Modellazione
Di seguito, si descrivono alcune delle scelte operate in fase di modellazione dei dati - al fine di rappresentarne i contenuti in forma semantica, considerando la duplice dimensione - tangibile e intangibile - del patrimonio culturale.
Oggetto fisico e oggetto informativo
Per poter procedere con l’allineamento dei dati e la loro modellazione sulla base delle entità e proprietà dell’ontologia CIDOC-CRM, si è reso necessario considerare gli artefatti (opere d’arte, documenti d’archivio, ecc.) nella loro duplice veste di oggetti fisici e veicoli di contenuti (simbolici, intellettuali ecc.), considerando:
-
La nascita dell’opera in quanto
idea
(le fasi della sua commissione e della sua progettazione da parte dell’autore/artista); -
La manifestazione fisica, tangibile dell’opera (quale elemento facente parte di una collezione fisicamente individuabile e, pertanto, collocato, musealizzato o archiviato, tutelato e anche custodito da Enti e
persone
a vario titolo nel corso della sua storia).
Il primo livello designa l’aspetto immateriale (intangibile) dell’opera, dal momento
della sua creazione (anche solo concettuale), mentre il secondo livello ne descrive
la produzione e trasposizione su di un supporto fisico (tangibile). La distinzione
dei due aspetti è importante perché si tratta di punti di vista differenti che
concorrono ugualmente alla realizzazione dell’oggetto - aristotelicamente considerato
come sinolo di materia e forma - nel suo insieme e che, ai fini della
modellazione dei dati, impongono una riflessione sulla consistenza dell’informazione
da rappresentare. Al fine di rappresentare completamente lo spessore semantico
dell’informazione contenuta nei dataset dei partner, si rendono necessari diversi
passaggi interpretativi: colui che identificheremo come padre dell’idea
, ad
esempio, non necessariamente corrisponderà a colui che ne crea la veste fisica o a
colui che, infine, ne diventa il possessore o che ne detiene la custodia.
I due livelli appena distinti sono espressi, attraverso gli elementi dell’ontologia CIDOC-CRM, come segue:
-
E73 Information Object: oggetto informativo (idea, concetto)
-
E22 Man-Made Object : oggetto fisico (reificazione)
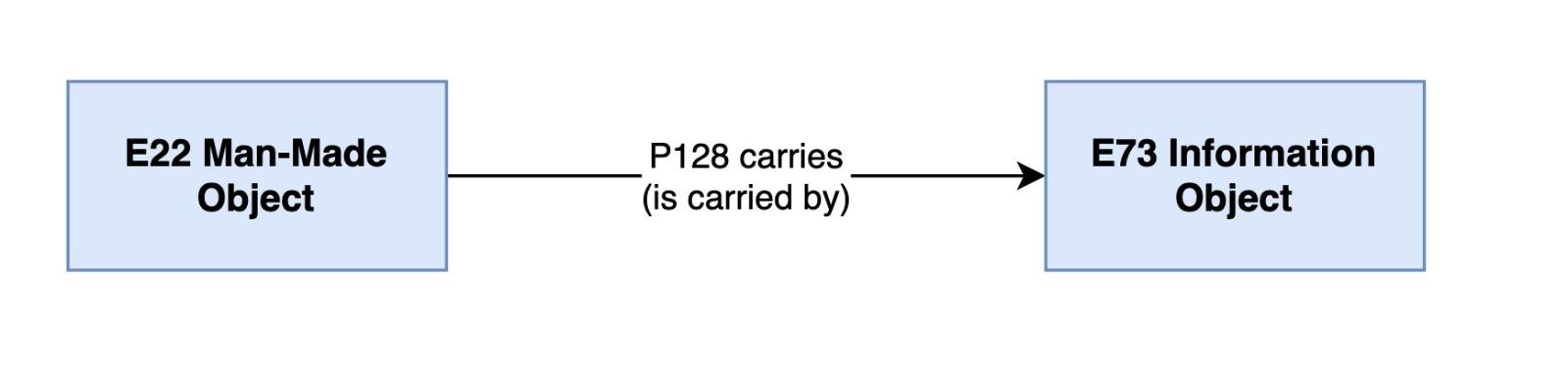
All’oggetto fisico fanno riferimento tutte le caratteristiche fisiche e tangibili dell’opera, mentre all’oggetto informativo fanno riferimento tutte le informazioni di tipo concettuale.
Identificatori
Al fine di rendere possibile l’individuazione univoca degli oggetti, si è reso necessario associare ad essi identificatori (i.e.: segnature, collocazioni, numeri d’inventario ecc.) mediante i quali essi sono descritti in cataloghi, inventari e archivi. Questi identificatori sono individuati, rispettivamente, nella segnatura per i materiali documentari conservati in archivi e biblioteche e nel Codice Univoco del Bene (NCT) per le opere d’arte. Va da sé che future estensioni del progetto includeranno set di identificatori in uso nelle diverse comunità di riferimento, attualmente non considerati.
Tradizionalmente, la segnatura dei documenti archivistici è composta dal nome del fondo e dall’identificativo dell’unità archivistica, eventualmente articolato in più sezioni (busta, inserto o fascicolo, codice dell’unità documentaria). Nel caso dell’Archivio di Stato di Prato, ogni fondo presenta una segnatura sua tipica che, nei file XML di origine, è stata suddivisa in più parti. Si è pertanto reso necessario, per ricostruirla, identificare gli elementi (i tag xml) che la componevano, esportarli separatamente nei campi dei file CSV e poi riunire le diverse parti, in modo coerente a seconda del documento descritto, mappando il risultato come un unico oggetto logico. Per quanto riguarda invece le opere d’arte, un bene culturale catalogato secondo la normativa ICCD (scheda OA) presenta un codice univoco di identificazione (NCT): si tratta di un numero dato dalla sequenza dei valori assegnati ai sottocampi Codice Regione (NCT+R) e Numero catalogo generale (NCT+N).
Questi due valori sono da intendersi come identificatori delle risorse cui si
riferiscono e sono pertanto mappati con la classe CIDOC-CRM E42 Identifier,
che designa proprio gli identificatori, da associare all’entità che descrive
l’oggetto fisico (E22 Man-Made Object), attraverso la proprietà P1 is
identified by. Inoltre, per distinguere l’origine degli identificatori dei
due enti, si è associata una tipologia all’entità identificatore, espressa dalla
classe E55 Type, che si esprime rispettivamente in segnatura
e
codice univoco del bene (NCT)
. Anche l’oggetto informativo (E73
Information Object) è associato a un suo identificatore, che è stato
individuato nel titolo assegnato alle risorse, espresso dalla classe CIDOC-CRM
E35 Title. Il titolo costituisce infatti il riferimento più immediato al
contenuto informativo dell’oggetto descritto.
|
Elemento EAD |
Campo ICCD |
Dominio CIDOC |
Proprietà CIDOC |
Entità/Rango CIDOC |
|
<container type="codice"> |
NCT (NCTR + NCTN) |
E22 Man Made Object |
P1 is identified by |
E42 Identifier |
|
<unittitle> |
SGTT |
E73 Information Object |
P1 is identified by |
E35 Title |
Persone
Le entità persona
vengono rappresentate nella modellazione attraverso la
classe E21 Person. Se le persone agiscono in gruppi o all’interno di
organizzazioni complesse, si userà invece la classe E74 Group. La classe
E21 Person si riferisce a tutte le persone esistenti - o realmente
esistite - per cui si possano ricavare notizie storiche attendibili. Alla descrizione
della persona sono legati gli antroponimi, i riferimenti a eventuali vocabolari
specializzati e liste d’autorità - date e luoghi di nascita e morte, appartenenza a
gruppi, eventuali identificatori, qualifiche e ruoli.
La nascita e la morte degli individui - sono descritte per mezzo delle classi E67 Birth e E69 Death, che esprimono, rispettivamente, l’evento di nascita e l’evento di morte, a cui è possibile collegare informazioni relative a date e luoghi. Gli elementi dei file XML EAD che riportano le denominazioni dei soggetti produttore sono persname, famname e corporateBody: a questi è associato un attributo, authfilenumber, il cui valore rappresenta l’identificatore che consente il collegamento ai file di autorità nel formato EAC-CPF.
Lo standard ICCD prevede a sua volta un file d’autorità a sé stante (AUT) dove sono riportate tutte le informazioni relative agli autori delle opere descritte nelle schede OA, a cui sono collegate attraverso il codice identificativo dell’autore.
|
Elemento EAD |
Campo ICCD |
Dominio CIDOC |
Proprietà CIDOC |
Entità/Rango CIDOC |
|
<persname> |
AUT |
E7 Activity |
P14 carried out by |
E21 Person |
|
E21 Person |
P98i was born |
E67 Birth |
||
|
E21 Person |
P100i died in |
E69 Death |
||
|
AUTL |
E67 Birth |
P7 took place at |
E53 Place |
|
|
AUTD |
E67 Birth |
P4 has time-span |
E52 Time-Span |
|
|
AUTX |
E69 Death |
P7 took place at |
E53 Place |
|
|
AUTT |
E69 Death |
P4 has time-span |
E52 Time-Span |
|
|
<famname> <corporateBody> |
AUTU |
E74 Group |
P107 has current or former member |
E21 Person |
|
AUTH |
E21 Person |
P1 is identified by |
E42 Identifier |
Ruoli
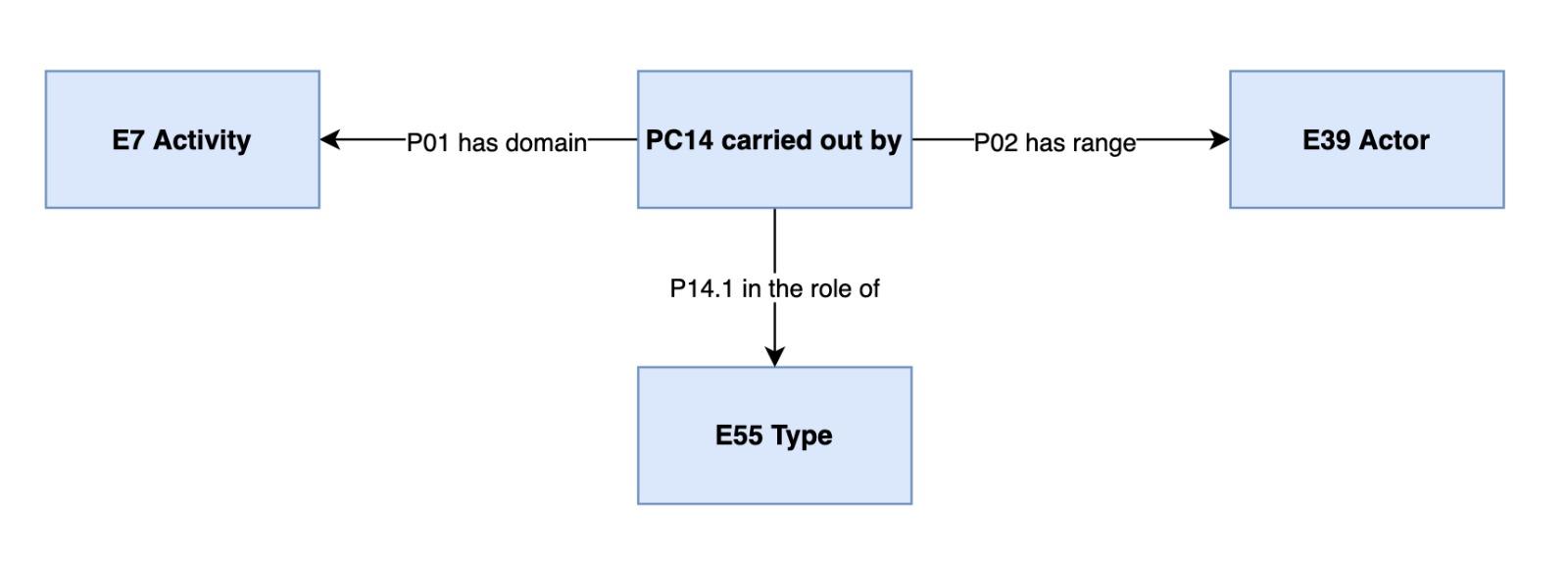
Per l’associazione degli antroponimi agli eventi, la principale criticità riscontrata ha riguardato la definizione dei ruoli: “l’individuo x ha partecipato all’evento y col ruolo z”. Volendo integrare informazioni relative agli individui presenti in più dataset, si è reso necessario considerare i differenti ruoli che questi possono ricoprire in essi: quando, ad es., un antroponimo ricorra in più contesti, la stessa persona può aver ricoperto funzioni e/o ruoli differenti in relazione ad eventi diversi (i.e.: Francesco di Marco Datini è un mercante e un banchiere quando tratta i suoi affari, un committente quando commissiona il suo ritratto a un artista, un mittente o un destinatario di una missiva, ecc.). Per fare questo è necessario estendere l’ontologia CIDOC-CRM con lo schema CRM-PC, che introduce, fra le altre, la proprietà P14.1 in the role of. Infatti, usando solo la proprietà P14 carried out by, non sarebbe possibile definire il ruolo degli individui rispetto agli eventi: tutti i ruoli verrebbero mappati come qualifiche della persona - senza poterne caratterizzare ulteriormente il ruolo svolto.
Definendo la nuova entità PC14 carried out by, essa funge da collante e risulta possibile definire il ruolo di un individuo con riferimento a uno specifico evento. PC14 carried out by è definita insieme alle proprietà P01 has domain e P02 has range, che indicano rispettivamente il dominio (evento) e il rango (individuo/soggetto) dell’entità, e P14.1 in the role of, che definisce il ruolo dell’individuo nell’evento.
Localizzazione geo-amministrativa attuale
La definizione della collocazione fisica del bene - espressa attraverso un
identificatore univoco assegnato da cataloghi o inventari e mappata mediante l’entità
Identifier
- include , oltre agli identificatori specifici per ogni
risorsa, l’indicazione dell’attuale localizzazione geografica e amministrativa ad
essa relativa. Secondo lo standard EAD, l’istituzione o l’agenzia responsabile di
fornire l’accesso intellettuale ai materiali descritti è rappresentata mediante
l’elemento repository. La scheda OA, include il campo PVC per documentare la
posizione geografico-amministrativa attuale della risorsa, relativa al territorio
italiano oppure ad organizzazioni amministrativo-territoriali di paesi esteri. In
CIDOC-CRM tali posizioni sono descritte tramite la classe E53 Place; per
definire la posizione attuale del bene è stata scelta la proprietà P54 has
current permanent location.
|
Elemento EAD |
Campo ICCD |
Dominio CIDOC |
Proprietà CIDOC |
Entità/Rango CIDOC |
|
<repository> |
PVC |
E22 Man Made Object location |
P54 has current permanent location |
E53 Place |
L’esigenza di specificare la posizione attuale delle risorse fisiche nasce dalla necessità di distinguere i differenti livelli di responsabilità degli istituti di conservazione che, pur fornendo l’accesso ed esercitando la custodia fisica dei materiali, possono non averne la proprietà. Per esempio, un archivio può assumersi la responsabilità dell’accesso intellettuale a lungo termine ai documenti elettronici, ma gli effettivi file o sistemi di dati elettronici possono continuare a risiedere nell’ufficio in cui sono stati creati e mantenuti o - ancora - possono essere tenuti in custodia a lungo termine da enti in grado di fornire le strutture tecniche appropriate per la conservazione.
Dati tecnici
Per quanto riguarda la modellazione dei dati tecnici, questi sono da considerarsi in relazione all’oggetto fisico - in quanto descrivono caratteristiche tangibili dell’oggetto stesso. Consideriamo dati tecnici associati all’oggetto fisico: i)l’informazione relativa alla composizione dell’oggetto; ii)la tecnica usata per produrlo e le sue dimensioni. Nello standard EAD, l’elemento physdesc (descrizione fisica) identifica la consistenza e tutte le informazioni sulle caratteristiche fisiche del materiale descritto. L’informazione è data come testo libero direttamente al suo interno o, in alternativa, è suddivisa negli elementi dimension, extent (consistenza del materiale descritto), genreform (caratteristiche del formato fisico), physfacet (informazioni sull’aspetto esteriore/fisico del materiale). Nello schema OA il campo MTC comprende sia la materia che la tecnica utilizzate durante la produzione dell’opera. Per la modellazione in CIDOC-CRM, materia e tecnica si configurano separatamente, in vista anche dell’allineamento con lo standard EAD. Indichiamo pertanto con MTC/M la materia di cui consiste l’oggetto fisico (supporto o altri materiali) e con MTC/T la tecnica utilizzata durante l’evento di produzione, mentre il campo MIS concerne le misure del supporto fisico dell’opera. Le misure degli oggetti sono espresse attraverso l’entità E54 Dimension di CIDOC-CRM. Attraverso l’entità E54 Dimension è possibile collegare l’unità di misura con E58 Measurement Unit e i valori numerici che vanno a definire la dimensione con E60 Number.
|
Elemento EAD |
Campo ICCD |
Dominio CIDOC |
Proprietà CIDOC |
Entità/Rango CIDOC |
|
<physfacet type= "supporto"> |
MTC/M |
E22 Man Made Object |
P45 consists of |
E57 Material |
|
MTC/T |
E12 Production |
P32 used general technique |
E55 Type |
|
|
<extent> |
MIS |
E22 Man Made Object |
P43 has dimension |
E54 Dimension |
Stato di conservazione
Lo stato di conservazione è un’informazione sulla condizione dell’oggetto in un certo momento; se non sono presenti riferimenti temporali si considera l’informazione come relativa al momento della catalogazione dell’opera.
Per la modellazione CIDOC-CRM, E3 Condition State descrive lo stato di un
oggetto lungo un certo periodo di tempo. Si collega l’entità E3 Condition
State all’oggetto fisico attraverso la proprietà P44 has condition.
Lo standard EAD consente di codificare le informazioni che servono a descrivere lo
stato di conservazione del documento: le informazioni specifiche sono fornite
all’interno dell’elemento phystech. Nello schema OA, invece, il campo STCC
indica se lo stato dell’oggetto è buono
, discreto
, mediocre
,
cattivo
o se il dato non è disponibile. Considerata la natura
dell’informazione del campo STC e dell’elemento phystech, lo stato di
conservazione si intende al momento della catalogazione, se non sono presenti altre
specifiche. La natura della condizione può essere indicata con P2 has type: E55
Type associato a STCC.
|
Elemento EAD |
Campo ICCD |
Dominio CIDOC |
Proprietà CIDOC |
Entità/Rango CIDOC |
|
<phystech> |
STC |
E22 Man Made Object |
P44 has condition |
E3 Condition State |
|
STCC |
E3 Condition State |
P2 has type |
E55 Type |
Eventi
Per evento si intende l’insieme di processi e interazioni delimitati e coerenti, che portano dei cambiamenti in sistemi culturali, sociali o fisici, e che vanno a modificare lo stato dell’entità cui si riferiscono. In generale un evento si qualifica come un qualsiasi processo definito che abbia come risultato un cambiamento dello stato dell’entità cui fa riferimento. Gli effetti di un evento non sono necessariamente permanenti e incontrovertibili: l’evento stesso, tuttavia, deve poter essere documentato. Per documentare l’evento ne deve rimanere qualche traccia nella forma degli elementi che vi hanno compartecipato. In generale un evento si intende come un’interazione fra:
-
Uno o più partecipanti
-
Luogo di svolgimento dell’evento
-
Estremi temporali
Infatti, sebbene un evento possa apparire come se avesse un effetto
istantaneo
, in realtà qualsiasi processo o interazione materiale ha
un’estensione spazio-temporale (per questo si fa riferimento agli eventi come ad
entità temporalmente definite o temporal entities
,
mentre le altre entità, come persone ecc, sono considerate entità persistenti o
persistent entities
). Si descrivono di seguito gli
eventi che hanno più ampio utilizzo all’interno della modellazione fin qui
eseguita.
Produzione
La classe CIDOC-CRM E12 Production comprende le attività che hanno come
scopo la creazione di uno o più nuovi oggetti (i.e.: caratterizzati da estensione
spaziale) a partire da altri materiali. Si può intendere
la produzione come una specializzazione dell’attività di modifica, dove per
modifica
si intende una rielaborazione dello stesso oggetto, che non
cambia nella sostanza, mentre produrre
implica la creazione di qualcosa di
nuovo
a partire dai materiali iniziali, che saranno diversi dal
risultato finale della produzione. Si intende come nuovo
qualcosa che nella
sostanza e nella forma non somiglia ai materiali coinvolti nella sua produzione
oppure qualcosa che acquista un nuovo significato a livello di documentazione alla
luce di una modifica, diverso da quello che aveva prima.
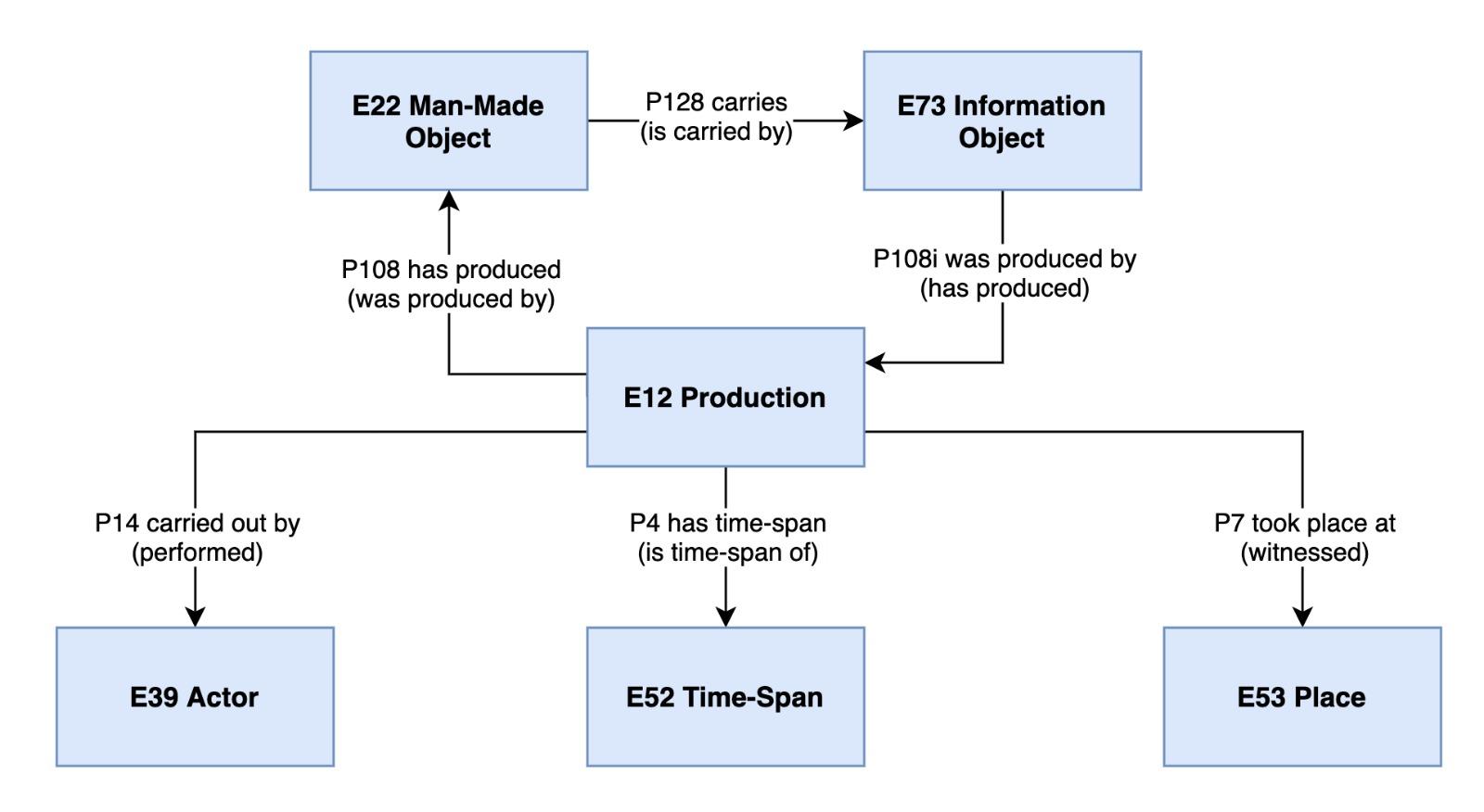
Nel caso delle opere d’arte, la realizzazione di un’opera è la produzione di un nuovo oggetto fisico, con caratteristiche e portatore di significati diversi rispetto ai materiali che lo compongono. Alla produzione dell’opera concorrono uno o più partecipanti (i.e.: autore/i) in un determinato luogo e in un tempo definito. Per quanto riguarda invece i materiali archivistici, la produzione è da intendersi come riferita all’oggetto quale insieme delle sue caratteristiche fisiche, composto di carta, legno, inchiostro, ecc. Volendo invece documentare l’attività di stesura del manoscritto o l’ideazione della parte simbolica dei contenuti di un’opera d’arte, si farà riferimento alla classe E65 Creation, che descrive l’evento creazione.
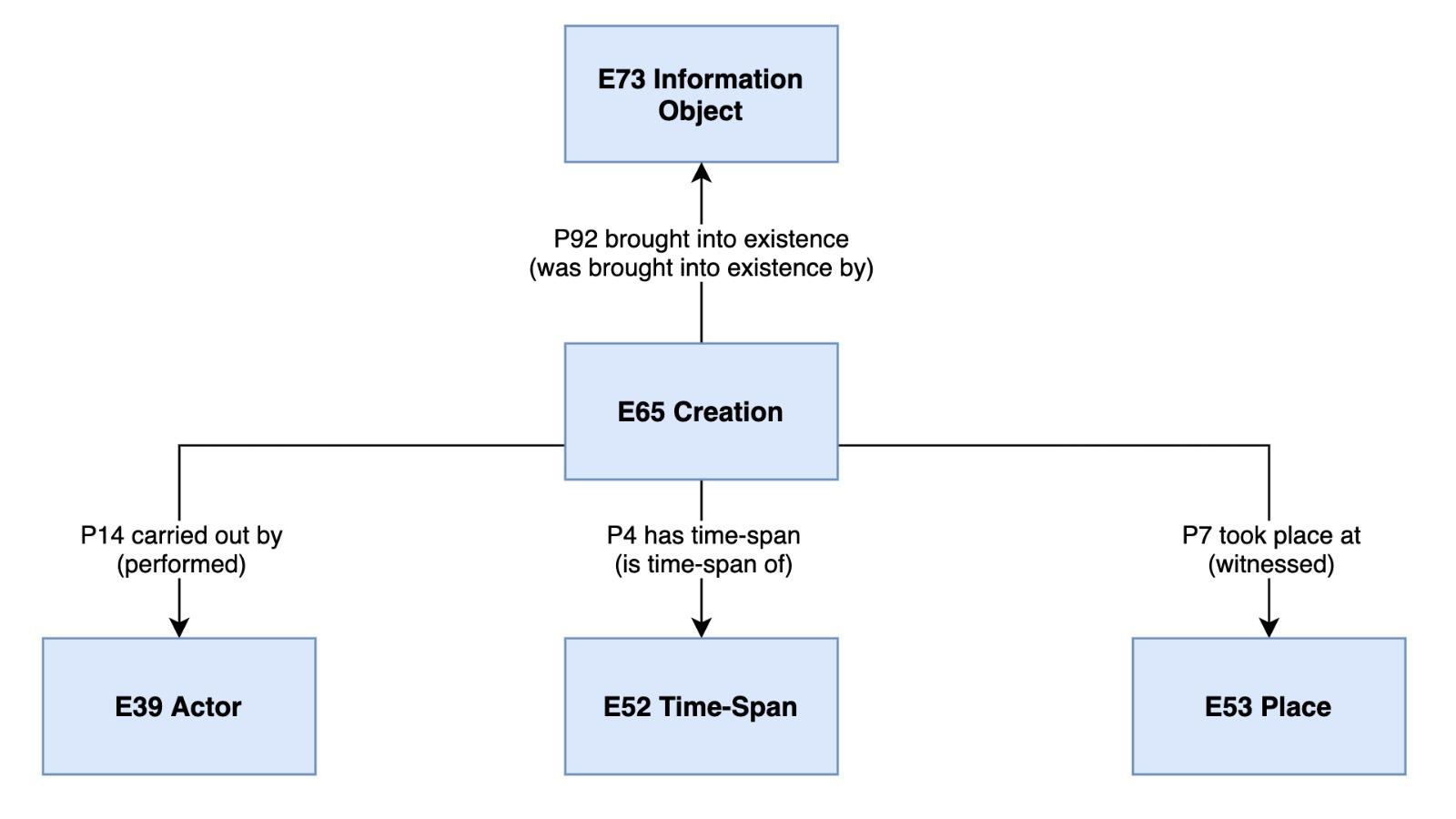
Creazione
La classe E65 Creation descrive un evento che porta alla creazione di oggetti concettuali o prodotti immateriali, come leggende, poesie, testi, musica, immagini, film, leggi ecc. Si è scelto pertanto di associare al contenuto informativo del materiale descritto l’evento di creazione, svolto da un autore (persona, famiglia o gruppo), in un determinato luogo e in un determinato tempo.
L’evento creazione
è stato associato alla stesura dei documenti
dell’Archivio di Stato di Prato (e potrà essere utilizzato - allo stesso modo - in
contesti simili, legati al patrimonio manoscritto ecc.), in quanto si è ritenuto
che il contenuto informativo espresso dal testo fosse da considerarsi
separatamente rispetto al supporto da cui viene veicolato. In quanto oggetto
concettuale il testo rientra pertanto negli scopi della classe E65
Creation.
Relativamente ai documenti dell’Archivio di Stato di Prato, si è scelto di mappare
l’evento creazione solo per la tipologia di documento registro
, mentre si è
scelto di associare alla tipologia carteggio
l’evento exchange
letters, appositamente creato per la modellazione di queste risorse.
Trasferimento di custodia
La classe E10 Transfer of Custody descrive il trasferimento della custodia fisica o della responsabilità legale di un oggetto fisico (quindi il riferimento è sempre all’entità E22 Man-Made Object). I casi di utilizzo dell’entità E10 Transfer of Custody sono:
-
presa in carico della custodia (nel caso in cui non esista un responsabile precedente);
-
fine della custodia (non c’è un responsabile successivo);
-
trasferimento della custodia da un responsabile a un altro;
-
presa in carico della custodia da un soggetto ignoto (il responsabile precedente è sconosciuto, non documentato);
-
smarrimento dell’opera (l’attuale custode è sconosciuto).
Si noti che l’indicazione del donatore o del destinatario della custodia è opzionale, poiché è infatti possibile che essi non siano documentati. Inoltre, la responsabilità legale potrebbe ricadere su di un soggetto separato da colui o coloro che detengono la custodia fisica dell’oggetto, come specificato nel paragrafo 4.4: in questo caso, si può documentare il tipo di responsabilità in atto rispetto al trasferimento di custodia con la proprietà P2 has type. Quando si parla di custodia fisica, l’oggetto deve materialmente trovarsi in possesso del responsabile (interamente o in parte in caso di oggetti composti).
Nelle schede OA è presente il campo LA (altre localizzazioni geografico-amministrative) che, sostanzialmente, contiene i passaggi di mano dell’opera - documentati nel corso del tempo: l’inizio e la fine della custodia presso ciascun ente è documentato, in modo più o meno preciso, attraverso il campo PRD, che contiene l’informazione sugli estremi temporali in cui un’opera è documentata presso un determinato ente/istituto. La relazione tra questi luoghi è stata modellata con CIDOC-CRM attraverso istanze di E10 Transfer of Custody, mediante le quali si può tracciare la cronologia dei diversi passaggi e quindi ricostruire una parte della storia degli artefatti, relativa alla loro circolazione. Se non fosse stato disponibile il dato temporale si sarebbe potuta utilizzare solo la proprietà P49 has former or current keeper, che associa all’oggetto fisico i suoi attuali e/o precedenti custodi e che è anche una scorciatoia rispetto al percorso più dettagliato, rappresentato dall’evento descritto dalla classe E10 Transfer of Custody.
Questa scelta si è rivelata efficace anche al fine di tenere traccia delle informazioni di carattere cronologico espresse nella scheda OA.
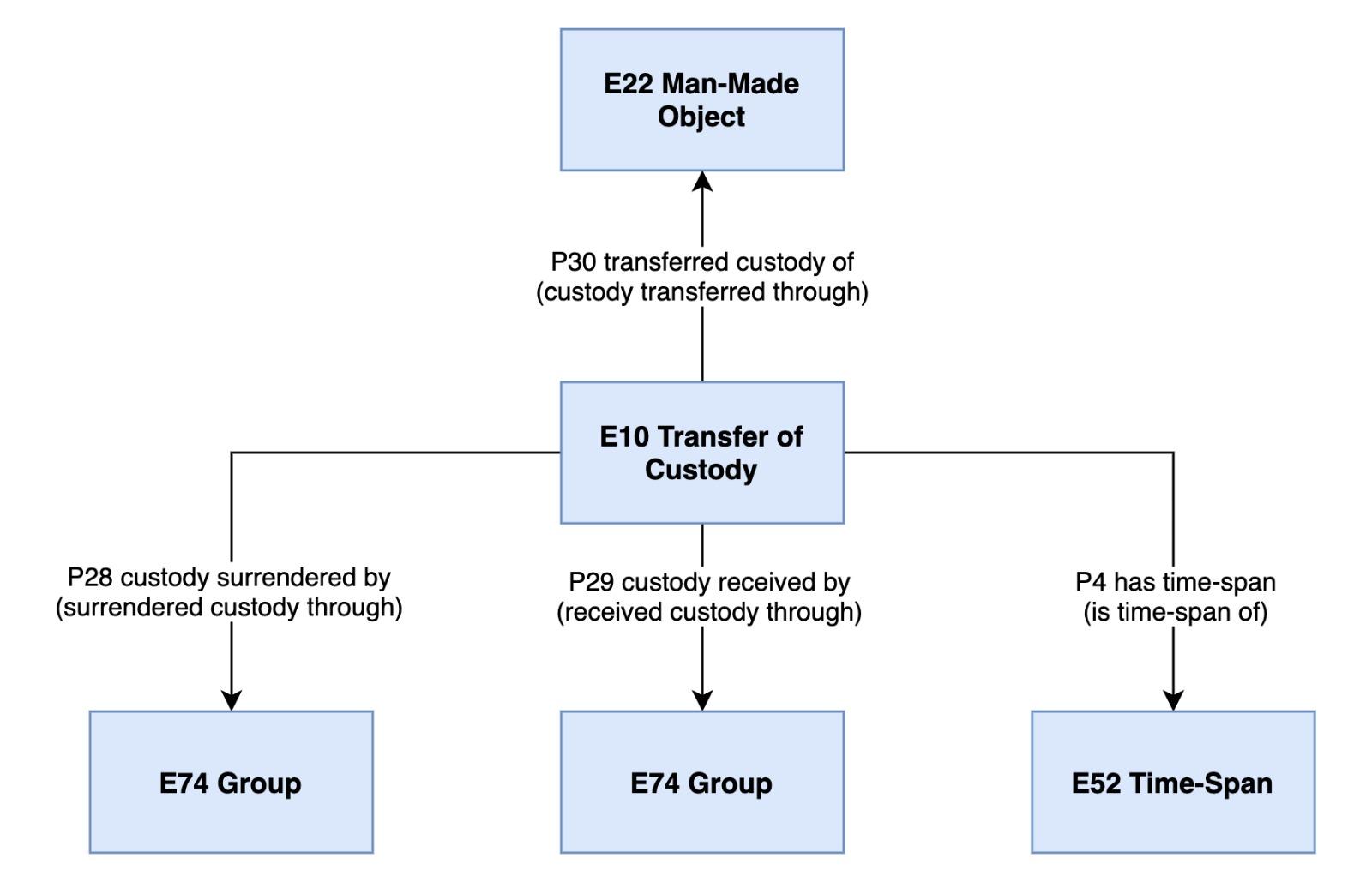
L’ultimo responsabile dell’opera documentato, in realtà, è riportato nel paragrafo LC (localizzazione geografica-amministrativa attuale), che descrive l’attuale custode dell’opera. Quindi l’ultimo passaggio di custodia si articola tra l’ultima localizzazione geo-amministrativa riportata in LA (sulla base della cronologia) e la localizzazione riportata in LC. Tutti gli enti descritti sono o sono stati custodi (keeper) dell’opera. Per esprimere la cronologia (E52 Time-span) è stato usato il campo PRDI (data di inizio della custodia presso l’ente cui si riferisce), per indicare la data in cui si è svolto l’evento di trasferimento di custodia da un ente all’altro.
Scambio delle lettere
Relativamente alla tipologia documentaria del carteggio (cfr. sopra il paragrafo 4.7.2), si è
utilizzato l’evento E9 Move (i.e.: movimento) per descrivere le modifiche alla posizione fisica delle risorse considerate, ovvero il loro spostamento. Le proprietà P27 moved from e P26 moved to si collegano alle istanze della classe E53 Place che descrivono - rispettivamente - il punto di partenza e di arrivo dello spostamento considerato. Questa classe, focalizzandosi sullo spostamento dell’oggetto, si è rivelata non essere la soluzione migliore per la rappresentazione delle informazioni relative ai carteggi: una tipologia che prevede l’invio e la ricezione di un documento e che necessita quindi di esprimere anche informazioni essenziali sul destinatario e il mittente. Si è resa necessaria, pertanto, l’implementazione di una nuova classe, EL1 Exchange of letters, avente come superclasse E7 Activity, per la definizione dello scambio lettere. Le due sottoclassi EL2 Send letter e EL3 Receive letter, indicano in maniera più specifica l’attività di invio e ricezione di una lettera. Associando a queste classi la proprietà P14 in the role of, è possibile specificare gli attori coinvolti e i rispettivi ruoli di partecipazione (mittente e destinatario).