Use Case: Project Latvia
The four stage workflow will be demonstrated by showcasing a project that the Data Integration Section carried out.
In 2015 the team took on a project to integrate archival materials and name lists received from Latvian collection holders.
Introduction
Yad Vashem acquired archival materials from Latvian State Historical Archives (Latvijas Valsts vēstures arhīvs, LVVA) and from the Latvian State Archives (Latvijas Valsts arhīvs, LVA). The materials included thirty-three microfilmed collections, among them collections from pre-war Jewish organizations, population censuses conducted in 1935 and 1941, Riga House Committee books, documentation regarding Jewish education originating from governmental and communal authorities and a collection of personal files of Jewish residents deported from Latvia by the Soviet authorities in June 1941.
Yad Vashem also acquired a collection of domestic and foreign passports that was delivered in the form of digitized document images,
In addition, Yad Vashem received a set of lists of names of Jewish residents from Latvia made by the Center for Judaic Studies at the University of Latvia. The lists are the result of a research project that aimed to determine the fates of Latvian Jewry in the Holocaust. Some of the archival sources that were used to compile these lists were later acquired by Yad Vashem and are mentioned above.
Extent
The microfilmed collections were delivered to Yad Vashem on 900 reels.
The digitized passport collection amounted to 187,000 image files.
Descriptive metadata were obtained with the copied materials. The collections were accompanied by file level descriptions. Descriptions for both the microfilmed and the digitized collections were produced in 50 Excel files and 2 Word documents. In addition, there were three Excel files with lists of 90 thousand names of the Jewish residents of Latvia.
Each of these datasets is discussed separately below.
Objective
The thought behind the Latvian project was to produce as full a picture as possible of Latvian Jewish community before the war and its fate after the Holocaust. In order to achieve this, the project was split into four assignments:
-
To integrate the list of names of Jewish residents of Latvia into the Yad Vashem names database.
-
To integrate the archival descriptions of the copy collections into the Archive catalogue.
-
To extract names data from the metadata in archival descriptions and produce name records in the Yad Vashem names database.
-
To link between name occurrences within the scope of the project in order to be able to present a personal history of sorts based on archival sources as well as on the external research project (‘List of Jewish residents’).
Process
Preliminary analysis
Historical and archival context of the acquired collections
Looking into the historical and archival context of the collections in question allowed us to learn their essence, to understand who were their creators, what types of materials they contained, and whether they were homogenous or diverse in nature. This sort of information was vital later in determining the appropriate schema and templates for integration.
Microfilmed collections
Several collections were identified as being homogenous. For example, there was a set of personal files of Jewish teachers that was created by a special department at the Latvian Ministry of education that was solely dedicated to the subject of Jewish education. The files, for the most part, consisted of similar document types. Another example of a uniform collection was the collection of 1935 Latvian population census. The entire collection consisted of personal questionnaires filled out by census enumerators in a given locality. In contrast, most of the collections created by Jewish organizations were very diverse. They contained financial documents, lists of members, and correspondence with other branches and organizations around the globe, from Mandatory Palestine to Shanghai.
Collection of domestic and foreign passports
The original collection in the Latvian Historical Archives contains about 500 thousand archival files, each in a separate envelope corresponding to a single person. The collection consists of applications to the Riga authorities to issue a new passport, usually to replace an expired one. In addition to a passport, an envelope may contain other personal documents (birth and marriage records etc.). Yad Vashem acquired digital copies of 43 thousand files from this collection. However, during the digitization only the passports were copied, without the accompanying documents. On top of that, when an envelope contained several passports, only one of them was digitized.
The information about the arrangement of the materials and the way they were selected for digitization proved to be very important in sorting and then linking the images to the descriptions. Since we knew that each envelope (file) could contain images pertaining only to one person, it helped validating results during special case checks – checks we perform before authorizing linking of image files to the descriptions.
Research the methodological framework used to produce data sets
The goal of this task was to gather as much information as possible on the standards adopted by the creators of the data sets, the policies and procedures implemented by them, and the assumptions and allowances that were made during the production and cataloguing of the data. This essential step allowed for more precise and accurate interpretation of the data for subsequent steps.
For example, while exploring the ways and the means used to produce the ‘List of Jewish residents’ we learned that the team working on the project made a decision to ignore the original Latvian spellings of names and to transcribe all names to conform to a German spelling system. For example, the Latvian surname variant ‘Broščermanis’ was transformed into ‘Broschtschermann’. This information proved to be useful first when we looked up matches for those surnames in Yad Vashem’s ontology. It was especially important in cases when a proper match wasn’t found and we needed to send those values for evaluation by an onomastics expert before adding them to the vocabulary. Second, being aware of this modification assisted us in plotting a strategy to link between different mentions about the same person within the project. So, when the same person was mentioned both in the ‘List of Jewish residents’ in a Germanized fashion and in the passports collection in proper Latvian form we could adjust for that and recognize the similarity.
Another example of a policy implemented by the authors of the List is a decision to spell place names according to the historical period of the event denoted. For all the events that occurred before 1919, a non-Latvian variant was used, if existed (ex. Dünaburg or Dvinsk and not Daugavpils). Here again, this knowledge helped us to validate the results after we matched all the place names to our vocabulary.
Understanding the terminology used to describe the fates of Jews was vital and enabled a proper interpretation of these keywords. For example, when a fate of a person was denoted as ‘deported’ it meant deportation to Siberia by the Soviet authorities in June 1941 and not deportation by the Nazis, which might have been the default thinking in the context of Yad Vashem.
Structural analysis of the data sets
At this step, the main emphasis was on metadata assessment. In order to proceed to the next stages of the project it was essential to identify the different templates of metadata.
Thus, by examining file formats, counting fields and comparing field names we were able to determine how many templates were used.
List of Jewish residents
The list was arranged in three excel files – two for residents of Riga and one for the residents of all other localities. Although there were apparent similarities, each of these lists used a separate template. The number of fields was different and the names of the fields varied. For example, fields named [Prewar Residence] and [Prewar Address] in one table were named [Res. Pre-WWII] and [Address Pre-WWII] in another. After additional analysis it became apparent that those three templates could be reduced to a single one.
Microfilmed collections
Within this data set of 50 files describing thirty-three archival collections, only one template was found. The only inconsistency that was apparent was due to different file formats of two collection descriptions, which were produced as formatted tables in Word documents.
Collection of domestic and foreign passports
This collection was delivered to Yad Vashem in two installments. Each installment was accompanied by an archival inventory list that constituted yet another template.
To sum up, by the end of this step it was revealed that all 55 different metadata files could be reduced to three templates.
Once these templates were recognized, three structurally cohesive data sets were prepared, one for thirty-three microfilmed collections, another for the passport collection and one more for the ‘List of Jewish residents’.
Output Data Model and Project Guidelines
After the first three preliminary steps were completed, the path was clear to select and fit existing Yad Vashem compatible schemas for the data sets. Two separate schemas were chosen for name indexing and three for cataloguing archival descriptions. Name records that emanated from archival descriptions were indexed in a different schema from the ‘List of Jewish residents’ because in addition to the biographical data, pointers to digital images could also be provided in the first case and not in the second. The archival collections were classified into three groups: personal files, official documentation (created by governmental entities) and nonspecific documentation (mostly created by Jewish organization). According to this classification three different schemas deemed appropriate.
The knowledge of historical and archival context (see above, ) aided us in determining the proper schemas, especially for archival descriptions.
Following, final guidelines for the completion of the project were formulated.
Data Normalization
Mapping
This step was the first in a series of steps we took to normalize, clean and validate the data sets.
The fields were mapped to the selected schemas. These mappings determined which processes and steps needed to be taken next for each of the fields. Naturally, fields that were mapped to Yad Vashem controlled vocabularies were to be processed differently from date and text fields, for example.
During this step, we heavily relied on the information that was gathered in the beginning of the project (see, ).
Data cleaning
In order for the data to conform to Yad Vashem standards, in most cases, a process of cleaning is needed. Most of these processes were written into automated routines and procedures.
In order to apply those procedures effectively, similar fields were grouped together. This enabled us to work with similar types of data simultaneously in order to standardize them.
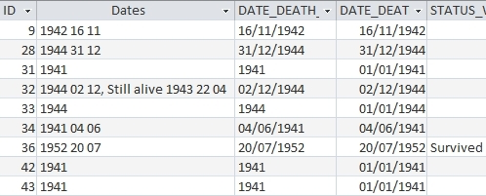
For example, all the data mapped as date fields were grouped into a single list. Following that, a procedure was run to transform all the dates into patterns. The patterns were then analyzed using a preexisting list of interpreted patterns. Each new pattern was deciphered and added to the list for future reference. As a result, all the dates were formatted and propagated. (See : the column [Dates] contains original data while the other columns are cleaned, formatted and interpreted).
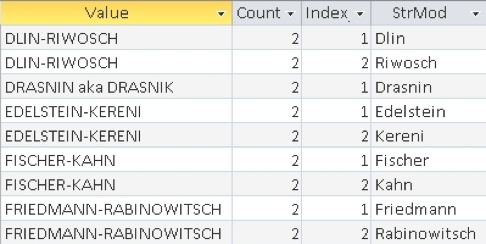
In the case of fields mapped with table values, such as names, surnames or places, after grouping them together the data was normalized, split into separate fields if needed and adjusted to enable successful matching to the vocabularies. In many cases, data fields in the source material contained several values which needed to be separated in order to be matched to vocabularies. This was the case especially in the ‘List of Jewish residents’. The field for surnames could contain a compound name. The field for place of residence could hold several names of localities (in cases when the researcher encountered several sources with different addresses). All those cases had to be recognized and evaluated. (See : the column [Value] contains the input data, the column [StrMod] contains the separated substrings while the columns [Count] and [Index] denote their amount and order in the original).
Compilation
Finally, after all the cleaning and normalization was completed, all the appropriate matches were looked up and validated in the system’s many controlled vocabularies, a new table, according to the selected schema, was compiled in order to integrate the data into the Yad Vashem catalogue.
As a part of this compilation step, some metadata enhancements were incorporated.
One of these enhancements was formulating descriptive titles at the archival file level. This was made possible by analyzing the original file titles and texts (mostly in Russian) in order to define patterns. As a result of this analysis about 150 different textual patterns were recognized. The patterns then were translated into English and Hebrew. Based on the translated patterns proper titles were calculated for each file. (See Figure 3: the first row represents an original Russian title, the second – a pattern, the last two rows demonstrate calculated titles in English).
Finally, all the restructured data (except ‘List of Jewish residents’)

were linked to matching digital objects, i.e. digitized microfilm reels and scans.
All 900 microfilm reels underwent digitization after delivery to Yad Vashem. After this was completed it was possible to establish a relationship between ranges of image files in each reel and the appropriate descriptions. That allowed us to create pointers to pages in a microfilm reel.
As to the collection of passports, which was received as a digital copy, after evaluating the directory structure and file naming patterns, and eliminating duplicate images, an alternative file structure was proposed. The source files were copied and converted to conform to Yad Vashem’s standards. Those derivative files were renamed and reorganized in a different file directory system. This reordering enabled proper linking between the two components of the archival file: the descriptions and the images.
Results
At the completion of the project, the following records were integrated into the Yad Vashem database:
-
90,000 name records from List of Jewish residents in Latvia
-
10,291 files of microfilmed copy collections
-
43,000 files of passports collection
-
332,000 name records extracted from metadata in archival descriptions
-
86,400 groups of name occurrences were clustered together.
Blanket approach?
Adhering to this four stage process enabled proper integration into the main catalogue of new, retrievable records, which were consistent with the rest of Yad Vashem’s collections. This also provided a variety of entry points to the catalogue that made the records in question even more accessible for the end-users in-house as well as worldwide.
Since it is applicable to any data integration project the Data Integration Section takes on, the epithet blanket approach
deemed appropriate.
Applying the four stage workflow has proven itself efficient in other projects so far as well.
The utility of this approach may, at least in part, be due to the conservatism of the domain. After all, we have been consistently dealing with materials that lack uniformity, as the aspect of potential data sharing doesn’t seem to be taken into account when various organizations take on cataloguing and indexing projects.