This paper aims to take place into the ongoing debate about the lack of digital editions of classical texts. If, on one hand, a traditional critical edition has the benefits of consistency and clarity, but it often lacks objectivity, a digital one can have more scientific ambitions of verifiability, but may have certain problems of methods and visualization. This paper offers thus a report on the preliminary stage of a native digital edition of Catullus which would take into account all the surviving witnesses, with particular focus on the complexity of the tradition and the practical and theoretical problems that an editor is forced to face while coding with TEI apparatus.
L’assenza di edizioni native digitali di testi classici a tradizione complessa ha indotto molti ad interrogarsi sulle ragioni di questa lacuna nelle DH. A fronte di alcune risposte e possibili soluzioni, questo articolo presenta un caso di applicazione di tecnologie esistenti alla tradizione manoscritta di Catullo, che si compone di circa 130 codici e presenta notevoli problemi paleografici, filologici e genetici. Il lavoro di collazione e spoglio di tutti i testimoni, portato avanti da un gruppo di ricerca afferente al CSC, ha permesso di individuare alcune delle cruces che l’editore classico si trova ad affrontare in ambiente digitale e ha altresì mostrato la distanza che separa l’edizione critica di un testo classico, così come si è canonicamente definita in seno alla filologia novecentesca, e l’edizione critica digitale di un testo classico: se da un lato infatti l’edizione critica cartacea ha una concretezza e un’uniformità che mancano a quella digitale, ma talvolta non consente la piena verificabilità dei dati, l’edizione digitale potrebbe consentire un controllo più puntuale e garantire un più alto grado di scientificità del lavoro dell’editore, permettendo di rinnovare profondamente il contesto di studi; tuttavia, gli strumenti attualmente esistenti talvolta si dimostrano inadeguati. Questo articolo offre qualche esempio e spera di stimolare una discussione proficua.
Introduzione
Il concetto di edizione critica così come si è codificato nella prassi del Lachmann e della sintesi operata dal Maas si fonda sulla ricostruzione dell’archetipo mediante la ricomposizione dei rapporti stemmatici e secondo uno sviluppo cronologico che si origina dal testo di partenza; la recensio di tutti i testimoni pervenuti, dunque, non è in grado da sola di condurre al testo originale, senza il sussidio dell’examinatio. Così rileva Montanari :
Dopo aver accennato all’opposizione fondamentale tra originale (di cui non disponiamo, o piuttosto, come si è argomentato, di cui è impossibile disporre) e copie (a nostra disposizione, ma di fedeltà più o meno dubbia), Maas non allude neppure all’astratta possibilità di ricostruire l’originale operando direttamente sulle copie che lo testimoniano (ovvero alla via largamente predominante prima della svolta comunemente denominata ‘Lachmanniana’ e sporadicamente, in vario modo, tentata nel XX secolo), bensì collega decisamente le procedure per la ricostruzione dell’originale alla previa ricostruzione del processo storico che dall’originale conduce alle copie di cui disponiamo [p. 15].
Se da un lato è innegabile la necessità di una valutazione critica, da parte del filologo ed editore, del testo scaturito dalla recensio, dall’altro si deve rilevare una tendenza piuttosto comune tra gli editori di testi classici, specie se la loro lunga tradizione è popolata da moltissimi testimoni, a non completare dettagliatamente la recensio stessa. Inoltre, di frequente, le recensiones che stanno alla base delle edizioni critiche dei classici latini non forniscono uno studio di tutti i testimoni tanto sul piano paleografico/codicologico, quanto su quello genetico, fatto salvo per i codici più importanti e antichi.
In questo contesto e in una tradizione di studi che, pur con qualche difetto di parzialità, si è stabilita intorno ad un metodo univoco, cosa possono aggiungere i tools digitali? A questa domanda, tante pubblicazioni negli ultimi anni hanno provato a dare una risposta più o meno concreta (vd. infra, ). Da ultimo, in seno a un gruppo di docenti e dottorandi del CSC-Centro Studi Catulliani dell’Università di Parma, è nata la volontà di sperimentare alcune delle tecnologie esistenti per la codifica dei testi sull’opera di un autore, Catullo, sul quale il CSC aveva già negli anni precedenti accumulato voci bibliografiche, studi specialistici e, quel che più conta, le riproduzioni di quasi tutti i testimoni diretti. Il testo del poeta veronese, fin dalla sua ricomparsa sulle soglie della stagione umanistica, è costellato di problematiche di difficile soluzione e non poche croci: gioverebbe alla scientificità della critica testuale e al lavoro dei futuri editori riuscire ad avere un panorama completo della sua tradizione testuale. Nel prosieguo dell’articolo, definite le specificità del Liber, si darà conto brevemente di quanto esistente nel campo delle DH su Catullo, delle prove eseguite dal team del CSC e delle prospettive di sviluppo.
Una tradizione complessa
Dalla metà del XX secolo la costituzione del testo di Catullo si è basata su tre codici, scritti entro la fine del XIV secolo: Oxford, Bodleian Library, Canonicianus Class. Lat. 30, indicato negli apparati come Oxoniensis o con la sigla O; Paris, Bibliothèque nationale de France lat. 14137 denominato Sangermanensis o G e il codex Romanus, o R, Vaticano, Biblioteca Apostolica Vaticana, Ottob. lat. 1829. A questi tre capostipiti, le edizioni hanno tentato variamente di ricondurre alcuni dei 131 testimoni completi o parziali, tutti composti tra XV e XVI secolo (qualcuno addirittura nel XVII).
Una estensiva ricerca di codici catulliani e loro collazione venne affrontata da W. G. Hale – scopritore di R – e dai suoi allievi già nella prima metà del secolo scorso, ma non portò mai ad una edizione critica, nemmeno da parte del suo allievo B. L. Ullman: le collazioni dei 115 codici, rintracciati dal gruppo, nei 12 anni seguenti la scoperta del codex Romanus (1896), sono ancora oggi conservate presso la biblioteca della University of North Carolina at Chapel Hill.
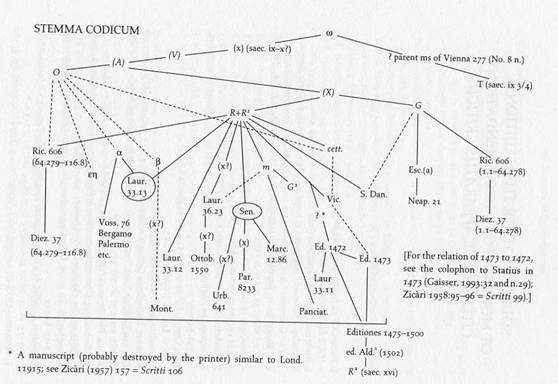
A pubblicare il testo di riferimento per Catullo sarà da R. A. B. Mynors nel 1958, per la serie degli Oxford Classical Texts, ancor oggi modello di sobrietà e sintesi per editori critici e per molti catullianisti, ma che non ebbe accesso alle collazioni del gruppo americano. Lo ebbe, invece, Douglas F. S. Thomson, che se ne servì per costituire nel 1978 una nuova edizione di Catullo con apparato positivo che, pur tentando di innovare il testo della OCT con l’inserimento di un gran numero di congetture, non convinse universalmente. I limiti di questa prima edizione furono messi in luce da M. D. Reeve , p. 179-184 e in parte risolti dalla revisione ed ampliamento della stessa pubblicato nel 1997. Lo stemma codicum proposto in questa ultima e più aggiornata edizione è il seguente:
Stemma codicum dell'edizione
Come si vede in , G ed R (con R2, vale a dire il testo di R con le correzioni di Coluccio Salutati) discendono da un testo ora perduto detto X, il quale, come O, sarebbe derivato da un sub-archetipo, detto A, a sua volta derivato dal V, il manoscritto ricomparso tra la fine del Duecento e l’inizio del Trecento nella biblioteca del Capitolo di Verona, da cui sarebbe discesa tutta la tradizione superstite. Sia X che V sono ricostruiti filologicamente, perché perduti. La recensio catulliana, a prima vista, potrebbe sembrare particolarmente adatta alla ricostituzione Lachmanniana dell’archetipo, poiché formalmente chiusa, ma così non è.
Come si evince dallo stemma di Thomson, non si è ancora potuto ricondurre pianamente una parte significativa dei codici agli antiquiores: le famiglie di codici a, b,e e h non sono ricollegate in maniera diretta ad alcun capostipite, ma recano tracce di lezioni di tipo O, come rilevarono gli studi di Marcello Zicàri . Thomson poi, non ha chiarito come l’influenza di lezioni di tipo O possa essere distinta da una condizione di totale indipendenza da X. Gli stemmi proposti in precedenza sono o incompleti o discendenti dalla disposizione proposta da Hale: comprende infatti solo una trentina di mss quello del Morghentaler e non mette in discussione, né si distacca da Hale la prefatio del Mynors .
La stessa fisionomia di X è ancora piuttosto incerta, perché l’unica via di ricostruzione filologica del testimone perduto è mediante collazione di G, R e soprattuto R2, ovvero la mano che segna varianti e correzioni sul codice romano, tradizionalmente attribuita a Coluccio Salutati, che potrebbe aver tratto i suoi interventi da X stesso: purtroppo però non vi è accordo tra gli studiosi sulle modalità di intervento e sull’attribuzione dei marginalia a R/R2. Inoltre G è solo parzialmente utile per l’operazione di confronto con R, giacché il ms non venne illuminato e corredato di note e fu, oltretutto, corretto con una copia stessa di R,scil. il ms. Marcianus Latinus XII 80 (4167).
A complicare fondamentalmente il lavoro dei filologi concorrono due fattori correlati. In primo luogo la datazione tarda degli antiquiores, in confronto ad altre tradizioni testuali di autori latini. O, infatti, privo di datazione interna, dovrebbe esser stato composto tra il 1350 e il 1375, dunque poco prima di G, scritto da Antonio da Legnago nel 1375, al quale segue temporalmente R, copiato a Firenze per conto, e sotto la supervisione, di Coluccio Salutati. Solo il florilegio tuaneo, che però comprende il solo c. 62, ci testimonia direttamente qualcosa della trasmissione di Catullo nel Medioevo, periodo in cui molto poco sappiamo di quanto circolasse e fosse letto il poeta veronese. Il viaggio del Liber dall’antichità all’età moderna ha seguito buie rotte sottomarine e solo molto tardi è emerso in superficie, a Verona, in testimone unico, andato forse perduto ben prima che gli umanisti potessero capirne l’importanza. Studiare la protostoria della raccolta di Catullo significa, dunque, rintracciare deboli segnali radar, avanzando spesso alla cieca, con tutti i rischi che ciò comporta: opera di scandaglio attenta e recente si deve a D. Kiss , 125-140.
In secondo luogo, nella tradizione di Catullo i fenomeni di contaminazione orizzontale tra i rami dello stemma sono molto frequenti, proprio in conseguenza del periodo in cui iniziò a circolare ed essere letto. Gli umanisti accorti, è noto, prediligevano la copia da più esemplari e non avevano molti riguardi nell’interpolare, correggere ex ingenio ed introdurre congetture nei testi antichi . Anche laddove il copista quattrocentesco non sia colto o interessato alla cura filologica della copia, si rilevano strane aporie che consiglierebbero cautela nel liquidare troppo rapidamente i recentiores come descripti o figli corrotti di una tradizione più fededegna. L’alta incidenza della contaminazione nella tradizione di Catullo è stata solo in piccolissima parte tracciata e soltanto una ricerca automatica e completa delle varianti trasmesse dai 129 codici completi del testo di Catullo potrebbe forse permettere di superare l’impasse, nonché di retrodatare alcune di quelle che si ritengono - a torto - congetture degli editori a stampa , , , , , .
Edizioni native digitali e classici
In un suo contributo del 2012, Paolo Monella appurava l’esistenza di una grave lacuna nell’ambito delle Digital Humanities: la totale mancanza di un’edizione critica di un testo letterario classico - greco o latino - completamente digitale. Le asserzioni dello studioso, fondate su una rassegna dei progetti di ricerca elencati sul sito Digital Classicist Wiki, sono state di fatto confermate da un’ulteriore indagine condotta da Massimo Magnani , precipuamente sul versante dei testi antichi greci, sulla base dei dati ricavati dal Catalogue of Digital Editions.
Restringendo il campo di ricerca alla sola latinità classica e combinando i risultati ottenuti dallo spoglio dei due cataloghi summenzionati, si osserva che, ad oggi, la situazione è decisamente sconfortante: tuttora non c’è una sola opera dalla tradizione testuale complessa che sia stata fatta oggetto di un’edizione nativa digitale, ossia basata su una trascrizione integrale di tutti i testimoni diretti in formato digitale, e provvista di un apparato generato dalla collazione automatica dei testimoni stessi.
Alcuni dei progetti esistenti riguardano fonti documentarie, trasmesse da un unico testimone edito in forma diplomatica (è il caso del database di tavolette di Vindolanda o della raccolta di iscrizioni della Tripolitania). D’altra parte, le poche edizioni digitali di testi letterari in questo ambito si discostano - del tutto o in parte - dal tipo di testo critico precedentemente descritto. A titolo d’esempio, il portale Curculio, curato da Michael Hendry,presenta una semplice trasposizione in formato HTML di un’edizione critica tradizionale di alcuni testi poetici; il database Perseus Digital Library è costituito da una serie di edizioni codificate in XML, che però - al momento - presentano solo sporadicamente le lectiones dei vari testimoni; infine, l’ambizioso e valido progetto Musisque Deoque, che si propone di «creare un unico database della poesia latina, integrato da apparati critici ed esegetici elettronici», offre tuttavia una semplice codifica in linguaggio TEI/XML di un testo di riferimento già pubblicato in formato cartaceo, corredato da un apparato di varianti selezionate dall’editore.
La penuria di attività di ricerca e di risultati in quest’ambito è imputabile, secondo Monella, a un disinteresse, diffuso tra i filologi classici, nei confronti degli strumenti e delle possibilità offerte dal medium digitale; questa presa di posizione deriverebbe principalmente da tre motivazioni, più o meno oggettive :
Mancanza di tempo: non solo la codifica in linguaggio XML, ma la stessa formazione informatica che il progetto di un’edizione nativa digitale richiederebbe ad un filologo classico, abituato a metodologie e strumenti differenti, sono sovente considerate troppo dispendiose in termini di ore di lavoro.
Mancanza di fondi: una digitalizzazione completa di un testo a partire dalla trascrizione dei singoli testimoni - specialmente nel caso di tradizioni complesse o soggette a una forte contaminatio - è un’operazione che necessita di ingenti finanziamenti, sia per la creazione e l’aggiornamento di sistemi di codifica e di visualizzazione, sia per il reclutamento di studiosi e di figure professionali.
Erronea percezione di una scarsa necessità: la giusta convinzione che l’obiettivo ultimo del filologo sia la constitutio textus (la ricostruzione del testo originale voluto dall’autore) porta alcuni studiosi di ambito classico a ignorare o a sottovalutare la possibilità di controllare a piacimento, attraverso la collazione automatica dei testimoni precedentemente trascritti, l’intera gamma di varianti, anche quelle di età medievale e umanistica, considerate spesso a priori erronee o deteriori. In realtà, i vantaggi che un’edizione critica completamente digitale potrebbe apportare sono legati alla facoltà di costituire e perfezionare con maggiore precisione uno stemma codicum, avendo sott’occhio il quadro completo delle lezioni delle fonti; al contempo, un lavoro di questo tipo consentirebbe di prendere in esame nel dettaglio un singolo ramo della tradizione o addirittura un singolo manoscritto, inteso come testimonianza della ricezione del testo originario in un dato momento storico.
Un tentativo di progresso, nonostante queste non trascurabili difficoltà, è rappresentato da un progetto ideato nel 2015 da Ermanno Malaspina: lo studioso si propone infatti di realizzare un’edizione critica totalmente digitale del Lucullus di Cicerone, basata sulla codifica di tutti i 74 testimoni del testo secondo le linee-guida TEI e su principi filologico-ecdotici; il risultato auspicato sarebbe una pagina web dotata di testo, di apparato critico e di un sistema di visualizzazione parallela, tanto delle varianti per ogni lezione accolta, quanto del testo completo dei singoli testimoni. Il lavoro, che promette di mettere alla prova le «possibilità che la marcatura TEI attuale riesca a dar conto della complessità di tradizioni come queste», risulta però ancora in fase embrionale.
L’operazione nata in seno al Centro Studi Catulliani, a cui si accennava nell’introduzione, vorrebbe agire in maniera similare sul testo di Catullo, andando al contempo ad affiancare e integrare il portale creato da Dániel Kiss, Catullus Online, che resta imprescindibile per ogni studioso del poeta di Verona. Il sito, realizzato tra il 2009 e il 2013 nell’ambito del progetto An Online Repertory of Conjectures for Catullus portato avanti dall’Università Ludwig Maximilian di Monaco, presenta un’edizione critica dei carmi di Catullo, corredata di un apparato – posizionato a fianco delle poesie e contenente, nelle intenzioni dell’editore, tutte le congetture pubblicate a stampa dall’editio princeps del 1472 in avanti – e arricchita di una panoramica delle citazioni antiche di Catullo più significative e di immagini in alta qualità di O e G.
Un’opera encomiabile, la quale, oltre a fornire ai suoi fruitori una mole notevolissima di informazioni, sfrutta molte delle opportunità offerte dalla tecnologia digitale – come la possibilità di visualizzare solo la parte di apparato riferita ai versi a cui si è interessati e quella di circoscrivere le ricerche a una sezione specifica della struttura (testo, apparato, testimoni) – e consente all’editore di tenerla il più possibile aggiornata, operazione che, naturalmente, non è praticabile per il supporto cartaceo se non attraverso una nuova edizione. Ma, per quanto potenziato di tali strumenti e al momento ineguagliato per la completezza delle informazioni offerte, il risultato appare ancora, nel suo complesso, come una trasposizione digitale di un’edizione cartacea.
Il CSC
La sfida del Centro Studi Catulliani è appunto quella di superare la concezione di un semplice repertorio di congetture e varianti per creare un’edizione critica che sia davvero digitale, che renda cioè disponibile e visibile a colpo d’occhio – attraverso la codifica in XML/TEI di tutti i manoscritti – l’intera tradizione catulliana. Ciò consentirebbe a qualunque filologo si voglia accostare al testo di Catullo di avere a disposizione in fase di constitutio textus ogni singola variante e di poter tracciare la storia di ogni lemma all’interno dell’intricata trasmissione del testo catulliano.
Il progetto è sicuramente ambizioso e presenta problematiche specifiche di non poco conto, quali ad esempio la scarsa leggibilità di alcuni codici, la difficile rappresentazione in fase di codifica della stratificazione degli interventi delle mani successive e, in alcuni casi, il mutamento dell’ordine dei versi o dei carmi. A latere di tali questioni legate allo stato dei testimoni, fronteggiabili solo parzialmente con il perfezionamento delle competenze del team, se ne sono rilevate altre sul piano epistemologico, tecnico e operativo, che hanno rese necessarie alcune scelte preliminari.
Circa gli strumenti, si è deciso di utilizzare quelli che, per diffusione e immediatezza di utilizzo, risultassero più semplici da reperire e padroneggiare anche per chi non avesse una formazione specifica nell’àmbito dell’umanistica digitale o dell’informatica in senso lato, vale a dire il metodo della segmentazione parallela previsto dal protocollo TEI per l’apparato critico (codifica) e la versione beta di Edition Visualization Technology (EVT) per l’interfaccia grafica.
Circa i criteri di lavoro, si è preferito, almeno in questa fase preliminare, codificare le varianti una ad una, da un lato per ottenere un prospetto fedele alla situazione dei manoscritti, senza categorizzazioni a priori che potrebbero derivare dall’utilizzo di strumenti specifici quali i gruppi di varianti, e dall’altro per familiarizzare con tutti gli aspetti dell’attività di collazione al suo livello più basso. Si è scelto cioè di apporre e taggare le varianti testimoniate dai manoscritti all’interno (in-line method) di un testo base già codificato in XML-TEI, coincidente in gran parte con l’edizione critica di Douglas Thomson 1997; metodologicamente, si vorrebbe costituire un apparato positivo su un testo di riferimento, in cui tutte le varianti della tradizione, tratte dai singoli testimoni, vengano rappresentate; si giungerebbe così a sovrapporre, nello stesso file, testo editato, varianti e commento: l’operazione è ovviamente ben più rapida rispetto alla trascrizione diplomatica di tutti i testi e di più sicura confrontabilità, specie se il lavoro è portato avanti da un team di filologi. Le peculiarità grafiche, fonetiche e paragrafematiche di alcuni ms inficerebbero forse la possibilità di collazionarli automaticamente con altri testimoni: ragion per la quale, sono state normalizzate grafie distinte quali ę / æ / œ; et / &.
D’altro canto la medesima collazione, tanto su carta quanto su foglio XML, è esposta ad errori di lettura, di cattiva traslitterazione o di distrazione umana, che pongono legittimi interrogativi sulla totale verificabilità dei dati raccolti. Tuttavia, al momento, la trascrizione dei testi con tecnologie quali OCR e Deep Learning non hanno ancora raggiunto percentuali d’errore soddisfacenti*; inoltre, un volume di testo di poco più di duemila versi, su manoscritti redatti con grafie assai differenti, non consente la selezione di un campione sufficientemente ampio per addestrare la macchina alla lettura. Questa strada, tuttavia, potrà essere percorsa quando sarà il momento di includere nella collazione anche le edizioni a stampa.
Le valutazioni metodologiche fatte, del tutto arbitrarie, dipendono sia dall’interesse principale verso la gestione simultanea di testimoni, più che verso la loro individuale edizione diplomatica, sia dalla scelta di EVT 2.0 come interfaccia di visualizzazione, che allo stato attuale richiede necessariamente una codifica a segmentazione parallela. Inoltre, al momento è sembrato più urgente testarne le nuove funzionalità di apparato critico, ancora in via di sviluppo, piuttosto che quelle di edizione diplomatica e interpretativa, nelle quali sono stati ottenuti ottimi risultati già con la versione 1.
Stanti queste premesse, il lavoro preliminare effettivamente svolto ha fatto emergere difficoltà nella gestione delle varianti tanto a livello di codifica in ambiente TEI quanto di visualizzazione.
Un caso abbastanza esemplare è a Catull. 3,16 (O factum male! O miselle passer!). A partire dai testimoni più antichi, la seconda parte del verso si presenta nelle seguenti forme:
bonus ille passer
bellus ille passer
bonus passer ille
o miselle passer
passer o miselle.
Una serie di varianti ed inversioni rendono la codifica a segmentazione parallela abbastanza intricata: vi è la coppia bonus / bellus, quella bonus ille / o miselle, e le inversioni ille passer / passer ille e o miselle passer / passer o miselle. Anche se è stato possibile organizzare l’apparato annidando diversi marcatori <app>, l’inversione passer ille presenta comunque significativi problemi di overlap e rende necessario porla a un livello più esterno di quello che le spetterebbe, allo stesso piano di o miselle passer, causando inoltre una ridondanza di passer e di ille. Se dal punto di vista di output la resa è comunque accettabile, dal punto di vista ontologico e cladistico la codifica è lontana dalla situazione dei manoscritti, in cui tale variante è figlia della lezione bonus ille passer.
Similmente problematico, anche se per motivi diversi, è l’incipit del c. 17, (O Colonia, quae...) che si presenta molto corrotto.
oculo in aque
oculo inaque
o culonia que
o culoniaque
aculonia que
In questo caso il problema con la segmentazione parallela nasce dal diverso numero di lemmi (ora due, ora tre), e dalla loro diversa articolazione. Volendo attenersi a questo sistema di codifica, si finisce per creare anche in questo caso varianti ridondanti di un macro-lemma O Colonia, quae, la cui relazione genetica risulta inevitabilmente appiattita.
Tali problematiche rendono l’utilizzo ortodosso del metodo parallel segmentation abbastanza ostico. Al momento, due sembrano le strade. Da un lato, naturalmente, il passaggio al sistema con doppio rinvio nel testo (Double end-point): questo sistema ha già dimostrato efficacia nel lavoro di Ermanno Malaspina (vd. supra, ), ma è ancora troppo poco supportato per consentirne un utilizzo autonomo da parte di studiosi in corso di formazione. Mancano, infatti, strumenti di verifica e monitoraggio della codifica, come possono essere il Critical Apparatus Toolbox, oppure il già citato EVT: lo stesso progetto di Malaspina, per questa fase, ha dovuto avvalersi di «un prototipo in Javascript che permette la visualizzazione dei dati e il controllo di eventuali errori di taggatura» , 61-62. L’utilizzo di questo sistema coinciderebbe, pertanto, con la progettazione ex novo di uno strumento di visualizzazione e codifica, richiedendo pertanto un progetto decisamente più articolato in termini di fondi, di personale e di strumentazione; un rischio di questo approccio, poi, sarebbe quello di produrre una tecnologia profilata alle esigenze del testo catulliano e di conseguenza troppo legata al progetto, con il rischio di essere poco reinvestibile altrove. Uno strumento confinato al progetto di Parma, e dunque non aperto ad apporti dall’esterno, richiederebbe uno sforzo considerevole per il suo mantenimento e aggiornamento.
Da un altro lato, è la proposta ricevuta per litteras da Roberto Rosselli Del Turco circa l’utilizzo, nell’àmbito dell’apparato a segmentazione parallela, di un marcatore <w> dotato di un proprio <xml:id> per ogni unità di parola, ai quali si richiameranno ulteriori sotto-apparati tramite gli attributi @from e @to. Questa soluzione potrebbe gestire tranquillamente il problema dell’overlap in casi come in Catull. 3,16, in cui tutto sommato quantità e qualità delle varianti rimangono pressoché costanti, tuttavia rimane ancora problematica la gestione di situazioni di divisione delle parole come a 17,1.
Approcci alternativi
Ovviamente è possibile immaginare approcci diversi da quello sopradescritto: si potrebbero ad esempio trascrivere manualmente i testimoni, secondo norme comuni finalizzate alla semplificazione e al trattamento delle peculiarità dei manoscritti, a cui si faceva riferimento poc’anzi, evitando l’immediata marcatura in TEI delle varianti, per giungere, mediante una serie di elaborazioni automatiche dei testimoni, alla loro collazione automatica. Si avrebbero dunque tanti files XML quanti sono i testimoni che poi un singolo file XSLT avrebbe il compito di collazionare, secondo quanto auspicato da Monella (vedi su). Il workflow, ben più complesso e articolato, prevedrebbe tempi più lunghi, ma permetterebbe di arricchire le informazioni basilari con più metadati e di garantire una maggior durabilità degli stessi:
trascrizione semi-diplomatica di ciascun testimone. Questa prima rappresentazione del manoscritto, scevra di taggatura, commento e note critiche, costituirebbe una base di lavoro per analisi di tipo differente sui singoli testimoni della tradizione;
PoS tagging delle 130 trascrizioni mediante software dedicato, ad esempio Tree-tagger;
acquisizione, mediante editor XML, dei documenti tokenizzati: si otterrebbero dunque automaticamente circa 130 files XML in cui ciascun morfema è distinto e taggato con <w>;
adeguamento dei files alla sintassi TEI e specificazione delle lezioni di prima mano, seconda o terza con relativi tags (<rdg>, <hand>, <rdgGroup> e così via).
arricchimento del testo con notazione critica dei loci problematici, scioglimento dei compendi e commenti dell’editore; situazioni complesse potrebbero qui essere trattate con il metodo proposto da Del Turco;
creazione di un solo file XSLT che operi su tutti i documenti XML-TEI così creati e di un protocollo CSS per l’editing del testo.
manipolazione con JavaScript della maschera HTML che presenti un testo base in cui i lemmi interessati da varianti siano interrogabili con semplice click e forniscano in una finestra pop-up non solo le varianti stesse di tutta la tradizione, ma anche note critiche, paleografiche e commenti che l’editore avrà aggiunto ad locum (supra p. 5).
Il processo presenta i vantaggi sopracitati nella pulizia e nel dettaglio del workflow, nonché nel fatto di garantire una più vasta gamma di tipologie conservative dei dati (.txt/.docx/.xml/.html), ma se possibile complica la gestione della suddivisione errata di stringhe alfabetiche continue, in cui l’entità <word> corrisponde nel corso della tradizione a porzioni di testo differenti, spesso non corrispondenti a parole di senso. Lo stesso problema si porrebbe con un database relazionale, che connetta all’occorrenza le lezioni di ciascun testimone in una data posizione di un dato verso. In questo caso il workflow potrebbe partire da una serie di files excell, tanti quanti sono i mss, che organizzino i carmi in fogli e i singoli versi in celle. La struttura del database attribuirebbe ad ogni entità testuale contenuta nella cella (scil. posizione nel verso) un certo attributo identificatore e delle relazioni fisse, che potranno poi essere interrogate in un secondo momento. Sempre in un secondo momento i dati così archiviati potrebbero essere acquisiti da un editor XML (in una forma già parzialmente tokenizzata) e rielaborati per una edizione dei singoli testimoni. Tuttavia, come si accennava, la rigidità della griglia in cui si inserirebbero i versi renderebbe comunque complicata la gestione di situazioni di divisione delle parole come a 17,1. Questi due metodi hanno un taglio primariamente documentario e solo in un secondo momento possono essere adeguati ad un approccio editoriale ed arricchiti di note critiche: la parte della recensio rappresenta lo sforzo primo e principale.
Un approccio ulteriormente diverso alla questione è offerto dall’innovativo web-based editor CEED, nato nell’ambito del progetto ERC PhiBor e finalizzato alla creazione di edizioni critiche digitali. Gli scopi di CEED possono essere riassunti fondamentalmente in tre punti:
fornire uno strumento user-friendly che permetta anche agli studiosi con limitate conoscenze tecniche di produrre autonomamente un’edizione digitale. Ogni operazione che si compie sul testo (inserimento di varianti, segnalazione di seconde mani, ecc.) viene condotta attraverso l’utilizzo di comandi intuitivi, che lasciano la fase di codifica esclusivamente alla macchina.
favorire la cooperazione, risolvendo i problemi di carattere organizzativo, comunicativo e di uniformità. Spesso, infatti, ci si trova di fronte a tradizioni talmente complesse e a un tale numero di manoscritti che è impensabile riuscire a portare a termine un’edizione critica senza creare un gruppo di lavoro. Questo comporta da un lato la necessità di definire i ruoli reciproci e aggiornarsi periodicamente sullo stato dei lavori, dall’altra il forte rischio di una scarsa uniformità nel risultato finale, che rende più complesso il lavoro di revisione e allunga notevolmente i tempi di realizzazione. CEED permette di lavorare sul testo contemporaneamente rendendo visibili e tracciate le operazioni compiute da ciascun soggetto coinvolto nel progetto.
risolvere i problemi di overlap. Per lavorare su una porzione di testo, basta selezionarla e poi operare attraverso gli strumenti forniti dall’editor. Una volta effettuate le modifiche, la sezione interessata dall’intervento sarà evidenziata dall’uso di parentesi colorate e dal momento che l’operazione può essere eseguita sulla stessa parte di testo più di una volta, i lemmi possono quindi intersecarsi tra loro.
Poiché il progetto è ancora in fase di sviluppo, e dunque non utilizzabile dal pubblico, non vi è una trattazione dettagliata di tutti i suoi aspetti operativi; tuttavia, una succinta descrizione della tecnologia impiegata è presente nel book ofabstracts della conferenza AIUCD 2018 tenutasi a Bari lo scorso gennaio, durante la quale è stato presentato il progetto: «CEED is being developed as an Angular application written in Typescript. The application communicates with a REST service that uniforms the internal JSON data model and the related operations. The REST service manages the manuscript images and the critical edition data. The images are stored inside an International Image Interoperability Framework compliant image server. A BaseX database stores the critical edition data» , 97. In sostanza, un’applicazione web (WYSIWYG) che attraverso un’interfaccia ospita, conserva e gestisce i progetti d’edizione dell’utente, trattando i dati secondo un modello JSON interno e consentendo di esportarne un documento XML/TEI P5 con marcatura a doppio ancoraggio nel testo. Senz’altro uno strumento del genere, che richiede pochissimo addestramento da parte degli utenti, può essere un’arma a doppio taglio: se da un lato, infatti, offre molte funzionalità alla portata di tutti, dall’altro rischia di ridurre l’operazione di codifica ad un mero atto meccanico da parte di personale non preparato, inconsapevole delle dinamiche interne della codifica e di conseguenza non in grado di comprendere le problematiche che possono venirsi a creare (né tantomeno di risolverle). Un problema di questo tipo, tuttavia, per quanto concreto, non dipende necessariamente dalla macchina, ma dall’approccio dell’utente, che in questo caso va a considerare il documento esportato in TEI come punto di arrivo; quest’ultimo, tuttavia, è comunque un documento TEI con metodo DEPA, quindi passibile di ulteriori revisioni per renderlo conforme alle premesse di metodo che l’applicazione CEED non è stata in grado di soddisfare appieno. In buona sostanza, se utilizzato da personale con una discreta conoscenza del protocollo TEI, CEED può essere un importante aiuto nella gestione del metodo a doppio ancoraggio nel testo, che può risultare abbastanza scomodo da maneggiare su testi particolarmente estesi.
Il CSC è in contatto con il gruppo di sviluppatori di CEED e ha intenzione di testare alcune funzionalità dello strumento sulla tradizione catulliana. In particolare, ad esempio, si intenderebbe verificare che CEED consenta la gerarchizzazione delle varianti nell’output XML. La difficoltà e varietà delle problematiche che solleva un testo classico rende difficile poter pensare che esista uno strumento in grado di risolverle tutte, ma la grafica estremamente intuitiva e la sua struttura flessibile, che concede ai programmatori di estendere facilmente le sue funzionalità, lo rendono uno strumento davvero promettente.
Quanto è distante l’orizzonte?
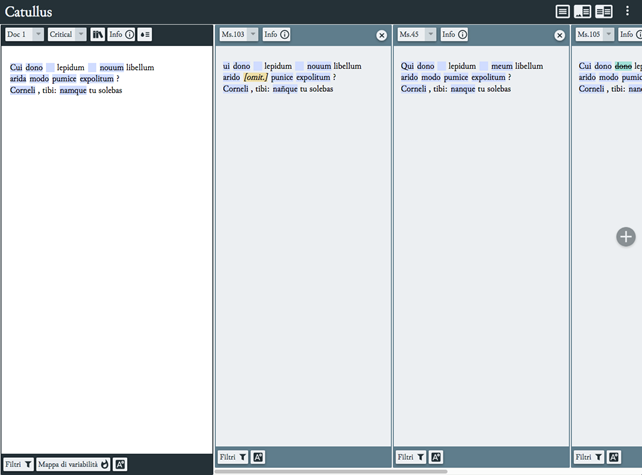
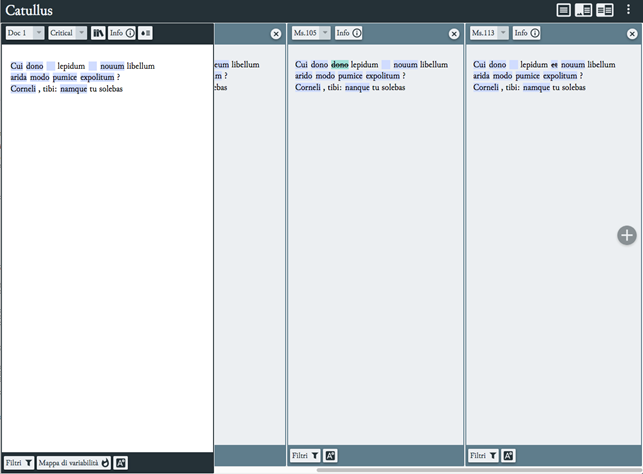
Sulla base di un primo test svolto sui primi tre versi del c. 1 di Catullo (vd. una esemplificazione dell’output, mediante EVT, in e ), si è potuto calcolare che, per terminare un progetto di sola collazione e codifica XML delle varianti del Liber trasmesse dai testimoni diretti, impiegando un team di quattro filologi classici/umanisti digitali, sarebbe necessario un lavoro di oltre tre anni a tempo pieno al lavoro. Questo, senza considerare i tempi di pulizia e verifica del codice, l’indicizzazione della bibliografia disponibile su ciascun testimone, l’eventuale insorgenza di problemi non rilevati dal test preliminare e sorvolando sul fatto che il lavoro risulterebbe in alcuni punti impreciso, poiché attualmente alcuni fatti testuali e peri-testuali non possono essere rappresentati correttamente mediante TEI o visualizzati in maniera appropriata con un software esistente. Le informazioni che si è scelto di escludere dall’esame (varianti grafiche, interventi in seconda o terza mano, titoli di componimento, eventuale illuminazione) potranno essere integrate in una seconda fase del progetto e la completezza della recensio ne è solo parzialmente inficiata. I costi umani e monetari di ciascuna attività sarebbero piuttosto consistenti e richiederebbero la collaborazione di specialisti in campi diversi: come è stato già rilevato, un progetto di edizione critica di un testo classico, dunque, per nascere, svilupparsi ed essere fruito continuativamente nel futuro difficilmente potrebbe essere gestito da un solo editore, così come finora si sono costituite le edizioni critiche nel campo della filologia classica. Da un lato, dunque, l’orizzonte sembra allontanarsi via via che ci si addentra nel progetto, poiché l’attuabilità del piano di lavoro ipotizzato dal gruppo di ricerca del CSC è contrastata dalle difficoltà insite nella codifica di un numero così ampio di testimoni, il cui testo deve essere standardizzato sufficientemente da essere collazionato da una macchina virtuale. Dall’altro, tuttavia, la natura collaborativa di un simile progetto trova terreno fertile nel contesto del CSC, dove un team di ricerca già esiste ed eredita la lunga frequentazione filologica con l’autore latino e un discreto fondo bibliografico. Si auspica, dunque, che lo spazio che separa questa fase istruttoria e sperimentale del lavoro dalla realizzazione di un’edizione critica digitale di Catullo si possa via via ridurre con l’aggiornamento o l’implementazione dei tools esistenti (modulo Critical Apparatus in P5-Guidelines for TEI e EVT) e con la collaborazione della comunità scientifica.
Esemplificazione dell’output, mediante EVT, dei primi tre versi del c. 1 di Catullo
Esemplificazione dell’output, mediante EVT, dei primi tre versi del c. 1 di Catullo
References
Afferni, Raffaella, Alice Borgna, Maurizio Lana, Paolo Monella, and Timothy Tambassi. ‘“...But What Should I Put in a Digital Apparatus?” A Not-so-Obvious Choice’. In Advances in Digital Scholarly Editing. Papers Presented at the DiXiT Conferences in The Hague, Cologne, and Antwerp, edited by Peter Boot, Anna Cappellotto, Wout Dillen, Franz Fischer, Aodhán Kelly, Andreas Mertgens, Anna-Maria Sichani, Elena Spadini, and Dirk van Hulle. Sidestone Press, 2017.
Agnesini, Alex. ‘Catull. 16,10: hispidosis, una probabile lezione negletta’. VICHIANA XI 4° serie (2009): 245–58.
Babeu, Alison. ‘Rome Wasn’t Digitized in a Day’: Building a Cyberinfrastructure for Digital Classics. Washington, DC: Counsil on Library and Information Resources, 2011.
Bausi, Alessandro, Eugenia Sokolinski, and Europäische Wissenschaftsstiftung, eds. Comparative Oriental Manuscript Studies: An Introduction ; COMSt. Hamburg: Tredition, 2015.
Bertone, Susanna. ‘Somiglianze Paratestuali in Alcuni Recentiores Catulliani (Par. Lat. 7989, Sen. H V 41, Cod. Tomacellianus, Ricc. 606, Mont. 218/109)’. Paideia: Rivista Di Filologia, Ermeneutica e Critica Letteraria: LXXI, Pars Prior, 2016, 2016.
Billanovich, Giuseppe. ‘Il Catullo Della Cattedrale Di Verona’. In Scire Litteras. Forschungen Zum Mittelalterlichen Geistesleben., edited by Sigrid Krämer and Michael Bernhard, 35–58. München, 1988.
Biondi, Giuseppe Gilberto. ‘Catullo, Sabellico (e Dintorni) e... Giorgio Pasquali. «Recentiores Non Deteriores»’. Paideia: Rivista Di Filologia, Ermeneutica e Critica Letteraria 68 (2013): 663–68.
Boot, Peter, Anna Cappellotto, Wout Dillen, Franz Fischer, Aodhán Kelly, Andreas Mertgens, Anna-Maria Sichani, Elena Spadini, and Dirk van Hulle, eds. Advances in Digital Scholarly Editing. Papers Presented at the DiXiT Conferences in The Hague, Cologne, and Antwerp. Sidestone Press, 2017.
Brink, C. O., James Diggle, John Barrie Hall, and H. D. Jocelyn, eds. Studies in Latin Literature and Its Tradition: In Honour of C.O. Brink. Supplementary Volume, no. 15. Cambridge, England: Cambridge Philological Society, 1989.
Butrica, James L. The Manuscript Tradition of Propertius. University of Toronto Press, Scholarly Publishing Division, 1984.
Cini, Monica, ed. Humanities e altre scienze: superare la disciplinarietà. Roma: Carocci, 2017.
Deegan, Marilyn, Harold Short, and Jean Anderson, eds. DRH98: Selected Papers from DRH98, Digital Resources for the Humanities Conference, University of Glasgow, September 1998. London: Office for Humanities Communication, 2000.
Del Turco, Roberto Rosselli, Giancarlo Buomprisco, Chiara Di Pietro, Julia Kenny, Raffaele Masotti, and Jacopo Pugliese. ‘Edition Visualization Technology: A Simple Tool to Visualize TEI-Based Digital Editions’. Journal of the Text Encoding Initiative, no. Issue 8 (28 December 2014). https://journals.openedition.org/jtei/1077
Faranda, Giovanna, ed. Studi in onore di Luigi Castiglioni. Vol. 2. Sansoni, 1960.
Fay, Edwin W., and Gustav Friedrich. ‘Catulli Veronensis Liber’. The American Journal of Philology 31, no. 1 (1910): 81.
Grandi, Giovanni. ‘An Hypothesis Regarding the Scribe of London, British Library Burney 133 and 343’. Paideia: Rivista Di Filologia, Ermeneutica e Critica Letteraria 71, no. Pars altera (2016): 647–60.
———. ‘Marginalia catulliani: affinità (e parentele?) fra due manoscritti quattrocenteschi (Burney 133 e Marc. Lat. XII 153)’. Paideia: rivista di filologia, ermeneutica e critica letteraria 70 (2015): 453–471.
Hale, William Gardner. The Manuscripts of Catullus. Classical Philology, 1908.
Heyworth, S. J. ‘The Manuscript Tradition of Propertius’. Edited by James L. Butrica. The Classical Review 36, no. 1 (1986): 45–48.
Kiss, Dániel. ‘The Protohistory of the Text of Catullus’. In From the Protohistory to the History of the Text, edited by Javier Velaza, 125–40. Frankfurt am Main ; New York: PL Academic Research, 2016.
Magnani, Massimo. ‘The Other Side of the River: Digital Editions of Ancient Greek Texts Involving Papyrus Witnesses’. N. Reggiani (Ed.), Digital Papyrology II: Case Studies on the Digital Edition of Ancient Greek Papyri (Berlin 2018).
Malaspina, Ermanno, and Elisa Della Calce. ‘Un’edizione digitale veramente critica di un testo classico?’ In Humanities e altre scienze: superare la disciplinarietà, edited by Monica Cini. Roma: Carocci, 2017.
Mare, Albinia C. de la, and Douglas Ferguson Scott Thomson. ‘Poggio’s Earliest Manuscripts?’ Italia Medioevale e Umanistica 16 (1973): 179–95.
———. ‘Salutati, Poggio and the Codex M of Catullus’. In Studies in Latin Literature and Its Tradition: In Honour of C.O. Brink, edited by C. O. Brink, James Diggle, John Barrie Hall, and H. D. Jocelyn, 66–86. Cambridge, England: Cambridge Philological Society, 1989.
Monella, Paolo. ‘Why Are There No Comprehensively Digital Scholarly Editions of Classical Texts?’ [Forthcoming], 2018.
Montanari, Elio. ‘La critica del testo secondo Paul Maas. Testo e commento - Elio Montanari - Libro - Sismel - Millennio medievale | IBS’, 24 April 2018.
Morgenthaler, Alfons. De Catulli codicibus. Typis expressit M. Dumont-Schauberg, 1909.
Mynors, R. A. B. C. Valerii Catulli carmina. Scriptorum classicorum bibliotheca Oxoniensis. Oxford: Oxford Univ. Press, 1958.
Nisbet, R. G. M. ‘Notes on the Text of Catullus’. The Cambridge Classical Journal 24 (ed 1978): 92–115.
Orlandi, Tito. Informatica testuale: teoria e prassi. Roma; Bari: Editori Laterza, 2010.
Pasquali, Giorgio. Storia Della Tradizione e Critica Del Testo. 2°. Firenze,: F. Le Monnier, 1952.
Thomson, D. F. S. Catullus. University of Toronto Press, 1997.
Thomson, Douglas Ferguson Scott. Catullus: A Critical Edition. University of North Carolina Press, 1978.
Ullman, Berthold Louis. ‘The Trasmission of the Text of Catullus’. In Studi in onore di Luigi Castiglioni, edited by G. Faranda, Vol. 2. Sansoni, 1960.
Vanhoutte, Edward. ‘Where Is the Editor? Resistance in the Creation of an Electronic Critical Edition’. In DRH98: Selected Papers from DRH98, Digital Resources for the Humanities Conference, University of Glasgow, September 1998, edited by Marilyn Deegan, Harold Short, and Jean Anderson, 171–83. London: Office for Humanities Communication, 2000.
Velaza, Javier, ed. From the Protohistory to the History of the Text. Studien Zur Klassischen Philologie, Band 173. Frankfurt am Main ; New York: PL Academic Research, 2016.
Tutti gli autori hanno collaborato al progetto e alla stesura dell’articolo. L’introduzione, la conclusione e la sezione 1 sono a cura di Susanna Bertone; la sezione 2 a cura di Alessandro Bettoni; la sezione 3 a cura di Giovanni Grandi e Francesco Cavalli.
G è individuato per la prima volta nel 1830 da Sillig , 262; O è stato utilizzato in apparato per la prima volta nel 1867 nell’edizione di Ellis ; R è stato scoperto nella Biblioteca Vaticana da Hale nel 1896 e, a causa del ritardo nella pubblicazione della sua collazione, è entrato a pieno titolo negli apparati solo a partire dall’edizione di Mynors .
La lista principale dei testimoni di Thomson comprende circa centotrenta testi (a questa lista se ne aggiunge una comprendente quindici voci, No. 130-145, di brevi frammenti testuali o estratti, poco significativi per la definizione dello stemma). Una più aggiornata e precisa si deve a Dániel Kiss che l’ha pubblicata in rete nel 2013 su http://www.catullusonline.org, che aggiunge Ferrara, Biblioteca Comunale Ariostea Cl. II. 156 (No. 19a), sconosciuto a Thomson, e tiene conto dell’identificazione il ms. 53, ‘formerly Phillipps 3400’ nella lista di Thomson, con Oslo, Schøyen Collection 586.
. Prima dello studioso americano, un elenco di codici catulliani si trova in Schwabe , 174.
Letture più caute vennero auspicate da Nisbet , 92-115 e Gratwick , 112-114.
Anche grazie al lavoro capillare e preciso di Butrica nella ricerca, descrizione e analisi comparativa dei codici di Properzio, che spesso coincidono con i testimoni del Liber catulliano, specie se scritti dopo la metà del XV, quando divenne uso comune copiare insieme i tre poeti d’amore romani: Catullo, Properzio, Tibullo.
In special modo vd. i contributi raccolti alle pp. 44-60 Il codice pesarese e i suoi affini; pp. 61-77 Il «cavrianeus» antaldino e i codici catulliani; pp. 79-104 Ricerche sulla tradizione manoscritta di Catullo.
La ricostruzione delle prime fasi della trasmissione del testo di Catullo si deve principalmente a Ullman , 1027-1057; determinanti i contributi di de la Mare e Thomson ; Billanovich ; McKie , .
Degno di nota per la peculiarità dell’approccio e delle linee-guida è l’Homer Multitext Project (http://www.homermultitext.org/) che, considerando ogni variante testuale come una testimonianza valida di una fase della trasmissione orale dei poemi omerici, rinuncia a fornire un apparato e a scegliere fra le lectiones; l’obiettivo è piuttosto quello di digitalizzare una pluralità di testi ritenuti equipollenti, in modo da permettere una lettura in parallelo e un’indagine al contempo sincronica e diacronica della tradizione. Per un’analisi più approfondita del progetto, cfr. Magnani .
La trascrizioneintegrale dei testimoni è la via indicata come ideale da Monella , ma vd. anche Orlandi , 115. Un approccio differente, ma egualmente valido, consisterebbe nella codifica delle sole varianti di tutte le fonti primarie, confrontate automaticamente con un testo base di riferimento, similmente a quanto consente di fare il visualizzatore XML, EVT, per il quale vd. infra, nota 28.
http://curculio.org/. I testi (Giovenale, Marziale IV, Heroides I di Ovidio, Properzio, Sulpicia e Claudiano) - sono raccolti nella sezione “My Old Texts”. Anche la nuova versione del portale, ancora in costruzione (http://www.qltp.org/), sembra non prevedere un confronto automatico tra tutte le fonti dirette - o tra le loro varianti -, precedentemente trascritte in formato digitale.
http://www.perseus.tufts.edu/hopper/. Non compare nell’elenco delle Digital Critical Editions of Texts in Greek and Latin, né nel Catalogue of Digital Editions.
Per ulteriori ragioni di diffidenza cfr. Vanhoutte , mentre per una trattazione più generale sulle problematiche e sugli approcci legati alla questione della creazione di un’edizione critica digitale cfr. Babeu , 32 ss. (https://www.clir.org/pubs/reports/pub150/)
Vd. , 25-26 e 43 ss.
Vd. Anche , 3.
Per la descrizione dettagliata del progetto si rimanda a , 60 ss.
Ivi, p. 59.
Una prova preliminare è stata effettuata nel 2015 su quattro paragrafi del testo latino: vd. ivi, p. 61.
L’Università di Parma, in formato digitale, in copia anastatica o microfilm, li possiede quasi tutti: al momento, mancano soltanto Oslo area, Schøyen Collection 586 (no. 53) e Wolfenbüttel, Herzog August Bibliothek 65.2 Aug. 8° e Gud. lat. 283 (no. 126 e 127).
Puntualmente il team ha scelto di sostituire il testo Thomson 1997 con lemmi differenti, che più propriamente si considerano letture corrette.
Il testo è quello di Thomson .
Queste e altre considerazioni sono approfondite in , che esamina proprio la differenza fra un approccio particolaristico ed uno collaborativo ed open source che possa garantire strumenti standard declinabili in contesti differenti.
Diretto da Amos Bertolacci, PhiBor ha come principale obiettivo la creazione di un inventario completo dei manoscritti dell’Ilāhiyyāt di Avicenna e di un’edizione critica digitale del suo testo.
In attesa di una documentazione più approfondita vorremmo esprimere il nostro ringraziamento ad uno degli sviluppatori, Simone Zenzaro, per la disponibilità nell’illustrarci alcune delle funzioni di CEED.