Data visualization is a powerful tool for digital scholarship yet not without its pitfalls. Based on the dissertation Visualizing Gender Balance comparing ten computer science conferences, several visualization techniques and tools undergo a critical review. The dataset underlying the visualizations contains data researchers encounter daily: bibliographic information. Analyzing larger sets of authors writing and publishing for conferences in computer science changes our perception of the gender (im)balance in this academic research area. But only a careful curation and visualization can truly reveal what goes on behind the scenes. Still the more complicated, detailed and nuanced the visualization, the harder it becomes for an untrained eye to interpret the patterns.
La visualizzazione dei dati è un potente strumento per le borse di studio digitali, ma non senza le sue insidie. Sulla base della tesi di laurea "Visualizing Gender Balance" che mette a confronto dieci conferenze di informatica, diverse tecniche e strumenti di visualizzazione vengono sottoposti a una revisione critica. Il set di dati alla base delle visualizzazioni contiene dati che i ricercatori incontrano quotidianamente: informazioni bibliografiche. L'analisi di gruppi più ampi di autori che scrivono e pubblicano per conferenze in informatica cambia la nostra percezione del (im)balance di genere in quest'area di ricerca accademica. Ma solo un'attenta cura e visualizzazione può veramente rivelare ciò che accade dietro le quinte. Ancora più complicata, dettagliata e sfumata la visualizzazione, più diventa difficile per un occhio non addestrato interpretare i modelli.
Introduction
As Virginia Valian discusses in her article Beyond Gender Schemas people generally fail to recognize gender equity problems. When people do recognize gender disparities, they often rely on four possible explanations. First, the pipeline problem refers to the decline in the percentage of women from undergraduate to graduate to professional status. Second, the child-care responsibility indicates that when child care is seen as women’s work they are more likely to become part-time workers. The third problem of different values based on gender originates in survey data suggesting that men are more willing than women to forgo a balanced personal life. Finally, the lack of acculturation refers to a presumed lack of understanding by women on how to be successful.
Furthermore, research confronting structural sexism and racism is often marginalized and trivialized. In computational history the importance of gender dynamics are devalued according to historians of technology such as Janet Abbate and Marie Hicks. Similarly, racial inclusion in STEM (science, technology, engineering and math) fields has only recently received attention in both the book and the film on Hidden Figures. The concept of intersectionality introduced by Kimberlé Crenshaw directs attention to the interaction of multiple power structures such as race, sexuality, class and ability. The intersectionality framework provides both a methodological approach and lived experience of academics in the field of digital humanities and computer science.
In the field of Digital Humanities, Nickoal Eichmann-Kalwara, Jeana Jorgensen and Scott B. Weingart studied geographic, disciplinary and demographic diversity between 2000 and 2015 at the Alliance of Digital Humanities Organizations (ADHOs) conference. Their analysis reveals a growing awareness of diversity-related issues, with moderate improvements in regional diversity, but a stagnation in gender diversity. Although women occupy prominent positions in the community’s core, they occupy less space in the much larger periphery of authors. Yet the peer review process shows visible bias against authors with non-English names. Furthermore biases around subject matter reflect gender disparities in specific disciplines, a phenomenon explained by historian Lynn Hunt. The feminization of a field is usually paired with a decline in status and resources.There is a clear correlation between relative pay and the proportion of women in a field: those academic fields that have attracted a relatively high proportion of women pay less on average than those that have not attracted women in the same numbers. So even though women are just as likely to get accepted as men if they submit a presentation on the same topic, topics gendered towards women are less likely to get accepted. Gender studies for instance has an acceptance rate of 60 percent, whereas a male-skewed topic such as text analysis accepts 83 percent of submissions. Barbara Bordalejo’s minority report further demonstrates an Anglophone bias in Digital Humanities, and includes personal attacks openly denigrating her work and feminist research by extension.
In the field of Computer Science, research participation and collaboration of female authors increased by less than 0.1% per year between 2000 and 2015, and male researchers present 79% of actively publishing members in Computer Science conferences. The European report on She Figures mentions that [women] made up 21% of those pursuing PhDs in computing in 2012, therefore remaining underrepresented within the subfield of computing. Furthermore, no progress has been made [between 2010 and 2013] to promote women to grade A positions, (…) women remain relatively more present at lower level of the academic career path.
In order to expand the analysis of gender inequality within the Computer Sciences and compare the results to the geographic, disciplinary and demographic diversity in the Digital Humanities, several data visualizations are included. As the graphic display of abstract information, data visualization serves two purposes, namely sense-making or data analysis and communication. As illustrated in the report of Malu A.C. Gatto on Making Research Useful: Current Challenges and Good Practices in Data Visualisation, academics have often struggled to share their data with other actors and to disseminate their research findings to broader audiences. However, data visualization can truly advance research, not only as a communication tool towards a broader audience, but especially as a tool that allows pre-attentive processing of vast amounts of information. In short, data visualization reduces knowledge gaps. Since conference data sets are often too large to process without the help of visualizations, I would like to introduce several techniques.
Data visualization could provide one possible answer to Michael Jensen questions regarding digital scholarship, asking: “how can we most appropriately support the creation and presentation of intellectually interesting material, maximize its communicative and pedagogical effectiveness, ensure its stability and continual engagement with the growing information universe, and enhance the reputations and careers of its creators and sustainers?” In order to engage with the audience or reader, the design of the project should not be overlooked, even though necessity often dictates that we adopt and adapt tools and technologies that were originally developed for other needs and audiences. I will illustrate the development of and uses for visualizations in Digital Humanities research based on my own visualizations of the gender balance in ten computer science conferences from 2000 until 2015.
Which Data?
DBLP Digital Library
Both datasets used in this article indirectly trace back to the Data Bases and Logic Programming (DBLP) Digital Library created by Michael Ley for his PhD research. The browsable DBLP collection started as formatted HyperText Markup Language (HTML) based on tables of contents, where each authors’ name linked to a list of their publications and to a list of co-authors and their personal pages. In the Evolving Coverage of Computer Science Sub-fields in the DBLP Digital Library Florian Reitz and Oliver Hoffmann discovered thematic biases in the coverage of computer science, with a narrow focus on Databases, Information Retrieval, Programming Languages, and Digital Libraries and Data Mining. By 2005 the DBLP collection covered 65% of computer science conferences mentioned in the list created by Reitz and Hoffmann.
Women in Computer Science research
The dataset used in this research was created by Swati Agarwal et al. in the context of an article on Women in computer science research: what is the bibliography data telling us? and can be accessed online via Mendeley Data. The data was retrieved on September 17, 2015 from the DBLP bibliography database and includes the last 16 years (2000 – 2015) of publication records from 81 Computer Science conferences. For each article the dataset contains the year, conference abbreviation, publisher and unique doi, as well as the domains defined by the authors for each conference. The Author and Editor tables in the dataset provide the position of the author in the paper or the position of the editor in the conference proceedings, a unique name, their gender and the probability of a name being male, female or undetermined. Finally, the dataset includes information about the affiliation of each author and for each paper such as the name, type (Industry or Academic Institution) and country of each affiliation, as well as the latitude and longitude.
Citation Network
For the citation network I needed a second dataset created by Swati Agarwal et Al. with a focus on seven ACM SIGWEB series of conferences which is also available via Mendeley. The data was again derived from the snapshot of the DBLP collection on September 17, 2015 covering 16 years of not seven, but eight SIGWEB conferences. The most important addition to the dataset is the Cited_By table where an identifier for paper A links to the identifier of the article B that cited paper A. Although the data structure was more complicated, the information about the papers, authors and their affiliation was still included. In order to test the citation network visualizations, I only selected the first 1000 papers and their 716 related authors.
Why bibliographic data?
Originally bibliographies improved the process of browsing through collections of books, articles, journals and proceedings either per genre, per country or per language and mostly for academic researchers and librarians. When these collections became accessible online, they provided insights into academia through visualizations. Bibliographic databases store and provide rich information on both co-authorship and the citation networks of academics. Several tools use this data to uncover research area evolutions and communities that show current trends in scientific research, as well as academic social networks.
What’s (not) behind the data?
Human or algorithmic selection
A dataset is inherently curated and therefore leaves out other information. Whether data is selected by a human or an algorithm, the selection or parameters could be biased. For example, as I mentioned earlier, the DBLP Digital Library focusses only on certain areas of Computer Science research. Furthermore, the creators of the first database on Women in Computer Science Research manually assigned each conference to a certain sub-field such as Software Engineering (SE), Data Engineering (DE), and Theory (TH), as well as Computer Science (CS) in general. In Mind the Gap: Gender and Computer Science Conferences Antonio Fiscarelli and I applied topic modelling to prevent such a subjective judgement on research areas, but we still had to decide on a name for each category. For the visualizations my co-supervisor and I have made another subjective selection of ten different conferences ranging from interdisciplinary (i.e. Computer-Human Interaction or CHI) to disciplinary (i.e. User-Interface Software and Technology or UIST). Besides human interference with the data selection, algorithms have enhanced the datasets with geographical information. The first dataset for Women in Computer Science research combined several Application Programming Interfaces (APIs) such as OpenStreetMap, Alchemy Language, Google Geocoding and Bing Geocoding to determine the type of affiliation (Industry or an Academic Institution) and add the coordinates of certain institutions. Furthermore, the Genderize API determined the gender of the authors based on their first name.
Assigning Gender
The Genderize API uses big datasets of information, from user profiles across major social networks to determine the gender of a first name and includes a certainty factor as well. In Women in Computer Science Research the authors decided to include the gender of an author only when their first name was known and the confidence score was over 60%. Overall, 14,2% of authors did not have a gender in the dataset, whereas 69,1% of authors were identified as male and only 16,7% as female. The binary approach of such an algorithm ignores the psychological and sociological use of the term gender, which originated in the United States and signifies the state of being male or female as expressed by social or cultural distinctions and differences, rather than biological ones; the collective attributes of traits associated with a particular sex; or determined as a result of one’s sex. Also: a (male or female) group characterized in this way. Not only does an algorithm assign gender without taking into account an individual’s agency to determine their gender on a spectrum rather than in binary form, it also ignores change over time. Rather than ignoring gender in research altogether, Eichmann-Kalwara et al. believe that showing whether reviewers are less likely to accept papers from authors who appear to be women can reveal entrenched biases, whether or not the author actually identifies as a woman.
What Data Visualization shows
Data Processing
In order to test the data visualizations, several queries limited and structured the data further to create smaller subsets per year and per conference for network visualizations, which were combined to visualize authorship demographics and the evolution of the gender balance across conferences and over the years. The data processing fell into three main steps:
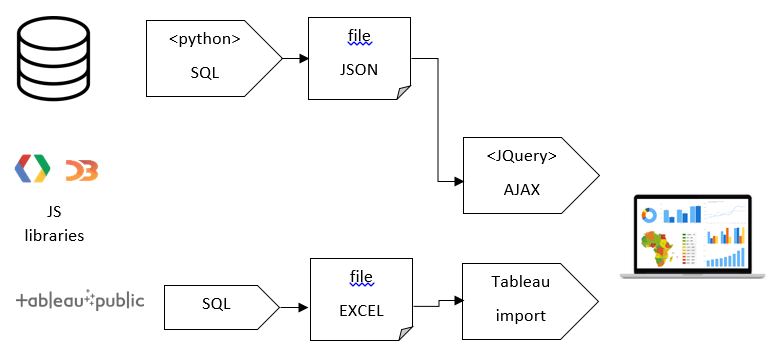
Querying. In order to perform the queries easily, I connected to the databases in Python and stored the results in variables. The queries differed for each single visualization, since they all required different information.
Formatting. The visualizations created based on JavaScript libraries such as Google Charts, Google Maps API, Protovis, or D3.js only accepted data in the JavaScript Object Notation or JSON. Tableau on the other hand accepted Excel-files.
Importing. The JSON-files for the first visualizations were imported using the jQuery asynchronous JavaScript and XML or AJAX method. Tableau used a drag and drop interface.
The data processing process. Arrows represent scripts, while post-its represent files
Co-authorship network visualization
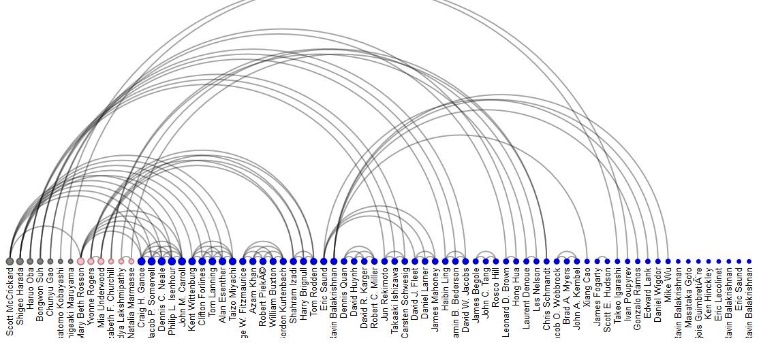
The first network visualization was based on an arc visualization in Protovis and showed every single author represented as a dot on a horizontal line. The size of the dot or node represented the number of co-authors. The color represented their gender and the lines connected authors working on the same paper. Grey represents an unknown gender, pink represents female and blue stands for male authors.
Because the dataset contains 48 877 authors in total for the selection of ten conferences, the co-authorship network focuses on a specific year for a single conference. shows the situation at the relatively small ACM User Interface Software and Technology (UIST) conference in 2003 with a particularly low representation of female authors. Furthermore, the single-authored papers were all written by men, whereas both unknown and female authors all co-authored with male authors.
Protovis visualisation of the 2003 UIST conference
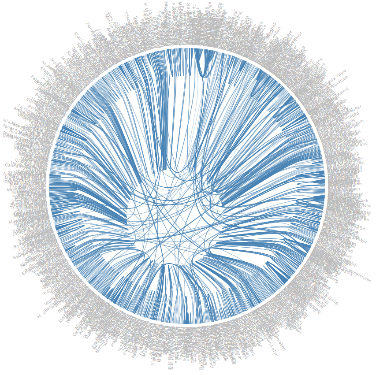
Chord Diagram of the 2005 CHI conference co-authorship network
In the second network visualization authors were again represented individually as a dot, but this time arranged in the form of a circle and grouped by affiliation according to a hierarchical edge-bundling example from D3.js. The lines show the relation between co-authors and when hovering over an author, the incoming and outgoing links to co-authors are highlighted. In the gender of authors is not included in the visualization of collaboration at the Computer-Human Interaction (CHI) conference of 2005. The chord diagram does illustrate that authors in this interdisciplinary research area will mostly collaborate within the same institution, or one or more authors from a single external organization. Despite the limited selection of 1000 papers from the dataset, the chord diagram is very difficult to interpret due to the sheer number of authors.
Unfortunately, network visualizations always run into the risk of cluttered screens, which is especially true for larger networks. However, added interactivity and filtering the data allows users to explore the results in a structured way. Another solution would be to cluster authors either based on their institution or by research area to reduce the number of nodes. Co-authorship networks are less clear in displaying the gender balance, but color-coding nodes according to gender does draw attention to the role of gender in collaboration. Furthermore, the choice of colors is heavily based on culture in with pink for women and blue for men. In modern Western culture the color choice immediately conveys gender information, but it does adhere to existing stereotypes and fails to take into account other cultural color conventions.
Conference Demographics
First I experimented with simple bar and line charts provided by Google Charts API to demonstrate the evolution of gender balance in computer science conferences over time and a map visualization of all the affiliations included in the dataset using the Google Maps API. These visualizations did not, however, allow for interactive exploration, so eventually authorship demographics were visualized using the software platform of Tableau. Besides studying the evolution of the gender balance per conference, other demographics include the geographical location of authors based on their affiliation, as well as gender in relation to co-authorship grouped by conference.
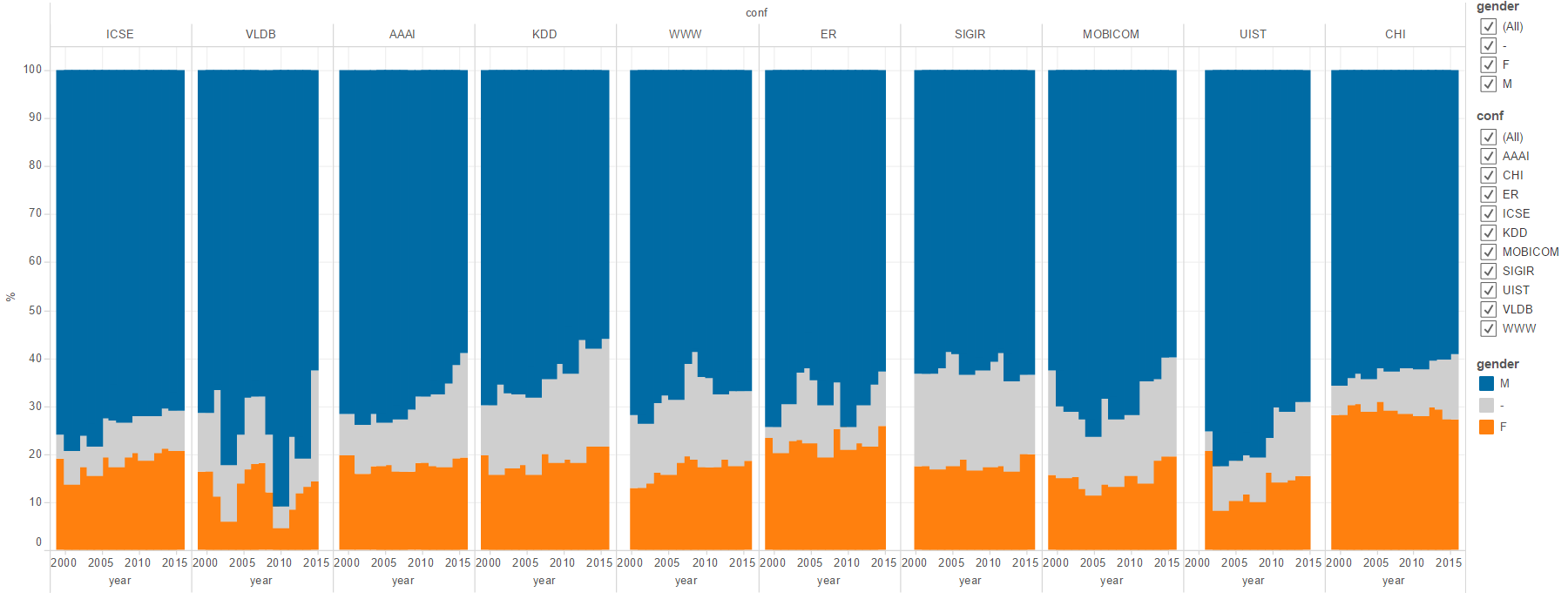
The first stacked bar chart shows the evolution of gender balance in ten computer science conferences over a period of sixteen years. The horizontal axis was grouped per conference and the stacked bars were color-coded according to gender, with blue representing male, orange representing female and grey representing unknown. The interactive Tableau software provides details-on-demand while hovering over the visualization and filtering per conference, year and gender. Overall, research participation and collaboration of female authors increased by less than 0.1% per year between 2000 and 2015 as previously mentioned.
100% stacked bar chart of the gender balance in ten CS conferences from 2000 to 2016
The percentage of male authors decreased in several interdisciplinary conferences such as CHI, and in the field of knowledge engineering including UIST and Knowledge Discovery and Data mining (KDD) as well as software engineering with the International Conference on Software Engineering (ICSE). Because of the relatively large proportion of authors where the gender is unknown, the decrease in male authors does not necessarily indicate an increase in female authors. Overall only the CHI conference has a relatively large percentage of female authors representing between 25% and 30% of all authors. The lowest percentages of female authors can be found at the Very Large DataBases (VLDB) and UIST conference.
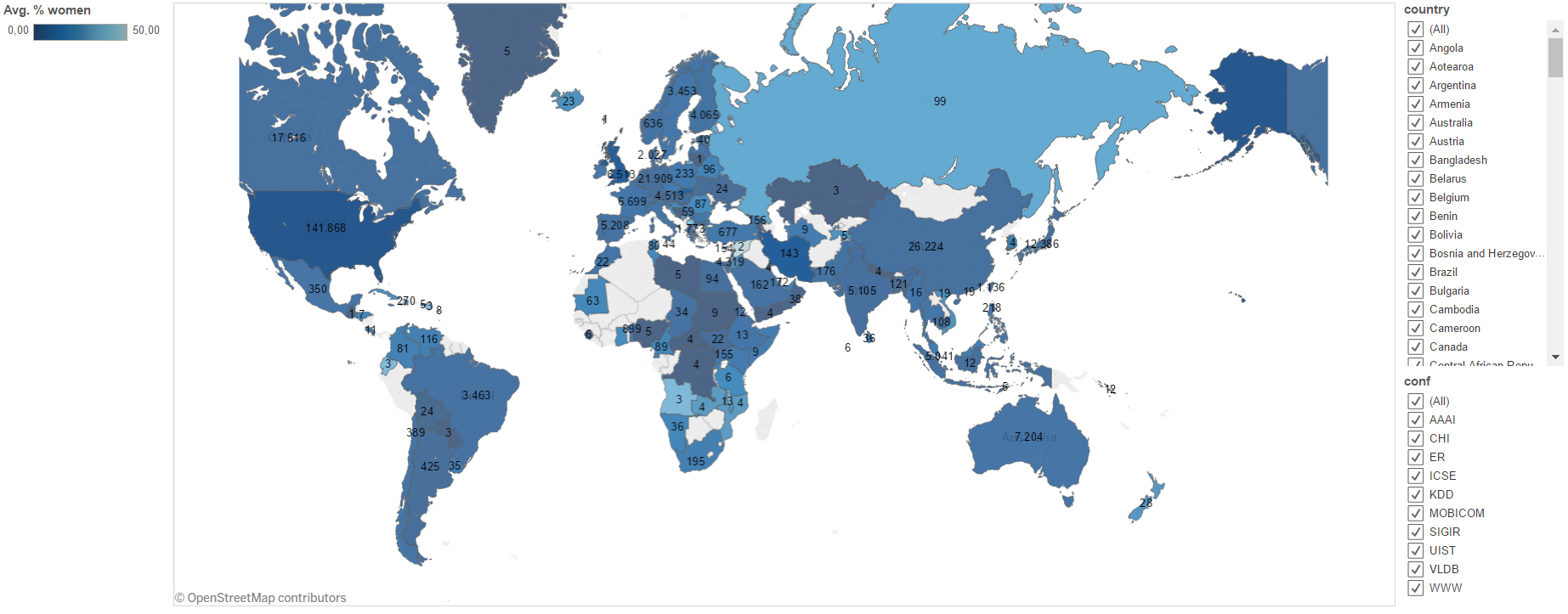
The map visualization uses the same color scheme as the stacked bar chart, but gradually changes from dark blue indicating a lack of female authors to bright orange representing 100% female authorship on average. Each country also contains the exact number of authors affiliated to institutions located in that country. Tableau uses the Mercator map projection, which means that although the shape of countries is respected, area is not well represented. A common critique of the Mercator projection is that Greenland is roughly the same size as the entire continent of Africa. Furthermore, the map is Europe-centered and thus presents a eurocentric view of the world. For example, the size of Russia immediately draws attention, but only 99 authors are affiliated with Russian institutions compared to 141 868 authors from the United States.
Map of average percentage of female authors at ten CS conferences between 2000 and 2015.
Despite the relatively low number of authors, 33.3% of Russian-based researchers submitting papers to CS conferences are identified as female, compared to only 4,94% of U.S.-based researchers. The United States (38,2%) and China (7%) account for 45,2% of all authors of which on average only 5% are female. Besides disciplinary differences in the gender balance, the disparities are far bigger in the author affiliations from the United States and China than in Russia. The different course in the history of computing of the former Soviet Union had the opposite effect on gender balance in CS creating a previously female-dominated field.
Treemap of the gender balance for each paper in ten CS conferences from 2000 to 2016
In a tree map visualization showing the percentage of women per paper and grouped by conference, the same color-coding and filters were again adopted to allow additional data exploration. The ten larger blocks each represent a single conference, with size referencing the number of authors. Within each conference block, a single block represents a paper and a small block refers to a single-authored paper whereas larger rectangles reference co-authored papers. The filters can limit the results to a smaller range of years or exclude some of the conferences to get a clearer view of the data. Furthermore, hovering over a block provides the exact number of authors for a single paper, as well as the percentage of female authors for that paper.
Although the first network visualization showed that women at the UIST conference of 2003 generally co-authored papers, the same does not apply to other conferences, given the high concentration of female authors in the bottom-right corner of single-authored papers. Overall, the multi-authored papers on the left and top of each conference rectangle have few if any female authors. Collaboration thus occurs mostly between men, except at the CHI conference (top right).
What Data Visualization doesn’t show
Accessibility and Compatibility
In order to visualize the data, free access to software or existing code is rarely guaranteed since this software is often commercial. Furthermore, if support for software or existing code ends, the visualization will likely disappear entirely. Even at the time of the creation some of the online visualizations are not supported by the browser or could appear different and even distorted depending on the screen size and browser. Regardless of challenges related to the visualization software, the main value of data visualization lies in both facilitating pre-attentive processing, as well as communicating results.
User Analysis
While the expert might find certain types of visualizations very useful, some graphical representations such as the tree map in do not communicate anything to a larger audience because it requires previous knowledge of the structure and parameters included in tree maps. Therefore, I evaluated the communicative value of visualizations with twelve Digital Humanities students at KU Leuven. The test users performed nine tasks based on the visualizations in a think aloud study and afterwards rated the visualizations on a System Usability Scale. Furthermore, an open-ended questionnaire allowed participants to express their opinion concluding the evaluation.
Based on the user test I found that required explanation, but most participants correctly identified the number of co-authors and especially the topic of the conference as an influence on the percentage of female authors in conference papers. The co-authorship network visualization displayed in and frustrated the users, although nearly all of them recognized more collaboration between authors from different affiliations in the CHI conferences of 2005 compared to the UIST conference in 2003. Overall, the interactive components and filters greatly improved how comprehensive a visualization was.
Conclusion
Rather than merely analyzing issues regarding the gender imbalance in computer science, this paper studies how to identify and visualize such issues through co-authorship networks and conference demographics. However, a researcher first needs to critically examine and understand the data at the base of the study. Without understanding the data, understanding the visualization becomes difficult if not impossible. In the particular case of the DBLP bibliographic database, topics are biased towards Databases, Information Retrieval, etc. Furthermore, algorithmic bias creeps in through automatically assigning gender to authors based on their first name. Finally, human selection of ten specific conferences further narrows down the dataset.
Based on two co-authorship networks and three conference demographic visualizations, we can better understand the pitfalls of data visualization and at the same time study intersectionality in computer science conferences. For instance, due to the unknown gender of some researchers, a decrease in male authors does not necessarily indicate an increase in female authors in the 100% stacked bar chart. However, taking a closer look at collaboration through co-authorship networks can only be done for a single conference and specific year since both the arc- and hierarchical edge-bundling visualizations otherwise become too cluttered to read. The map visualization then illustrates the difference in gender balance between Russian and American institutions yet distorts the size of countries in favor of a Western-centric vision of the world. Furthermore, the tree map visualization might combine a lot of information such as the number of authors for each paper, the number of papers at each conference and the gender balance in co-authored papers. However, a tree map visualization is not intuitive or easy to interpret for anyone unfamiliar with both the data and the visualization method.
The iterative process of creating and evaluating visualizations is best explained through Norman’s Action Cycle. In order to form questions and find answers, the action cycle falls into two gulfs. First a user or researcher needs to set an intention and create an action plan during the gulf of execution. If the action or in this case the visualization shows an interesting pattern, then a gulf of evaluation follows. The perception of the visualization might lead to an interpretation which then needs to be evaluated again. Interactivity thus allows further exploration of the data by other researchers or the audience, while storytelling structures the relations between different visualizations and guides the audience through the research in a few clicks. The core value of visualizations for the Digital Humanities therefore lies in accelerating data processing and raising possibilities for further research.
References
Abbate, Janet. 2012. Recoding Gender. Cambridge: The MIT Press.
Agarwal, Swati, Nitish Mittal, Rohan Katyal, Ashish Sureka, and Denzil Correa. 2016. Women in Computer Science Research: What Is the Bibliography Data Telling Us?SIGCAS Computers and Society 46 (1):7–19. https://doi.org/10.1145/2908216.2908218.
Agarwal, Swati, Nitish Mittal, and Ashish Sureka. 2016. A Glance at Seven ACM SIGWEB Series of Conferences.SIGWEB Newsletter, no. Summer:1-10. https://doi.org/10.1145/2956573.2956578.
Agarwal, Swati, Ashish Sureka, and Nitish Mittal. 2016. DBLP Publications Records and ACM Metadata for SIGWEB ConferencesMendeley Data 1. https://doi.org/10.17632/dn5d8fbkb9.1.
Agarwal, Swati, Ashish Sureka, Nitish Mittal, Rohan Katyal, and Denzil Correa. 2016. DBLP Records and Entries for Key Computer Science ConferencesMendeley Data 1. https://doi.org/10.17632/3p9w84t5mr.1.
Bordalejo, Barbara. 2018. Minority Report. The Myth of Equality in Digital Humanities. In Bodies of Information: Intersectional Feminism and the Digital Humanities, edited by E. Losh and J. Wernimont. Minneapolis: University of Minnesota Press. https://muse.jhu.edu/book/63071.
Crenshaw, Kimberle. 1991. Mapping the Margins: Intersectionality, Identity Politics, and Violence against Women of Color.Stanford Law Review 43 (6):1241–99. https://doi.org/10.2307/1229039.
Eichmann-Kalwara, Nickoal, Jeana Jorgensen, and Scott B. Weingart. 2016. Representation at Digital Humanities Conferences (2000-2015). Preprint, submitted 21/03/2016. https://doi.org/10.6084/m9.figshare.3120610.v1.
Eichmann-Kalwara, Jorgensen, Weingart. 2018. Representation at Digital Humanities Conferences (2000-2015). In Bodies of Information: Intersectional Feminism and the Digital Humanities, edited by E. Losh and J. Wernimont. Minneapolis: University of Minnesota Press. https://muse.jhu.edu/book/63071.
Gatto, Malu. 2015. Making Research Useful: Current Challenges and Good Practices in Data Visualisation. Oxford: Reuters Institute for the Study of Journalism.
‘Genderize.Io | Determine the Gender of a First Name’. Website. https://genderize.io/.
Hicks, Marie. 2017. Programmed Inequality: How Britain Discarded Women Technologists and Lost Its Edge in Computing. Cambridge: MIT Press.
Jensen, Michael. 2004. Intermediation and Its Malcontents: Validating Professionalism in the Age of Raw Dissemination. In Companion to Digital Humanities, edited by S. Schreibman, R. Siemens, and J.Unsworth. Oxford: Blackwell Publishing Professional. http://www.digitalhumanities.org/companion/.
Kirschenbaum, Matthew G. 2004. “So the Colors Cover the Wires: Interface, Aesthetics, and Usability.” In Companion to Digital Humanities, edited by S. Schreibman, R. Siemens, and J. Unsworth. Oxford: Blackwell Publishing Professional. http://www.digitalhumanities.org/companion/.
Lee Shetterly, Margot. 2016. Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space Race. New York: William Morrow.
Ley, Michael. 2002. The DBLP Computer Science Bibliography: Evolution, Research Issues, Perspectives. In Proceedings of the 9th International Symposium on String Processing and Information Retrieval, 1–10. Berlin: Springer-Verlag. http://dl.acm.org/citation.cfm?id=646491.694954.
Losh, Elizabeth, and Jacqueline Wernimont. 2018. Bodies of Information: Intersectional Feminism and the Digital Humanities. Minneapolis: University of Minnesota Press. https://muse.jhu.edu/book/63071.
Reitz, Florian, and Oliver Hoffmann. 2010. An Analysis of the Evolving Coverage of Computer Science Sub-Fields in the DBLP Digital Library. In Research and Advanced Technology for Digital Libraries, edited by M. Lalmas, J. Jose, A. Rauber, F. Sebastiani, and I. Frommholz, 216–27. Berlin: Springer.
Valian, Virginia. 2005. ‘Beyond Gender Schemas: Improving the Advancement of Women in Academia’, Hypatia 20 (3): 198-215.
Van Herck, Sytze. 2017. Visualising Gender Balance. Ten Computer Science Conferences and the Digital Humanities Conference Compared. KU Leuven, Faculteit Wetenschappen, Master of Digital Humanities.
Van Herck, Sytze, and Antonio Maria Fiscarelli. 2018. Mind the Gap Gender and Computer Science Conferences. In This Changes Everything – ICT and Climate Change: What Can We Do?, edited by D. Kreps, C. Ess, L. Leenen, and K. Kimppa, 232–49. Berlin: Springer International Publishing.
Wu, Meng Qi Yelena, Robert Faris, and Kwan-Liu Ma. 2013. Visual Exploration of Academic Career Paths. In 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2013), 779–86. https://doi.org/10.1145/2492517.2492638.
Last URLs access: 30 September 2018
.
.
, ix.
, ix; .
, xi; .
, xi; .
.
, 86.
, 86.
, 73.
, 84.
, 75; .
.
, 85.
, 85.
.
.
, 20.
, 130.
, 2229.
, 4.
, 5.
, 551.
, 539.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
‘Genderize.Io | Determine the Gender of a First Name’.