Background
OCR Workflow
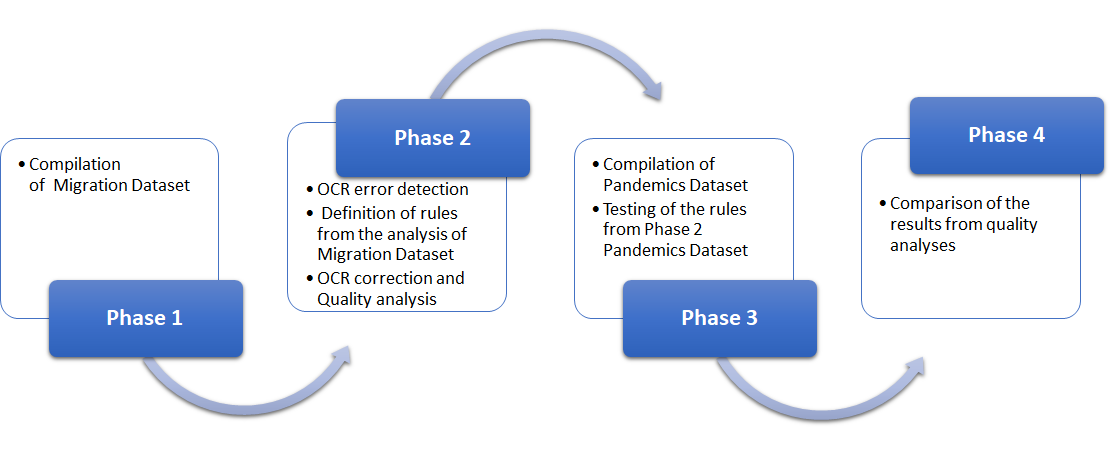
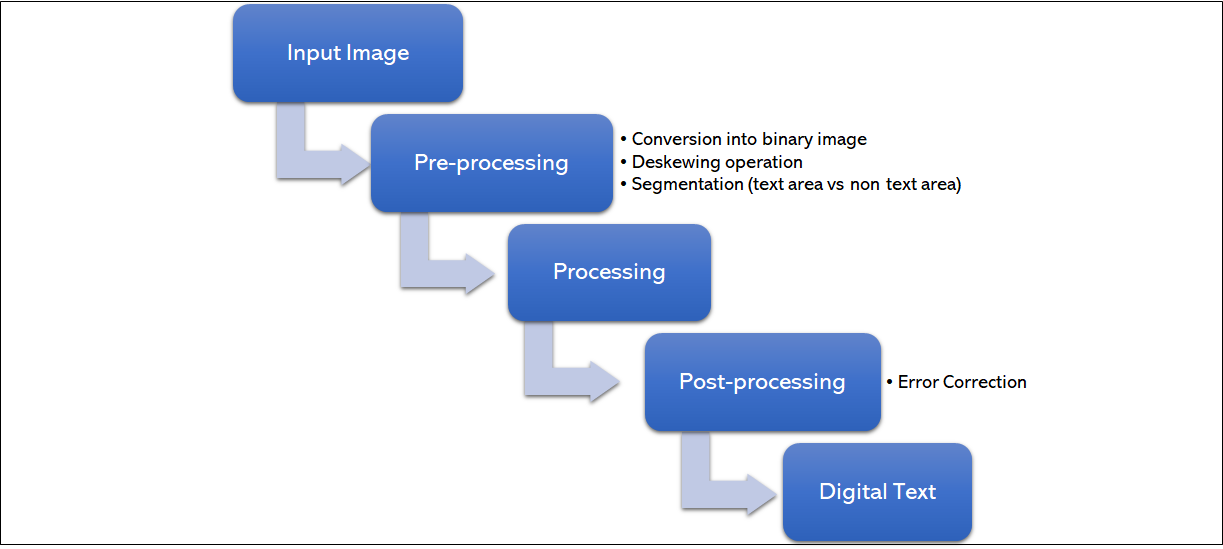
The OCR workflow can be divided into three fundamental phases ( , ):
-
Pre-processing: the input images are prepared for processing by simplifying the original color image into binary conversion, by conducting a deskewing operation, or by additionally performing works such as cropping, denoising, or despeckling. Lastly, the text is segmented and text regions are separated from non-text areas. Within this step, individual text lines and words and single glyphs are identified.
-
Processing: the OCR software recognizes the segmented lines and words or glyphs by producing a digital textual representation of the printed input. There are two basic core algorithms on which OCR recognition is based. The first one is the ‘matrix matching’ which works through the isolation and identification of the single character and the comparison of it with existing models or by training book-specific models with the support of a required Ground Truth (GT). The second algorithm is called ‘feature extraction’ and it is the extraction of features from a text - each text is decomposed into different vector-like representations of a character corresponding to a feature.
-
Post-processing: the raw textual output is improved by adopting different dictionaries, language models or GT versions of the processed document in order to correct the resulting texts.
However, such technologies do not always achieve satisfactory results and many challenges are posed to OCR software developers and users. For example, OCR-related errors may significantly affect the compilation and the investigation of a corpus ( ). Different factors in relation to the resulting digitized text have to be considered:
-
The state of preservation of the original manuscript/document;
-
The poor quality of the camera through which the image has been taken;
-
The quality of the photo taken from the original manuscript;
-
The image compression algorithm through which the photograph of the text is produced (especially when working with ancient or easily perishable texts such as newspapers);
-
Various layouts of the original texts (especially for newspapers);
-
The presence of a GT version of the image under analysis.
There are two possible ways which can be adopted to improve the quality of the documents under analysis: on the one hand, a focus on all the aspects of the pre-processing - namely the optimization of documents quality and OCR systems; on the other hand, a focus on the aspects of the post-processing - namely the optimization and development of post-processing OCR error detection and correction methods. In this paper, we focus our attention on the latter.
OCR Post-Processing Approaches - Related Work
OCR post-processing is essential for detecting and correcting errors and for improving the quality of OCR scanned documents. As argued by Nguyen et al. ( ), there are two types of errors in an OCR-scanned document:
-
Non-word errors: invalid lexicon entries which are not attested in any dictionary of the analysed language: e.g. ‘tli’ for ‘the’ or ‘nigrants’ for ‘migrants’.
-
Real-word errors: valid words which are in the wrong context.
The former are easier to identify but more difficult to correct. In contrast, the
latter are easier to correct but more difficult to identify. Generally, both errors
are analysed according to the number of edit operations used to transform an error to
its corresponding GT. The number of edit operations corresponds to the number of
changes that have to be made to correct a word. For example, the word ‘tli’ is a
non-word error of distance 2, because it requires two substitutions to be corrected.
Its GT is ‘the’ and the ‘l’ and the ‘i’ have to be substituted with ‘h’ and ‘e’. The
phrase capture a near
is a real-word error of distance 1, because it requires
only a substitution, ‘b’ instead of ‘n’, to correct in its GT capture a
bear
.
Following Nguyen et al. ( ), there are two main approaches to OCR post-processing error correction. Firstly, the dictionary-based approach aims at the correction of isolated errors. This lexically-driven method is characterized by the use of string distance metrics or word comparison between an erroneous word and a dictionary entry to suggest candidates for correcting OCRed errors. Traditionally, lexical resources or n-grams are applied in combination with statistical language modelling techniques in order to generate a list of error candidates ( ). Kolak and Resnik ( ) adopted this approach by implementing a probabilistic scoring mechanism to calculate correct candidates. Bassil and Alwani ( ), instead of using a lexicon, exploited Google's online spelling suggestion. This approach is easily applicable to any dataset and because it is not language-dependent considering that the error detection and correction tasks depend on the lexicon chosen. However, there may also be additional difficulties given by historical documents. In fact, these types of documents may have different spellings than contemporary documents which, in their turn, are generally used to compose lexicons for OCR candidates. Moreover, these approaches have the limit of being effective only on single words without considering the context. Secondly, the context-based approach takes into account the grammatical context of occurrence ( ) and it is characterized by the use of different models to detect and automatically correct errors mostly from a quantitative statistically-driven perspective. In this case, the methodologies adopted generally overcome the word-level and both the single tokens and their surrounding contexts are considered. For example, Reynaert ( ; ) adopts an anagram hashing algorithm for identifying spelling variants of the OCRed errors focusing on both character and word levels. Despite the good results, as discussed and revised by Reynaert ( ), this approach needs improvements in terms of accuracy and in terms of number of characters which can be simultaneously corrected. Volk et al. ( ) use two different OCR softwares and then merge and compare the output of the systems to perform a disambiguation of the error. However, the context is not properly considered.
Many studies tackle the OCR post-correction by approaching it as a translation problem. Afli et al. ( ) adopt a Statistical Machine Translation system (SMT) trained on OCR output texts which have been post-edited and manually corrected. Mokhtar et al. ( ) and Hämäläinen and Hengchen ( ) base their approach on using sequence-to-sequence models in neural machine translation (NMT). Amrhein and Clemantide ( ) use borth NMT and SMT and show how these two approaches could benefit each other: SMT systems produce better performance than NMT systems in error correction, while NMT systems obtain better results in error detection. Schaefer and Neudecker ( ) use a bidirectional LSTM to predict if a character is incorrect or correct. Within the ICDAR2019 competition, a post-OCR sequence-to-sequence correction model ( ) adjusted to BERT ( ) won the competition. On the same line, Nguyen et al. ( ) extended this model and proposed an approach developed from BERT and a character-level NMT. The dictionary-based approach is not able to capture all the real-word errors. For example, the English expression 'a flood of irritants' is not recognized as an error because all the words are part of the dictionary. However, analyzing the context, it should be corrected in 'a flood of immigrants'. The context-based approach intends to overcome the problems of the dictionary-based approach, however it requires more computational effort and it shows a more complex implementation.
Project objectives
The development of the methodology presented in this paper was subject to different
restrictions and forced decisions due to a series of issues relating to the data
under analysis. Firstly, considering the problem of finding and studying metaphors
(which is the objective of the projects related to this study), the accuracy of the
OCR version of the documents must be higher than the average
80% accuracy.
This is due to the fact that a small spelling error may compromise the efficacy of
the linguistic analysis. In this sense, a manual and qualitative approach is more
appropriate. However, considering the size of the dataset (see Section 3), the use of
OCR is useful as a starting point for the manual post-editing. Secondly, we have no
access to the original documents of the 20th century newspapers. It is still possible
to get the data as OCRed text documents but the quality of the image could only be
slightly enhanced by using image enhancer. Lastly, the GT version of the documents
was not available; as a consequence it was not possible to use automatic post-OCR
error correction models based on GT ( ).
Therefore, having considered that the margins for improvement by only adopting a single approach have revealed small without a proper GT and a model trained on similar language, we decided to adopt a semi-automatic mixed approach to error detection and correction by bringing together three already existing approaches:
-
The dictionary-based approach - error detection and compilation of an error candidate list by comparing the OCRed corpus with the error-free corpus;
-
The context-based approach - error categorisation and compilation of error list by statistically calculating the collocates of each candidate;
-
A manual approach - manual formulation of the correction rule for each error in the list; further confirmation by in its context of occurrence.
Therefore, we have three main objectives in this paper: present the qualitative-quantitative mixed approach to post-OCR correction; test the efficacy of the method by the application to an alternative comparable dataset; analyze the quality of the application of the rules to a different corpus.