandex seems to perform better with regard to Terminology, Omission, and Transliteration, whereas DeepL is observed to commit a smaller number of translation errors in Grammar, Acronym, Culture-Specific References, Untranslated Elements, Consistency, Orthography, and Format, even though the gap in these categories is not comparable to the one observed in Lexis, Syntax, and Article Usage.
Generally speaking, a more comprehensive evaluation of DeepL’s and Yandex’s translation performances can be made by comparing the two translation tools’ behavior concerning specialized and popular-science texts separately.
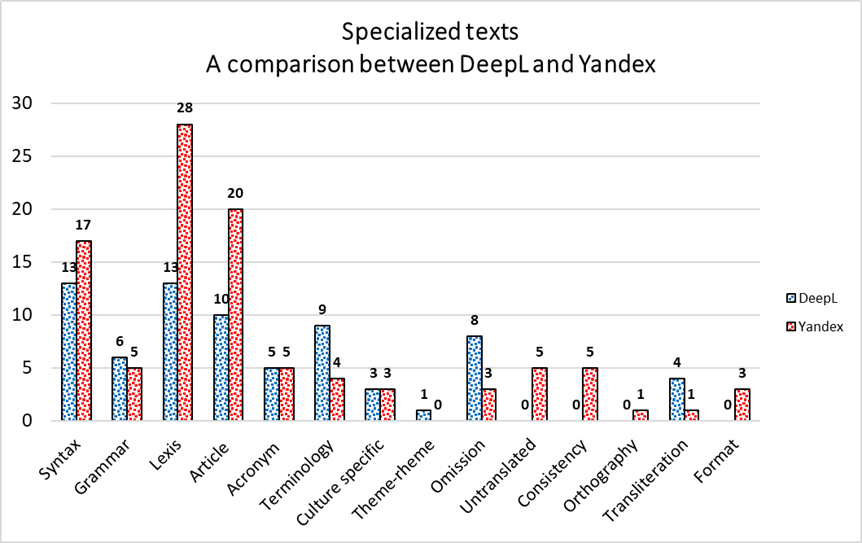
When comparing DeepL’s and Yandex’s translation performances with regard to specialized texts, with a total of 72 and 100 translation errors, respectively, DeepL seems to perform better when compared to Yandex. Indeed, the latter collects a higher number of translation errors in the majority of error categories, except for Grammar, Terminology, Theme-Rheme Pattern, Omission, and Transliteration. On the one hand, Lexis and Article Usage error categories undoubtedly stand out, as not only they display a significantly higher amount of translation errors with regard to both translation tools, when compared to the other error categories but also a great gap can be observed between DeepL’s and Yandex’s translation performances. On the other hand, Yandex is proven to give a better translation performance when compared to DeepL in Terminology, Omission, and Transliteration, even though the gap is not comparable to the one observed in Lexis and Article Usage.
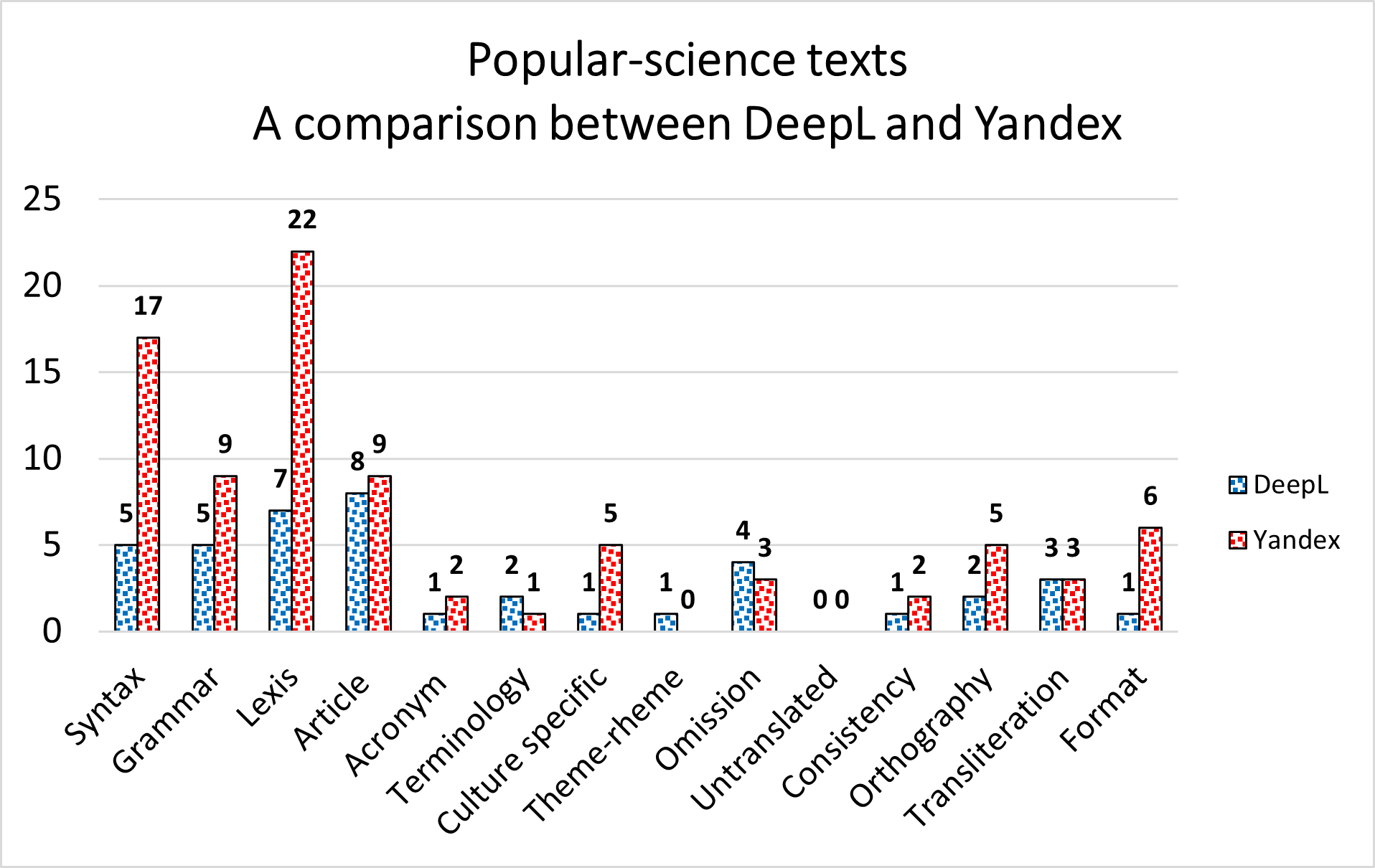
With a total of 41 translation errors committed by DeepL and 84 by Yandex, both translation tools are proven to perform better in translating popular-science texts than specialized texts. Moreover, the gap between DeepL’s and Yandex’s translation performances is observed to increase from specialized texts to popular-science ones. On the one hand, DeepL seems to perform better in all error categories, except for Terminology, Theme-Rheme Pattern, and Omission, where Yandex collects a smaller amount of translation errors, even though the gap between the translation performances under examination is quite narrow. On the other hand, Transliteration and Untranslated Elements are characterized by equal translation performances. Worth noting undoubtedly are Lexis and Syntax, which display a considerable gap between Yandex’s and DeepL’s translation performances. The two error categories, which constitute the major weaknesses of Yandex performance, do not represent an issue in DeepL’s one. Moreover, we can easily notice that the two translation tools’ performances do not follow the same pattern as with regard to specialized texts. In fact, while Lexis is characterized by a considerable gap for both text types, the same does not hold for Syntax, which displays similar translation performances in translating specialized texts and significantly different amounts of translation errors with regard to popular-science ones, and Article Usage, which presents a wide gap with regard to specialized texts and a narrow one when popular-science texts are considered.
3.3.4 BLEU Metric Evaluation
In order to provide a comprehensive evaluation of DeepL’s and Yandex’s translation performances, we hereby conduct an automatic evaluation of the provided translations using the BLEU metric. BLEU, which stands for Bilingual Evaluation Understudy, is a popular and widely used automatic evaluation metric (see Section 2.2), which assesses machine translation quality on the basis of its textual similarity with a number of human reference translations, also called golden translations. More specifically, it is an easily accessible platform where the users may upload the original document, the translations performed by the two machine translation systems under examination, and the corresponding reference translation, which serves as a benchmark to judge the quality of the machine translations. While the original document is optional, the other three texts are mandatory, and their absence may prevent the evaluation metric from properly completing the evaluation process. Once uploaded all the documents, a percentage, defining the quality of each translation, is released by the BLEU metric.
|
DeepL’s percentage of textual similarity |
Yandex’s percentage of textual similarity |
|
|
Биологическая терапия в эру COVID-19 (The biological therapy in the COVID-19 era) |
50.31 |
49.60 |
|
Ведение детей с заболеванием, вызванным новой коронавирусной инфекцией (SARS-CoV-2) (Clinical management of children with a disease caused by the new coronavirus infection (SARS-CoV-2)) |
55.12 |
43.46 |
|
Коронавирус SARS-Cov 2: сложности патогенеза, поиски вакцин и будущие пандемии (Coronavirus SARS-Cov 2: complexities of the pathogenesis, search for the vaccines, and future pandemics) |
45.14 |
51.18 |
|
Коронавирус завозили в Россию не менее 67 раз (Coronavirus was imported into Russia at least 67 times) |
36.66 |
52.88 |
|
Неизвестная летальность - Почему мы не знаем истинных масштабов COVID-19 (Unknown lethality - Why we do not know the true extent of COVID-19) |
71.58 |
45.34 |
|
Смертность от COVID 19 - Взгляд демографа на статистику причин смерти в России и мире (COVID-19 mortality rate - A demographer's perspective on statistics of causes of death in Russia and worldwide) |
76.73 |
52.31 |
As shown in the table, the BLEU evaluation metric provides an automatic evaluation of DeepL’s and Yandex’s translation performances by means of a percentage, representing the textual similarity of each analysed text with a specifically made human translation, used as reference translation. This undoubtedly constitutes an interesting starting point for our discussion. Indeed, on the one hand, having provided, in the previous sections, a manual error analysis, an automatic evaluation process is hereby displayed. On the other hand, assessing the BLEU metric the provided translations’ quality at the article level, DeepL’s and Yandex’s translation performances with regard to each specific text can be observed. Generally speaking, the BLEU evaluation metric’s results seem to reflect the ones shown by our comparative error analysis. In fact, not only popular-science articles display a higher percentage of textual similarity when compared to specialized ones but also DeepL’s translations are observed to reflect human reference translations’ features more accurately. Moreover, while a significantly wide gap can be noticed between the percentages of textual similarity assigned to DeepL’s and Yandex’s translations of popular-science texts, a minor difference is observed with regard to highly specialized texts. This perfectly applies to the first two highly specialized and the last two popular-science articles. An exception is undoubtedly constituted by the third specialized and the first popular-science articles. Indeed, by showing a higher percentage of textual similarity with regard to Yandex’s translation variants and a significantly wide gap when compared to the other articles belonging to the same text types, they do not follow the pattern established in our previous analysis. In particular, an interesting case is represented by the first popular-science article, Коронавирус завозили в Россию не менее 67 раз (Lvovič, 2020), whose translation performed by DeepL is assigned a rather low percentage of textual similarity when compared not only to the one given to Yadex’s translation performance concerning the same article but also the ones achieved by DeepL in the translation of the other highly specialized as well as popular-science texts. Investigating the reasons behind such a low percentage of textual similarity, and the inconsistency, in this specific case, between the manual error analysis and the BLEU metric evaluation of the text under examination undoubtedly represent a necessary starting point for further research in the field of automatic Machine Translation Evaluation itself, as well as regarding the possible combination of human and automatic Machine Translation Evaluation methods.