Il report descrive la sperimentazione del riconoscimento automatico di scrittura applicato ad alcuni registri di un notaio beneventano di fine Quattrocento/inizio Cinquecento per mezzo della piattaforma Transkribus, con l’obiettivo di creare una trascrizione automatica che includa lo scioglimento delle abbreviazioni per creare un testo più leggibile. Questa sperimentazione è particolarmente significativa perché i registri notarili costituiscono spesso l’unica fonte numericamente importante per l’Italia meridionale d’età rinascimentale, per cui una trascrizione automatica, anche non perfetta, può essere un prezioso strumento per facilitare l’accesso a tali fonti.
The report describes the experimentation of automatic handwriting recognition with the Transkribus platform for some registers of a late fifteenth/early sixteenth-century Benevento notary, with the goal of creating an automatic transcription that includes automatic dissolving of abbreviations to create a more readable text. This experimentation is particularly significant because notarial registers are often the only numerically important source for Renaissance southern Italy, and an automatic transcription, even a less than perfect one, can be a valuable tool for facilitating access to these sources.
Introduzione
Il riconoscimento automatico di scrittura (Handwritten Text Recognition, HRT) è una delle tecnologie più interessanti per il riutilizzo della crescente quantità di beni culturali digitalizzati in quanto offre un accesso ai contenuti senza dover provvedere manualmente alla creazione di metadati. In misura particolare questo vale per documenti archivistici seriali come i protocolli notarili che sono una fonte preziosa per la storia economica e sociale del Medioevo e della prima età moderna, ma che si editano raramente. Per l’Italia meridionale tardo-medievale costituiscono inoltre spesso l’unica fonte numericamente rilevante. Questo è il motivo per cui è stato deciso di avviare una sperimentazione del riconoscimento di scrittura per alcuni registri campione del Mezzogiorno – a nostra conoscenza la prima nell’ambito – che ha preso forma nel contesto di un progetto di ricerca in atto che indaga la storia di Benevento nel tardo Medioevo attraverso i registri notarili (). La presente indagine si colloca in un’ottica più ampia – quella mediterranea – facendo parte del progetto El notariado público en el Mediterráneo Occidental: escritura, instituciones, sociedad y economía (siglos XIII-XV) dell’Università di Barcellona (). La ricerca si svolge grazie a un assegno di ricerca dell’Istituto di Scienze del Patrimonio Culturale, Consiglio Nazionale delle Ricerche (ISPC-CNR), della durata di un anno con un rinnovo di 6 mesi, di cui è titolare chi scrive. Il gruppo di ricerca, che nel gennaio 2002 ha organizzato un seminario sull’argomento, annovera anche le persone di Gemma Teresa Colesanti (ISPC-CNR) e Eleni Sakellariou (Dipartimento di Storia e Archeologia, Università di Creta).
Lo stato dell’arte
La Handwritten Text Recognition fa parte del campo dell’apprendimento automatico e nel presente si avvale per lo più di reti neurali artificiali (artificial neural networks, ANN), vale a dire di algoritmi ispirati alla struttura del cervello umano con nodi neurali interconnessi che trasmettono un segnale da uno strato a quello seguente, ad esempio un’immagine, della quale ogni strato riconosce altre caratteristiche visuali per poter alla fine localizzare il testo e identificare una sequenza di lettere. Mentre il riconoscimento ottico dei caratteri (OCR), che solitamente si usa per i testi stampati, si basa sul riconoscimento di singole lettere, il riconoscimento automatico di scrittura a mano adotta il principio del riconoscimento di intere righe o anche di intere parole. Questo perché la scrittura a mano è caratterizzata da un andamento corsivo che tende a legare le lettere e a trasformare la loro forma in dipendenza dal loro contesto, cioè dalla lettera che precede e da quella che segue.
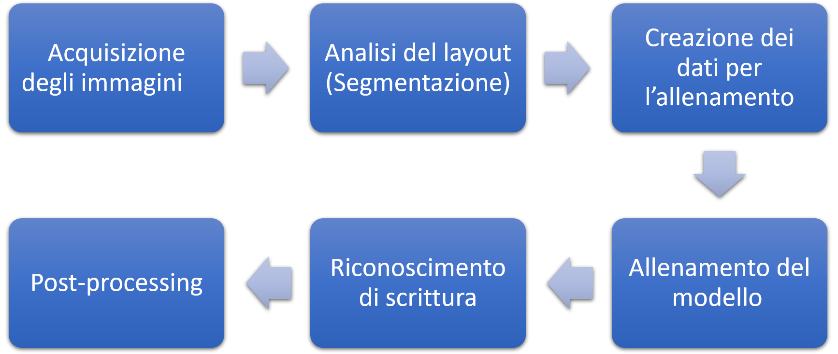
Un flusso di lavoro per la produzione di testo trascritto in maniera automatica comprende non solo il vero e proprio riconoscimento del testo, ma anche altre fasi di lavoro in dipendenza dagli obiettivi del progetto e dal materiale a disposizione. Ad esempio, per migliorare la qualità del testo trascritto può essere necessario un pretrattamento delle immagini, come la riduzione del rumore o la conversione in bianco e nero o un post-processing con strumenti dell’elaborazione del linguaggio naturale. L’unica fase di lavoro che deve imprescindibilmente precedere il riconoscimento è la segmentazione ossia il riconoscimento del layout della pagina poiché una corretta individuazione degli elementi fisici e logici presenti sulla pagina è la conditiosine qua non per un riconoscimento di testo. Tale processo richiede inoltre un allenamento della rete neurale con esempi di input e output abbinati: in altre parole al sistema va fornito un numero rilevante di trascrizioni ed esse vanno inserite in maniera tale che ogni rigo riconosciuto nell’immagine corrisponda al relativo rigo della trascrizione. L’insieme costituisce la cosiddetta ground truth o verità di base; la rete allenata con un set di trascrizioni si definisce modello.
Negli ultimi dieci anni il riconoscimento di scrittura si è evoluto passando dall’essere un campo di ricerca emergente al profilarsi come in una tecnologia matura, grazie alla quale la ricerca informatica affronta oggi problemi specifici come il riconoscimento di layout complessi, in particolare di tabelle, formule matematiche e iniziali, o la riduzione della quantità di ground truth necessaria per l’allenamento di un modello, ad esempio mediante la creazione di dati sintetici (; ; ). Altri campi in cui la ricerca informatica è applicata al riconoscimento automatico di scrittura sono quelli del riconoscimento di una pagina per intero, dell’allenamento semi- o non-supervisionato, o dell’allenamento di reti neurali che svolgono due compiti in contemporanea per ridurre il rischio di un sovradattamento al set di allenamento (). Inoltre sono state sviluppate piattaforme che integrano tutte le varie fasi di un workflow per il riconoscimento e permettono all’utente di usufruire della tecnologia anche senza disporre di conoscenze informatiche approfondite (). L’indagine umanistica, oltre al riconoscimento per scritture con orientamento diverso dall’orizzontale e sinistra-destra, si occupa ora di sviluppare ontologie per l’analisi del layout di manoscritti (), criteri di trascrizione che favoriscano il riconoscimento con reti neurali (con la creazione della relativa ground truthgold-standard orientata a confrontare le prestazioni di diverse reti neurali) e la creazione di modelli generici per scritture e mani simili dello stesso periodo (). Sempre nell’ottica della valutazione del paragone di reti neurali si diffonde anche la pratica di condividere i dati come uno dei risultati della ricerca, nello specifico trascrizioni in forma di dataset su piattaforme come Zenodo e GitHub. Quest’ultimo sviluppo è all’origine di iniziative come HTR-United che hanno l’obiettivo di offrire un punto di raccolta per modelli e trascrizioni per il riconoscimento di scrittura.
I materiali
L’oggetto della sperimentazione sono i registri del notaio beneventano Marino Mauriello (Marinus de Maurellis), attivo tra il 1498 e il 1522, morto nel 1527. Il notaio è noto anche grazie alle annotazioni storiche inserita tra gli atti che danno conto di alcuni eventi nella storia della città, enclave pontificia nel Regno di Napoli (, 253). All’Archivio di Stato di Benevento si conservano 6 protocolli suoi, diversi rogiti legati in 3 volumi miscellanei e documenti in pergamena; inoltre sono da attribuirgli numerose pergamene nel Museo del Sannio e probabilmente anche nella Biblioteca Capitolare. I quinterni contractuum cartacei di Mauriello, di formato 28x21 cm e vergati da un’unica mano, quella del notaio, si prestano a una sperimentazione perché sono di fattura molto curata e la maggior parte di essi è ben conservata; inoltre la mano del notaio appare regolare e leggibile.
Dal punto di vista dei contenuti troviamo – come in molti protocolli notarili – testamenti, contratti di matrimonio, permutazioni e compravendite che riguardano case, terre, orti e vigne, nomine di procuratori e guardiani, contratti di società e di affitto (ad esempio di case, terre, botteghe, ma anche di animali), donazioni, concordie e così via, il tutto stilato in latino con l’eccezione della descrizione delle doti, sempre riprodotta in volgare.
Tre dei sei registri sono dotati di un frontespizio con il proemio che indica il nome del notaio, il suo signum, il motto e il periodo incluso; alla fine del volume segue la formula di chiusura con sottoscrizione e signum notarile. Non sono presenti indici o rubriche. I vari atti sono stati registrati in ordine cronologico, uno di seguito all’altro, in forma di imbreviatura estesa, ma di solito con le formule più frequenti abbreviate con et cetera e senza sottoscrizione e signum del notaio. Occasionalmente appaiono documenti per i cui dettagli il notaio rinvia alle sue filze (, 261). Ogni atto è preceduto da un piccolo riassunto di una o due righe che indica le due parti coinvolte e la tipologia del negozio. A volte risultano spazi bianchi lasciati per aggiornare o completare un rogito; ciò occorre regolarmente in caso di contratti matrimoniali. In caso di riempimento di questi spazi riservati spesso troviamo le aggiunte di un modulo più piccolo che possono anche sovrapporsi all’inizio del documento seguente. Quando è presente l’invocatio gli atti iniziano con una I iniziale ingrandita, posizionata fuori dallo specchio scrittorio, che si estende accanto a un numero variabile di righe.
Archivio di Stato di Benevento, Notai, reg. 32 ff. 141v-142r, per gentile concessione dell’Archivio.
In margine si trovano altre aggiunte, a volte scritte anche parallelamente al lato lungo della pagina, e le annotazioni del notaio riguardo alla redazione in mundum o alla stesura di copie. In tale caso Mauriello si limita all’annotazione e non depenna il documento. Correzioni sue appaiono solo occasionalmente, spesso in forma di cassazioni o di inserimenti in interlineo. A volte nel manoscritto si incontrano foglietti inseriti, minute, appunti e promemoria, ma anche atti sciolti di altri notai legati insieme a inizio o fine di un registro, inserimenti questi ultimi presumibilmente risalenti al restauro dei volumi.
Quanto detto fin qui riguarda soprattutto l’analisi del layout e ha avuto anche ripercussioni sulla organizzazione del flusso di lavoro. Quanto, invece, verrà descritto in seguito, vale a dire le caratteristiche intrinseche del manoscritto, ha rilevanza in merito al riconoscimento di scrittura. In generale, la documentazione notarile è caratterizzata da strutture relativamente rigide e da un linguaggio giuridico specifico con formule che si ripetono in dipendenza dal negozio oggetto del rogito. Altre parti sono invece altamente individuali e alcune parole, come nomi di persone o di luogo (soprattutto microtoponimi), possono comparire anche una volta sola in tutti gli atti. Dato che le reti neurali si allenano con un set di trascrizioni modello, nel training sono sovrarappresentate le parti formulari ripetitive, per cui il loro riconoscimento è facilitato. A maggior ragione la scelta delle pagine da includere nella ground truth ha dovuto tenere conto di questa specificità, selezionando documenti con negozi giuridici differenti. Complessivamente appaiono raramente cifre in arabo e parti in maiuscole, per cui anche in tale contesto ci si può aspettare che il raggiungimento della massa critica per l’allenamento richieda un numero elevato di pagine.
Inoltre, protocolli notarili sono solitamente molto ricchi di abbreviazioni e i volumi di Mauriello non costituiscono un’eccezione; grosso modo ogni terza parola ha una o più abbreviazioni. È da tener presente che nel sistema abbreviativo medievale appaiono anche molti compendi non inequivocabili; questo vale in particolare per abbreviazioni per troncamento come Io con un trattino diagonale che può essere sciolto con tutte le forme declinate del nome Iohannes, o per segni tachigrafici come il c conversum che può indicare con, com, cum e cun.
Obiettivi e organizzazione
Una volta chiarite le caratteristiche materiali dei registri abbiamo fissato gli obiettivi della nostra sperimentazione partendo dalla considerazione che nell’ottica di un’utenza di storici andasse in primis perseguito il conseguimento di un testo leggibile e ricercabile, ragione per cui si è optato per una trascrizione con abbreviazioni sciolte. Oltre a ciò era chiaro che il lavoro investito nello sviluppo di un modello dovesse essere fruibile anche da altri ricercatori e aperto a ulteriori sviluppi. D’altro canto non è stato possibile in questa fase usufruire della collaborazione di un informatico, circostanza che ci ha spinto a vagliare le diverse opzioni tenendo conto anche di soluzioni per utenti non esperti.
Dopo aver fatto un’indagine sulle reti e sulle piattaforme disponibili alla fine si è optato per Transkribus, piattaforma derivata da due progetti europei, tranSkriptorium e READ (Recognition and Enrichment of Archival Documents), e gestita oggi da una società cooperativa, readcoop. La scelta è stata determinata da un lato dalla facilità di accesso (iscrizione con account utente, senza necessità di disporre di potenza computazionale particolare o know-how informatico approfondito), dalla offerta di una gamma di strumenti, dalla possibilità di testare il programma in maniera gratuita e dalla disponibilità di linee guida e di un gruppo social di aiuto. Le trascrizioni realizzate sono esportabili in diversi formati, tra cui anche XML/TEI, mentre i modelli si possono condividere all’interno della piattaforma con altri utenti Transkribus.
Dopo aver appurato che tra i modelli pubblici e non pubblici della piattaforma non ne esistevano di adatti alla scrittura corsiva di Mauriello e che pertanto si doveva procedere all’allenamento di un modello specifico, si sono scelte per la ground truth pagine differenti tra loro sia in termini di layout sia in termini di contenuti tenendo conto del vocabolario, stato di conservazione e provenienza da diversi registri, in modo tale da garantire una distribuzione omogenea per tutti gli anni di attività di Marino Mauriello. Contemporaneamente si sono sviluppati i criteri di trascrizione, basandosi principalmente sulle esperienze degli altri utenti (vedi ad es. ) e sulle raccomandazioni nelle linee guida della piattaforma; tali input ci hanno indotto ad adottare una trascrizione in alcuni punti più vicina alla resa del notaio (ad esempio per quanto riguarda interpunzione, maiuscole e la separazione delle parole). Contrariamente a quanto stabilito dalle consuetudini nel campo delle edizioni critiche per la trascrizione abbiamo scelto di osservare la separazione delle righe, come spiegato in precedenza, in maniera che ogni riga nella riproduzione fosse abbinata a una riga della trascrizione.
Flusso di lavoro
In seguito si è proceduto all’upload delle riproduzioni esistenti, da un lato per verificare la necessità di un pretrattamento, dall’altro lato per testare il funzionamento della segmentazione, mentre parallelamente si trascrivevano le pagine scelte senza utilizzare la piattaforma. Al termine di queste operazioni i risultati del testing della Layout Analysis e una prova d’inserimento di testo hanno evidenziato i vantaggi di un inserimento manuale delle trascrizioni, in quanto questa procedura offriva la possibilità di effettuare in contemporanea un controllo della segmentazione e di rimediare in questa maniera ad eventuali errori di riconoscimento di righe. In questa fase si è anche proceduto alla aggiunta di markup, inizialmente prevista solo per lettere cancellate (<hi rend="strikethrough:true;">) che la rete può riconoscere nonostante la cassazione. Per testo in apice (<hi rend="superscript:true;">), per gli spazi lasciati in bianco dal notaio (<gap/>), per letture incerte (<unclear>) e per le aggiunte dell’editore (<supplied>) abbiamo esteso l’operazione di marcatura, anche se al momento la rete neurale in allenamento non tiene ancora conto di questi tags, ma potrebbe verosimilmente farlo in futuro.
Una volta conclusa la costituzione della ground truth ha avuto inizio la fase dell’allenamento del modello. Transkribus è dotato di due motori per il riconoscimento automatico di scrittura: HTR+ (basato su Tensorflow) e Pylaia (basato su Pytorch), ed entrambi sono stati sperimentati con diverse ripartizioni delle pagine della ground truth in training e validation set. I risultati sono stati documentati e valutati e si è discusso sul come procedere per migliorarli, fase che è tuttora in corso di svolgimento.
Risultati preliminari e prossimi passi
Per quanto riguarda l’acquisizione delle riproduzioni la piattaforma si è mostrata relativamente flessibile; anche le fotografie realizzate con mezzi meno sofisticati possono dare dei risultati decenti, ammesso che siano a fuoco in tutte le loro parti. Un pretrattamento delle riproduzioni non è stato necessario. L’analisi del layout si è rivelata ancora una volta la fase cruciale del processo e i passaggi chiave, come ci si attendeva, si sono concentrati nelle fasi del riconoscimento di inziali, delle annotazioni marginali e delle linee in caso di sovrapposizione di righe di scrittura. Una difficoltà inaspettata è venuta invece dalla limitata precisione nel riconoscimento di inizio e fine rigo alla quale abbiamo sopperito con correzioni manuali e con una funzione di Transkribus che permette di estendere per un determinato valore a destra e a sinistra tutte le righe di una pagina. Va addotta invece alla natura del materiale la frequente aggiunta di righe superflue a causa della sovrapposizione di tratti ascendenti e discendenti, ma soprattutto a causa dei segni abbreviativi in forma di linea o letterine, presumibilmente frainteso per effetto delle correzioni in interlinea.
La ground truth con la quale abbiamo allenato diversi modelli ammonta a 38 pagine con circa 1,300 linee di testo, per un ammontare complessivo intorno alle 20,100 parole. La sperimentazione realizzata con l’ausilio di diverse ripartizioni in set di allenamento e set di validazione, ricorrendo a diverse composizioni del set di validazione e a due reti neurali diverse, da un lato ha confermato alcune delle nostre aspettative, soprattutto per quel che riguarda le maggiori difficoltà di riconoscimento delle parti in volgare, delle maiuscole e delle cifre arabe a causa della loro scarsa occorrenza, ma abbiamo osservato anche la confusione di determinate lettere, sia simili come la s lunga e la f, la n e la u, sia dissimili come l e t, n e h e così via. Presumibilmente da attribuire allo scioglimento delle abbreviazioni sono le aggiunte di lettere non presenti nella parola o di lettere soprattutto a inizio rigo, probabilmente dovute all’occorrenza di queste in altre righe, dato che l’approccio di Transkribus è line-based. Lo scioglimento delle abbreviazioni in sé dà risultati eterogenei, anche dipendenti dalla incidenza della abbreviazione. In linea di massima lo scioglimento di contrazioni e di troncamenti crea difficoltà rilevanti, nel primo caso il compendio può anche rimanere tale o essere sciolto in una parola non corretta, mentre nel secondo lo scioglimento di abbreviazioni non univoche si verifica probabilmente su base statistica, soprattutto in quelle circostanze in cui il contesto è identico. Nel caso di una parola poco chiara, marcata con unclear, il modello ha suggerito un’ipotesi di lettura valida. In alcune situazioni si sono potuti anche individuare ed eliminare errori umani nella ground truth. I risultati migliori dei modelli con un set di validazione di 10% sono per Pylaia una CER 2,6% sul training set con 6,9% sul validation set; mentre per HTR+ i valori corrispondenti sono 3,5%/5,91%, percentuali che fanno pensare che un aumento della ground truth può migliorare i risultati, anche considerando l’alta percentuale di parole abbreviate.
Le strategie di miglioramento che attualmente sono in corso di realizzazione riguardano diversi campi: da un lato puntiamo sul cambiamento dei parametri dell’allenamento che in Transkribus riguardano soprattutto Pylaia (che offre maggiori possibilità di intervento); dall’altro lato stiamo lavorando a un aumento della ground truth correggendo in gruppo le trascrizioni automatiche prodotte per uno dei registri dall’ultimo modello, per poi procedere all’allenamento di un modello nuovo. Il team sta anche considerando l’implementazione di un tagging delle sole abbreviazioni non univoche per le pagine della ground truth e un eventuale post-processing linguistico, anche alla luce delle recenti pubblicazioni di e sull’argomento.
Per il momento il progetto ha generato, oltre alle trascrizioni e ai modelli, una bibliografia in Zotero e la documentazione riguardanti i flussi di lavoro e le analisi delle varie fasi della sperimentazione con l’intenzione di creare un corpus di dati aperti da mettere a disposizione della ricerca a fine progetto.
References
Camps, Jean-Baptiste, Chahan Vidal-Gorène, and Marguerite Vernet. 2021. Handling Heavily Abbreviated Manuscripts: HTR Engines vs Text Normalisation Approaches. In Document Analysis and Recognition – ICDAR 2021 Workshops, edited by Elisa H. Barney Smith and Umapada Pal, 306–16. Lecture Notes in Computer Science. Cham: Springer International Publishing. https://doi.org/10.1007/978-3-030-86159-9_21.
Capobianco, Samuele, and Simone Marinai. 2017. DocEmul: A Toolkit to Generate Structured Historical Documents. In The 14th IAPR International Conference on Document Analysis and Recognition - ICDAR 2017, 1:1186–91. Piscataway, NJ: IEEE. https://doi.org/10.1109/ICDAR.2017.196.
Colesanti, Gemma T., and Eleni Sakellariou. 2022. Le note storiche di Marino Mauriello notaio di Benevento (secoli XV-XVI).Nuova rivista storica 106 (1): 247–86. https://doi.org/10.1400/286784.
Gabay, Simon, Jean-Baptiste Camps, Ariane Pinche, and Claire Jahan. 2021. SegmOnto: Common Vocabulary and Practices for Analysing the Layout of Manuscripts (and More). In 1st International Workshop on Computational Paleography (IWCP@ICDAR 2021). Lausanne. https://hal.archives-ouvertes.fr/hal-03336528.
Hodel, Tobias, David Schoch, Christa Schneider, and Jake Purcell. 2021. General Models for Handwritten Text Recognition: Feasibility and State-of-the Art. German Kurrent as an Example.Journal of Open Humanities Data 7 (July): 13. https://doi.org/10.5334/johd.46.
Journet, Nicholas, Muriel Visani, Boris Mansencal, Kieu Van-Cuong, and Antoine Billy. 2017. DocCreator: A New Software for Creating Synthetic Ground-Truthed Document Images.Journal of Imaging 3 (4): 62. https://doi.org/10.3390/jimaging3040062.
Liu, Cheng-Lin. 2020. New Frontiers of Document Image Analysis and Recognition. Keynote Speech presented at the 2nd International Conference on Pattern Recognition and Artificial Intelligence (ICPRAI 2020), Zhongshan City, China, October 20. http://www.nlpr.ia.ac.cn/liucl/DIAR-ICPRAI2020.pdf
Lombardi, Francesco, and Simone Marinai. 2020. Deep Learning for Historical Document Analysis and Recognition – A Survey.Journal of Imaging 6 (10): 110. https://doi.org/10.3390/jimaging6100110.
Muehlberger, Guenter, Louise Seaward, Melissa Terras, Sofia Ares Oliveira, Vicente Bosch, Maximilian Bryan, Sebastian Colutto, et al. 2019. Transforming Scholarship in the Archives through Handwritten Text Recognition: Transkribus as a Case Study.Journal of Documentation 75 (5): 954–76. https://doi.org/10.1108/JD-07-2018-0114.
Philips, James, and Nasseh Tabrizi. 2020. Historical Document Processing: A Survey of Techniques, Tools, and Trends: In Proceedings of the 12th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, 341–49. Budapest, Hungary: SciTePress - Science and Technology Publications. https://doi.org/10.5220/0010177403410349.
Piñol, Daniel. 2021. El notariado en el Mediterráneo Occidental medieval: a propósito de un proyecto de investigación.Studi di storia medioevale e di diplomatica - Nuova Serie, November, 319–34. https://doi.org/10.17464/9788867743780_13.
Romero, Verónica, Alejandro H. Toselli, Enrique Vidal, Joan Andreu Sánchez, Carlos Alonso, and Lourdes Marqués. 2019. Modern vs Diplomatic Transcripts for Historical Handwritten Text Recognition. In New Trends in Image Analysis and Processing – ICIAP 2019, edited by Marco Cristani, Andrea Prati, Oswald Lanz, Stefano Messelodi, and Nicu Sebe, 103–14. Lecture Notes in Computer Science. Cham: Springer International Publishing. https://doi.org/10.1007/978-3-030-30754-7_11.
Schwarz-Ricci, Vera Isabell. 2022. Il riconoscimento automatico di scrittura per documenti storici. Rapporto tecnico. Napoli: Istituto di Scienze del Patrimonio Culturale, Consiglio Nazionale delle Ricerche. https://doi.org/10.5281/zenodo.6369959.
Di seguito si discute del riconoscimento di scrittura offline su riproduzioni di documenti storici e non viene considerato il campo della online recognition, cioè il riconoscimento dal vivo, effettuato ad esempio mentre si scrive su una tavoletta grafica o un tablet. Si vedano nonché per una sintesi della storia e degli sviluppi del campo.