In this paper we build upon and contribute to the discussion between the adjacent fields of (digital) genetic criticism and (digital) scholarly editing. In particular, we focus on the modelling process in a real-life project, "Gustave Roud, Œuvres complètes", presented in section 1. The project aims to create an edition of the complete works of the Swiss author Gustave Roud (1897-1976), including the publication of his drafts and manuscripts. This large corpus sheds light on Roud's writing practices: on the one hand he created afresh, mainly in his diary, and on the other hand he selected and reused materials from the diary and from already published texts. The goal of this paper is to propose a data model for representing the genetic processes in question. This model should necessarily go beyond the notion of avant-texte of a single work and explore the connections between the texts, in order to create a network of genetic materials. The model and its formalization in an OWL ontology are presented in section 2. In the following section the model is applied to two case studies from Roud's corpus. We conclude by presenting some possibilities for improving and enlarging the focus of this study.
In quest'articolo viene presentato un modello di dati per le relazioni genetiche tra i manoscritti e le pubblicazioni di un autore. La proposta prende le mosse dallo studio di un corpus specifico, presentato nella prima sezione dell'articolo, quello dello scrittore svizzero Gustave Roud (1897-1976). La scrittura di Roud nasce raramente dal foglio bianco: più spesso egli riutilizza, riscrivendo o assemblando, passaggi provenienti dal suo diario o da testi già pubblicati. La modellizzazione del progesso genetico nel caso di un tale corpus richiede necessariamente di andare oltre l'avantesto della singola opera e di creare una rete di connessioni tra i testi. Il modello, e la sua formalizzazione in un'ontologia OWL, sono presentati nella seconda sezione. Di seguito, il modello viene applicato a dei casi concreti tratti dall'opera di Roud. In conclusione, sono discusse alcune possibilità per proseguire lo studio intrapreso e applicare il modello a genesi diverse.
Genetic criticism and digital scholarly editing
The field of genetic criticism is vast and constantly evolving, broadening its boundaries in order to welcome new research questions. The central notion of avant-texte, along with its counterparts, exogenesis and endogenesis, originally developed by Raymonde Debray-Genette (), has recently been questioned: different levels of genetic approaches, such as micro- and macro-genesis, have been adopted (); and the study of post-editorial genesis or epigenesis, dealing with textual variants emerging after the first publication of a work, has been flourishing (; ).
In the Digital Humanities realm today, scholarly editing is prompted to consider issues fundamental to genetic criticism, such as the organisation of materials and thorough analysis of each document. Dirk Van Hulle, active in promoting a combination of scholarly editing and genetic criticism, suggests that combining these perspectives would be to the advantage of both: "The digital genetic edition does not have to be either an archive edition or a text edition; it can be a continuum between the two" (: 49).
In this paper we build upon and contribute to the discussion between the adjacent fields of (digital) genetic criticism and (digital) scholarly editing. In particular, we focus on the modelling process in a real-life project, "Gustave Roud, Œuvres complètes", presented in section 1. The project aims to create an edition of the complete works of the Swiss author Gustave Roud (1897-1976), including the publication of his drafts and manuscripts, which are archived mostly at the Centre des littératures en Suisse romande of the University of Lausanne.
This large corpus sheds light on Roud's writing practices: on the one hand he created afresh, mainly in his diary, and on the other hand he selected and reused materials from the diary and from already published texts. The goal of this paper is to propose a data model for representing the genetic processes in question. We will use the term avant-texte to refer to all materials preparing a work. This model should necessarily go beyond the notion of avant-texte and should explore the connections between the texts around it, in order to create a network of genetic materials. Hence the focus of our model is on the relationships between the witnesses (documents and publications), not only on the witness itself as a genetic entity. The model and its formalization in an OWL ontology are presented in section 2. In the following sections the model is applied to two case studies from Roud's corpus. We conclude by presenting some possibilities for improving and continuing this study.
1. Few avant-textes, but a diary: Gustave Roud's writing practices and the edition of his Complete Works
The digital edition of Gustave Roud's work and archives seeks to explore the continuum between the "archive edition" and the "text edition". All the archival materials will be digitised and published, together with detailed metadata and descriptions, on a dedicated online platform that will also host the critical texts and a number of guided itineraries into Roud's world and atelier. A paper edition will complement the online platform, providing clean and readable texts, introductory notes, and commentaries. The complete works will be divided into four sections: diary, poetry, art and literary criticism, and translation. Roud also has a strong activity as a photographer and he sometimes included photos in his articles. This heterogenous corpus, interdisciplinary by nature, raises questions from different research fields including landscape history, art history, literary geography, ethnography, sociology, gender studies, literary criticism, and media theory. Exposing these diverse materials will incite a renewal in the way the author and his works are read and studied.
A genetic approach to the organisation of the documents in the digital platform not only complements and expands the possibilities of the print edition, but also provides a better understanding of how Roud developed his texts and poetry collections (recueils). This enlarged perspective allows us to move from a "print" view, which implies independent textual entities, to a network of texts accompanied by genetic witnesses. In order to construct such a network, we need to identify and analyse the nature of the links connecting these entities. Indeed, most of the poetry collections published by Roud between 1927 and 1972 have a long and slow gestation: the first elements of a text are formulated in diary notes, which might be copied onto several supports; notes are used in drafts for articles in periodicals, which, after being amended and corrected, might be repurposed in a poetry collection.
This process of elaboration explains why Gustave Roud's archives preserve several versions of the same texts, or parts of texts, in different forms (different kinds of diary notes, articles, parts of poetry collections), instead of a large number of plans and drafts corresponding to the usual stages of the writing process comprising the avant-texte.
Roud’s diary plays a central role in his writing practices. The poet's journal is well preserved, despite some gaps, on various supports: notebooks and pocket notebooks, notepads, agendas, individual sheets and paper bundles. By studying the diary it is possible to illustrate some of Roud's creative processes and to question his writing practices.
1.1. The diary as genetic witness
It is rare for a writer's diary to have no direct or indirect link with his works. A space for recording moments of inspiration, a reservoir of ideas or motifs, a test bench for the first sketches, the writer's diary serves as a "writing workshop", in a broad sense, for many writers (;;). However, it is important to situate such an object of study, since its content and form might vary greatly. A diary can be considered as genetic material only in relation with and functional to a particular work, according to Philippe Lejeune:
Un journal peut être l’un des lieux où s’effectue la genèse d’une œuvre […]. Un journal peut être le témoin intentionnel d’une genèse qui s’effectue en d’autres lieux, carnet de régie, ou de suivi, du processus d’élaboration d’une œuvre […].
Dans les deux cas, le journal va être, selon le vocabulaire qu’il plaira d’employer, un avant-texte, un élément de dossier génétique d’une œuvre autre que lui. Il participe, comme acteur et/ou témoin, à un travail de création dont il n’est pas le but. Il ne sera donc pas l’objet de l’étude génétique, même si la question de sa propre production peut, dans le cadre de telles études, se poser. Il n’en sera que le moyen. [51: p. 29]
Having the advantage of being dated, this genetic account offers a rare testimony for studying a work’s gestation phases. Though it often begins irregularly, a diary generally develops a consistency over time, which makes it a stable object of study, pursuing certain aesthetic and formal principles, despite its possible variations. Generally not intended for publication, it essentially aims to accumulate traces of life for personal and literary purposes. Finally, a writer's diary is the result of a writing practice that derives from and refers to the author's life.
In Roud's case, the diaristic practice must be considered broadly, beyond its relation to a single published text: the diary must be regarded as a text in its own right () while, at the same time, its different types of relationship with other texts must also be investigated.
A first type of relationship consists in the use of one or more diary entries, in whole or in part, to constitute a new text or collection. Entries may be minimally or extensively rewritten. In most cases, such (re)use essentially involves selection and (re)organisation; textual changes are limited, but not insignificant. When passages from the diary are selected and grouped together, they are published almost as they emerged. For Roud, the act of writing, rewriting and reuse all tend to recreate in the poem an intense moment:
Le point de départ est une sorte d’illumination, de vision qui vous saisit au cours par exemple d’une longue marche à travers un paysage. Tout à coup tout change, vous avez l’impression que les choses qui sont devant vous sont toujours les mêmes mais qu’elles sont devenues autres, et la vue que vous en avez se change petit à petit en vision. Au lieu d’entrer en cœur dans le temporel, il y a une sorte d’éternité qui se découvre, à laquelle vous participez peut-être un très bref instant.
[…] Tout le désir est justement de prolonger, par la parole, par le poème, le souvenir de cet instant que l’on vient de vivre.
The result is a very free mode of composition, described as "rhapsodic" (; : 16-18), based on the juxtaposition of these notes-moments. The collection Feuillets (1929) (), as well as several articles published in the periodical Aujourd'hui (1929-1931) and later in other reviews, result from this particular relationship with the notes collected in the diary.
Another type of use, in addition to textual reuse, is the thematic reuse of a strong idea, a "sème" or "motif" according to Bellemin-Noël (: 34-40). This semantic reworking is more common in dense and elaborate texts that combine various elements.
The nature of a thematic reuse makes its path from diary to text more difficult to trace; accordingly, we decided not to include it in the formal model presented below.
A tight connection between diary and works, which does not comprise reuse, occurs when the diary plays the role of a "journal de genèse". In this case, the diary provides information and reflections about the writing process and its progress, but its content is not directly utilised in the texts. This happens mainly in the 1960s with "L'Aveuglement" (), Requiem () and Campagne perdue (), where "Roud se fait le metteur en scène et le critique de ses recueils; il donne les clés de leur composition, il évalue les effets de ses choix" (: 13).
Given the importance of the diary in Roud's writing practices, it is fundamental to consider it as genetic material. Its nature, however, prevents us from placing it easily on one side or the other of our genetic network: a note recording visions and thoughts, despite representing a first phase of the writing process, and which will be reused in later texts, is not originally written with those later texts in mind nor as an element of an ongoing project. From a genetic point of view, this affects whether we should consider Roud’s diary an avant-texte or not. The author’s use of the diary is close to what Suzanne Simonet-Tenant calls the "diary as provision" ("journal provisionnel") (: 17): the entries are not conceived with a particular text in mind, but the writer knows that they might be reused. This category of use is close to the "reservoir" or "grenier poétique" used by Jaccottet (: 7) and accepted by several critics (;;;).
If we accept this role for the diary, we must consider that a note only becomes a "provision" when it is used as the basis for, or in the creation of, a new text or project. Rudolf Mahrer keenly argues that a document "a posteriorigénétique ne trouve son statut « avant-textuel », ou préparatoire, qu’en raison de ce qui se produit, après lui, dans l’histoire du texte considéré." (: 18). Thus, the diary does not obey to the logic of the avant-texte per se, but can be regarded as an avant-texte depending on our perspective. The genetic status of a document is part of the discourse that we impose on it and should not be considered an intrinsic quality. Because we tend to address Roud's œuvre as a complex whole, and not only to study the single works, our perspective continuously changes. We are reminded that a diary entry might later be included in several different texts, being used a posteriori, therefore,in several distinct geneses (see Section 3).
In the formal model presented in the next section, the diary is included in the genetic network. Its importance in Roud's writing practices, its autonomous nature, and the possibility for it to be reused in several heterogeneous creative processes, explain its position in the network: not directly included in the avant-texte of the genetic dossier but attached to it, to indicate a reuse of materials.
1.2. Post-editorial reuse
Mahrer's "genetic a posteriori" approach does not apply only to manuscripts. Though genetic criticism traditionally considers the bon à tirer as the final step of the writing process, by arguing that "rien ne peut signifier par principe l’arrêt du processus d’écriture" (: 21), Mahrer considers that a published text can itself become an avant-texte again, either of a reissue or of a new text, serving again as "provision". This overlapping of genesis and post-editorial genesis is so frequent in Roud's works as to become a hallmark.
In order to study the author’s poetics, we can distinguish the most common types of post-editorial reuse, that we organized in a provisional taxonomy, to be refined if different cases emerge. A frequent type of reuse is the incorporation into a poetry collection of a previously published text, in part or in its entirety. In the latter case, the whole completed text is inserted into a new ensemble, or network of co-texts, in which each text maintains its autonomy even as their linking enables new readings. In the former case, a portion of the original text is extracted and integrated into the poetry collection, as an independent textual unit () or as part of a new poem together with others () (see also Section 3). In both cases, the process involves the assembly of texts or fragments more than it does editing and rewriting.
The manuscript of Air de la solitude (private collection) clearly shows the steps in this process and how the reuse of materials might have a tangible aspect. This document consists of a batch of sheets entirely covered by pieces of published texts, cut from the originals and pasted one after the other, and finally amended with an ink pen. The only typed note in the document had not previously been published, coming instead directly from Roud's diary.
In addition to reuse in a poetry collection, a published text can be employed, partially or entirely, for the genesis of other kinds of texts, such as a poetic text for an article (see Section 4) or a piece of literary criticism (see , in which are partially reused and , themselves reusing previous articles).
The last type of reuse is essentially a ‘remake’, as in the case of a new edition of a published work directed by the author. In Roud's case, the most interesting of these, in terms of abundance of variation, are some of the works included in the 1950 Écrits (), his first collection of complete works.
An instinctive returning to what has already been conceived and should still be pursued emerges in Roud's writing practices. This instinct suggests an author working as an assembler or a composer, trying to produce a unity out of fragments of fleeting impressions, in a constant attempt to reunite and stabilise what is scattered and dispersed in the world and in his writing.
2. Data modeling for genetic editions
The process of data modeling is fundamental to the digital representation of any kind of information. We can distinguish between a conceptual model and its logical implementation; in both cases, a model can be defined as a consistent and explicit formalisation of our understanding of some particular data. Formal models enable two fundamental aspects of scholarly research: qualitative and quantitative analysis.
The qualitative aspect is necessary for the creation of the model, which represents the scholar's understanding, interpretation, and selection of relevant features of the object of study. In this sense, a data model is a scholarly argument: in comparison to the argument expressed in a paper, a formal model should be completely explicit; but, like a paper, it is build upon and can contribute to previous scholarship.
Once the data model is determined and data are encoded, a quantitative approach becomes possible. Using customised queries and algorithmic analysis (e.g. statistical or network analysis), patterns might emerge from the data, enlightening new aspects and confirming previous intuitions.
In the field of genetic criticism, as applied to digital scholarly editing, efforts in modelling have been mainly oriented towards the information carried by a single document. The establishment of the Text Encoding Initiative (TEI) as a standard for the encoding of textual phenomena may have played a role, providing a well-recognised and ready-to-use vocabulary, in use in many scholarly editions.
Regardless of the reasons, the current situation offers a number of excellent digital scholarly editions, in which the underlying data model deals with the text of each single witness, conveying in great detail what happens on the page: every addition, deletion, and substitution is identified (more rarely stages of composition are distinguished), revealing the author's decisions and doubts (for example , , , ). Some editions also give an account of textual variations, by means of a critical apparatus (), synoptic visualisations () or on-the-fly automatic collation (). In terms of data modeling, the TEI provides a suitable architecture for textual variants.
These examples demonstrate the potential of current scholarly editing practices to trace, model, and digitally represent the writing and rewriting processes that generally occur in single documents in the avant-texte. But in the case of Gustave Roud, as argued above, the genetic path is to be found in the selection and reuse of existing and, sometimes, published materials — not only in the avant-texte of the single work. Therefore a broader picture is needed: one which allows us to represent the genesis of various works converging into a new one, a process that cannot be traced by looking at a single manuscript, nor at the variants between two or more witnesses.
Since there is no established formal model for dealing with the relationships between the genetic witnesses, loose conceptual models can be inferred from the visualisations provided in genetic editions: indeed the diagrams available in these editions themselves carry a scholarly argument, in terms of form and content. Research on how to render visually the materials has not been neglected in genetic criticism and they have contributed to bring out the necessity of organising and defining the objects of study. An important essay in this sense is that of Daniel Ferrer, summarising previous experiences with the use of digital tools: various experiments mentioned dealt with how to place and link the genetic documents in the hyperspace enabled by the concept of hypertext. The need to give names to the links is explicitly acknowledged here: "Ce qui est sans doute à retenir de cette experience [with the software Storyspace] […] c'est la nécessité de nommer les liens et de prévoir des carrefours de liens" (: 200, italics in the original). We will see that the existing visualisations haven't yet given an answer to this question, that we address in the model presented below. Before introducing the model and the corresponding ontology, in the next subsection we summarise some design trends in the visualisation of genetic relationships.
2.1. Visualisation of genetic data
Digital scholarly editions with a genetic approach often include visualisations of their data. Visualisations provide a way to understand textual dynamics across documents at a glance or to explore the details of the genetic process.
As we focus on the relationships between documents, we shall consider here only visualisations that represent more than one manuscript. The vast majority, if not all, of the projects offering some data-visualisation are scholarly editions of a single work and present diagrams of its avant-texte.
In Les manuscrits de Madame Bovary () for example, the documents are organised in a bar-chart: the sections of the work are deployed along the horizontal axes, with the vertical axis implicitly representing time. Furthermore, the documents are coloured according to a genetic taxonomy ().
Les manuscrits de Madame Bovary. "Tableau génétique des brouillons".
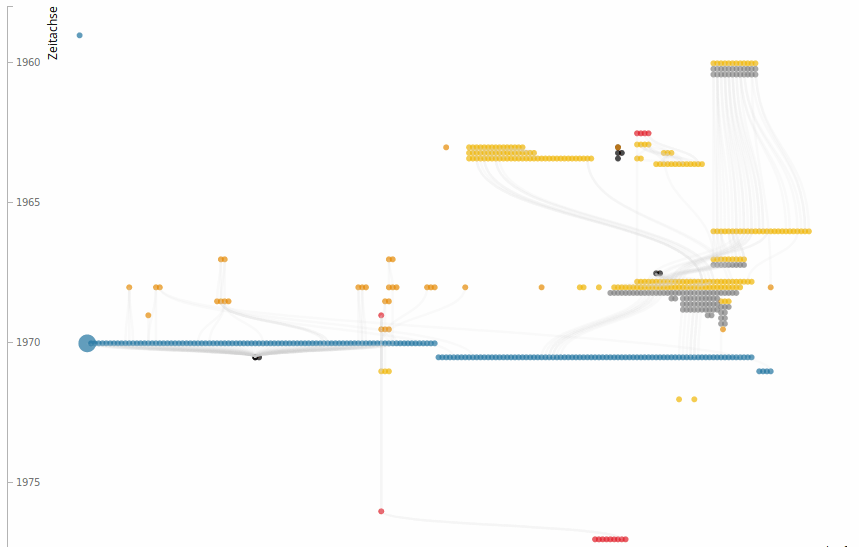
The same kind of information is presented in a different type of diagram in Hermann Burger, Lokalbericht. Digitale Edition (). The experimental visual navigation presents temporal progression on the vertical axis, and the texts on the horizontal axis. The texts are represented as lines consisting of individual circles, one for each page of the document. Lines connect the circles, indicating genetic relationship at page level. Here, too, the colours indicate the various kinds of avant-texte ().
Hermann Burger, Lokalbericht. Digitale Edition. Das genetische Dossier.
Though visualised differently, both these editions provide diagrams of the genetic dossier, showing a temporal progression and the relationship between the documents segmented in portions of the work. Information about the nature of the document is expressed with colours, while the position on the vertical axis (and, in the case of Lokalbericht, the lines connecting the circles) indicates that one document precedes to another. The genetic relationship is expressed in terms of temporal sequence and is not further specified. We shall see that, in the case of Gustave Roud's works, a qualification (and differentiation) of the nature of the genetic relationship is needed in order to include in the picture the author's diary as well as his drafts, journal publications, and poetry collections.
2.2. An ontology for genetic networks
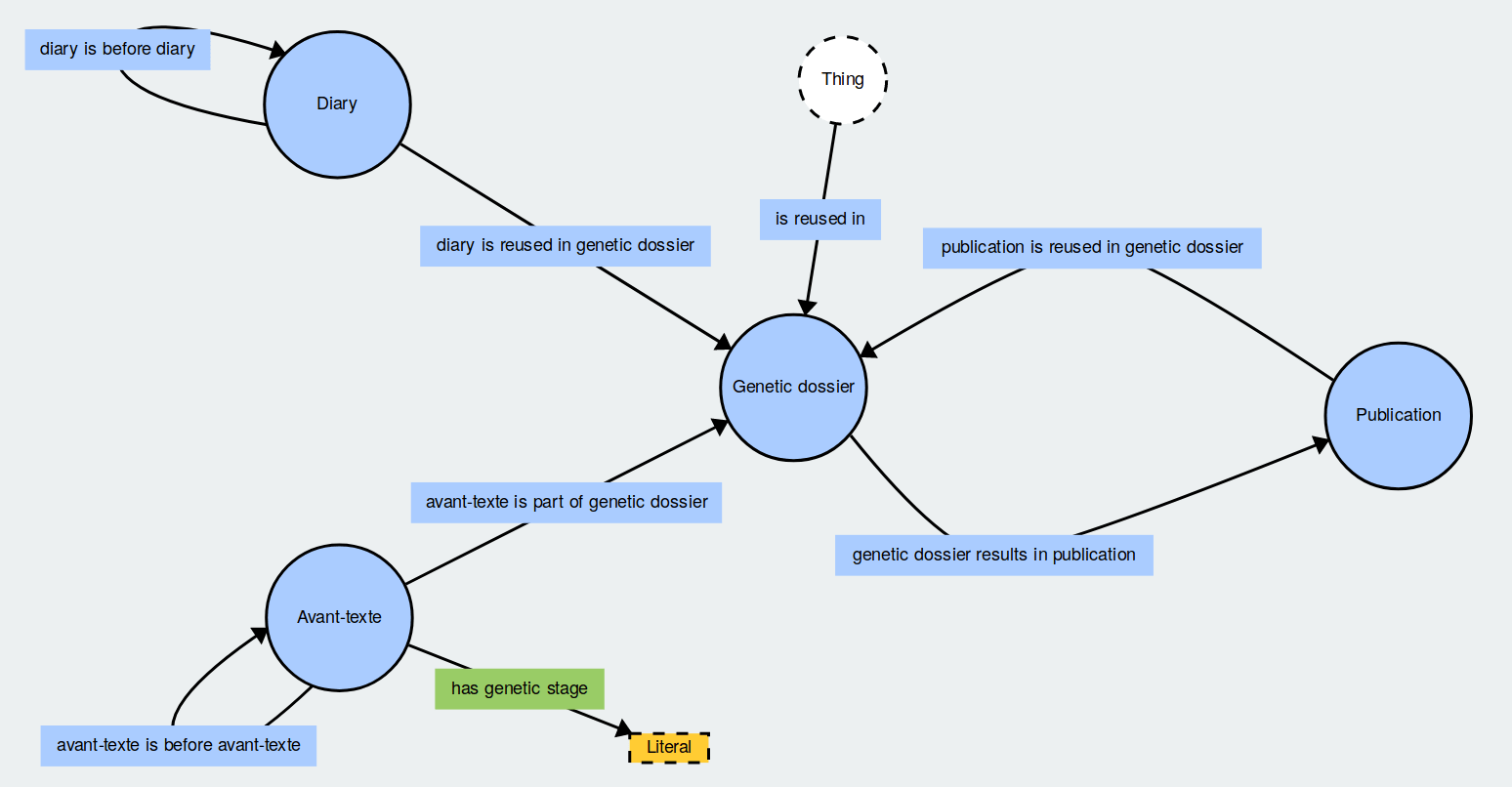
Our approach to modelling genetic relationships begins by thinking in terms of entities, their hierarchy and the connections between them. A motivation scenario and various competency questions have been created, together with a glossary of terms relevant in the field of genetic editing. We then organised the terms based on a specification relationship (connecting specific concepts to general ones) and on parthood (the partOf relationship) (), and afterwards distinguished nouns and verbs, in order to isolate the relations. The latters were central, since a model for the links is one of the missing pieces of formal models for genetic criticism, as argued above. This conceptual model has been translated into the OWL2 formal language. A visual rendering of the ontology is provided in . The ontology website is <https://gen-o.github.io/>. The modelling task has multiple goals: "[t]he main purpose of developing an ontology is to get a better understanding of the domain in question and to create a tool for analysing data concerning the domain" (: 184). We consider the ontology as a starting point for discussion and not yet as a complete resource, ready for use. This is why the technical development is not finished yet and the URI are still not resolvable.
The entities in our corpus are archival documents, divided into avant-textes (manuscripts, typescripts, corrected proofs, etc.; class :Avant-Texte) and diary entries (class :Diary), and publications (class :Publication). For each avant-texte, a genetic stage (property :hasGeneticStage) is defined; a possible list of genetic stages is: note, plan, list, draft, clean copy, final manuscript, annotated proofs, and annotated publication.
Avant-textes can be gathered in sets (class :GeneticDossier; property :avantTexteIsPartOfGeneticDossier) and each set, i.e. each genetic dossier, results in a publication (property :geneticDossierResultsInPublication). This tension towards the publication does not imply that all materials in the genetic dossier are present in the publication and does not prevent a document from being part of multiple dossiers.
We can then distinguish three major kinds of relationships between documents, publications and genetic dossiers, based on the discussion in the previous section (see section 1). Concerning the avant-texte, we follow the approach proposed by other projects, as exemplified in section 2.1: the chronological order is expressed through the property :avantTexteisBeforeAvantTexte. A second relationship type occurs when a diary entry is copied from a notepad or loose leaves carried in the author's pockets during his trips, to a clean notebook used at his desk. For this step, the property :diaryIsBeforeDiary is used.
The third kind of relationship concerns post-editorial genesis, or epigenesis. As briefly touched upon in section 1, the publication does not close the genetic process in Roud's production; on the contrary, a publication frequently becomes part of a new genetic dossier. The reuse of published and unpublished material is indicated by the property :isReusedIn. Two sub-properties are used to specify the type of reuse: :diaryIsReusedInGeneticDossier and :publicationIsReusedInGeneticDossier.
In the case of the reuse of a document (a diary note), or of a previous publication, for a new text or collection, the property points to the genetic dossier of the new text. This means that it is possible to link a diary note or a publication to the dossier in which it has been used to produce a new text, but not to link the diary note or the publication to one specific document inside that dossier. This degree of granularity corresponds to the degree of interpretation that we wish to apply to the materials. All kinds of scholarly criticism (genetic, literary, etc.) create a discourse on the basis of evidence found in the analysed objects; in this case, we opted for a cautious approach, interpreting this evidence to a limited degree and considering the possibility of lost documents. The degree of granularity, and of interpretation, might be refined in future works and should in any case be customised if the model were to be applied to a different corpus.
Visual rendering of the ontology, produced with WebVOWL.
In the project "Gustave Roud, Œuvres complètes", the ontology is implemented in an infrastructure called Knora. This software framework is composed of a triplestore (GraphDB), a IIIF-compliant image server and an API. It allows for the storage, management, and long-term preservation of research data. Knora provides a base ontology which defines common data types, to be used in and extended by each project’s specific ontology. The Roud project’s specific ontology includes the classes and properties described above for modelling the genetic status of an entity and their relationships, as well as many others which cover the various aspects of the project.
2.3. Towards a LOD integrated model
The project specific ontology models not only the genetic networks created by the texts, but also other aspects: a description of the archival documents, the named entities referred to in Roud's texts or in editorial commentaries (persons and places), the works referred to (art, music, literature), Roud's complete bibliography and his biography.
As each of these portions of the ontology cover a different kind of information (and a different part of Roud's world), they need to be mapped to several existing ontologies. This step of the modeling process has not yet been accomplished in the project, but some principles have been set and will be addressed here.
As said, the project ontology deals with various aspects of the materials. The approaches presented here are based on previous researches on the use of semantic web technologies in digital scholarly editions (;). The part of the ontology dealing with information about persons can be mapped to FOAF and Dublin Core, and enriched by links to VIAF, DBpedia and the Dictionnaire historique de la Suisse; for places, reference to Geonames data can be provided. For the bibliography, the ontology can be mapped to Bibframe, providing links to Worldcat entries. The part of the ontology covering biographical information is organised into events and can be mapped to entities in Schema.org. For the archival documents, Dublin Core can offer basic modeling, which could be enhanced by referring to the new standard, still in development, Records in Contexts. A Conceptual Model for Archival Description (RiC-O).
Concerning the text itself, the Knora framework is capable of managing XML files by mapping XML elements to standoff RDF properties, which are provided in a separate file along with the XML. This allows the storage of annotations attached to the texts in the triplestore. A TEI ontology (;;) can be used natively in this infrastructure.
Further thought should be given to the modelling of the genetic materials, the main focus of this article. For this part of the ontology, we turned to FRBRoo (), a general model for describing physical and digital bibliographical resources.
FRBRoo allows the expression of a bibliographic reference, differentiating and establishing a relationship between Work, Expression, Manifestation and Item. This structure, the central pillar of the model, is hard to apply to the organisation of the genetic materials. Accordingly, we contemplated two alternatives: (1) considering each document and each publication as a Work; or (2) considering the publication as a Work and the documents in its avant-texte as Expressions of it.
Before looking at these possibilities, we should exclude from our analysis the FRBRoo "Analysis of Creation and Production Processes" (: 21 and 27), and thus the classes F27 Work conception and F28 Expression Creation. Our model does not cover the act of creation, where explicit reference should be made to the actors involved and to its modality. Such a model should, however, be considered in the case of multiple authors or multiple actors contributing to the creation process.
In the first scenario, every draft, plan, list, and clean copy (that is, every instance of the class :Document) corresponds to FRBRoo F1 Work, as well as every publication (class :Publication). No correspondence can be found for the genetic dossier, nor for the genetic stage of each document. The property :isRewrittenIn, used for the diary in our model but which could be expanded to cover other cases, can be mapped to property R2 'is derivative of' (or to its reverse); this property can be refined by E55 Type 'Revision' and has the class F1 Work as both domain and range. The property :isReusedIncorresponds to CIDOC-CRM property P165 'incorporates', which models "the relationship that exists between pre-existing expressions that are re-used in a new, larger expression and that new, larger expression" (: 88). Furthermore, the poetry collections created by reusing existing materials corresponds to class F17 Aggregation Work, which may also include additional original parts.
The problem in this scenario is that the genetic documents in the avant-texte are considered as Works themselves. While a draft is recognised as a text per se, its features and function differ from those of a publication, precisely because of a draft’s relationship with the publication: in Ferrer's words, "ce n’est pas la genèse qui détermine le texte, mais le texte qui détermine sa genèse" (: 83). For genetic scholarship, the genesis is a reconstruction a posteriori, created from the point of view of the publication. Even if we consider the autonomy of each draft, its nature is provisional and unachieved, thus would hardly fit in the category of Work.
If the draft does not have a complete autonomy, the second alternative might be invoked, in which the genetic documents in the avant-texte are considered as Expressions of the publication, that is the Work. The limitation of this approach, however, is clear: the class F1 Work definition states that "Such concepts [the concepts informing the Work] may appear in the course of the coherent evolution of an original idea into one or more expressions that are dominated by the original idea" (: 54); but in genetic criticism the genesis is hardly definable as a "coherent evolution of an original idea". Treating the documents in the genetic dossier as Expressions would mean considering them as realisations of the publication, which is the Work; this view, however, seems to constraint the complex nature of the genetic documents.
Eventually, we asked ourselves if the FRBRoo model for bibliographical resources is indeed a suitable reference point for a model of genetic networks. At the moment, the formalisation presented in this papers is difficult to map onto this conceptual schema: the bibliographic approach represented in FRBRoo does not coincide with the genetic approach adopted here.
Despite these first findings, we think that it would be to the advantage of the genetic criticism community to further explore the complementarity, if not the integration, of the bibliographical model into a genetic one, and vice versa. It seems to be the direction chosen by the CRM tex working group, proposing an extension of CIDOC CRM for the study of ancient texts: they acknowledge the unsuitability of the FRBRoo model for dealing with textual entities, since it does not capture "the physical/conceptual duality of a sign", understanding the text "only as a conceptual object" (: 266). The CRMtex model, however, does not offer any meaningful mapping to our genetic model, because it does not take into account (yet?) any form of textual variance.
A more fitting correspondence can be found in RiC-O (see above). A record (RiC-E1 Record) would correspond to the archival document in our model, to be distinguished between avant-texte and diary. The record has a state, corresponding to the genetic stage (RiC-P21 Record State); the examples for this property list draft; final draft; original; simple copy; certified copy. The genetic dossier corresponds to a set of records (RiC-E3 Record Set). For the relations between records, a vast number of possibilities exist, among which RiC-R9 is predecessor of, RiC-R6 is copy of. Even if RiC-O, in the current state, does not cover all the concepts expressed in our model, we are waiting further developments to explore all the possibilities of a mapping to RiC-O. The model seems indeed very promising for our research and conceptually quite close to the domain of genetic criticism.
3. Case study: "Cendre"
"Cendre" () was published on July 10, 1930 in Aujourd'hui, signed with the name Adrien Delarze, one of Roud's pseudonyms. It is composed of twenty-three notes, twenty-two of which are surely taken from the author's diary. They are organised chronologically, from 1916 —the first year for which we have diary entries— to 1929 —the year preceding the publication of "Cendre"—, with two exceptions. Nine notes are reproduced in full or almost in full, while the other thirteen are the result of the selection of one or more parts of them.
Digital facsimile of "Cendre", Aujourd'hui n°32, 10 July 1930.
The notes are neither mixed nor recast; on the contrary, they are separated by multiple line breaks that confirm their autonomy (see ). All of them are taken from Roud's notebooks, which generally include clear texts, copied from pocket notebooks, small notepads or sheets. The author has probably gone through his notebooks in order to elaborate this text, looking for passages that could be taken up. As Daniel Maggetti points out:
La revue [Aujourd’hui] offre à Roud l’occasion d’une mise en forme qui autonomise les impressions et les intuitions dans lesquelles il cerne des repères de sa quête de sens […]. Mais sa recherche, tâtonnante, procède par énumération de signes et par juxtaposition de situations, plutôt qu’elle n’obéit à une ligne argumentative ou narrative. Ce que Roud vise et réalise de prime abord, c’est la restitution d’un climat, d’une atmosphère, non la composition d’ensemble d’une suite poétique maîtrisée. D’où une constante menace d’éclatement, et une incertitude quant à l’agencement des éléments d’un texte dont l’architecture est sans cesse questionnée. (: 105)
In the case of "Cendre", a strong link to the diary is maintained, as the chronological order suggests; furthermore, the chronological range is given at the end of the text ("1917-1930" (: 2). The poem seems to reduce to its essence the daily work of a long period. The very notion of "ash" (in French, cendre) underlines this aspect, designating the original diary entry, which is itself just a residue of life and of "former passions":
Anciennes passions, dois-je vous sentir mortes en moi, cendre sur cendre ? Il y a des heures où quelque libération me semble possible : une poésie confuse tente encore de vous étreindre, mais bientôt retombe l’élan. (: 1)
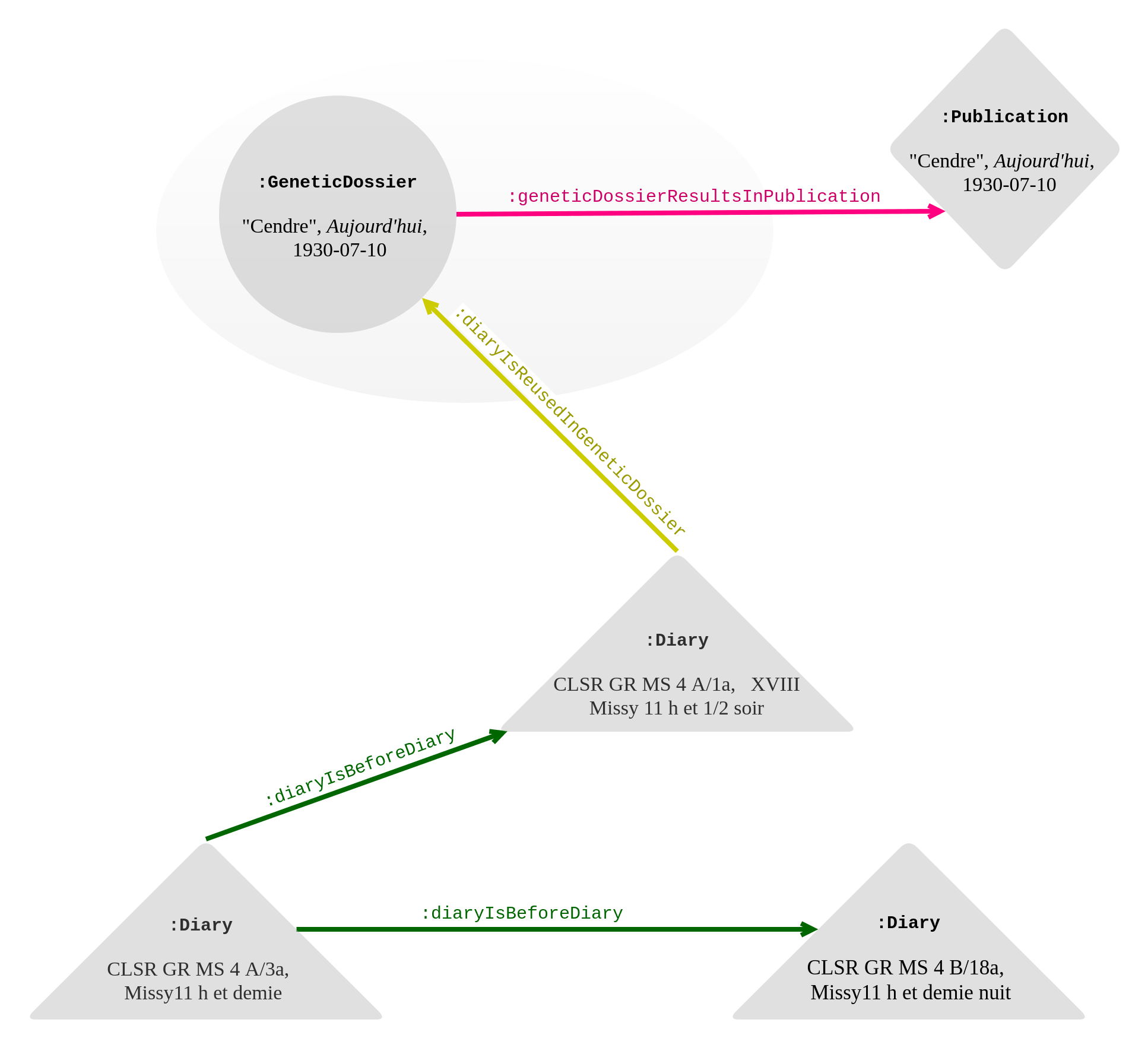
This kind of rhapsodic composition, assembling diary fragments, is common in the texts published in Aujourd'hui (1929-1931), although not all of them are composed from so many different notes. "Cendre" can thus be used as a case study for other texts with a similar genesis. The ontology presented above can be applied here as follows: the diary notes (:Diary :hasGeneticStage "diary note level 1") are copied (:diaryIsBeforeDiary) in notebooks (:Diary :hasGeneticStage "diary note level 2"). See for a visual representation.
Genetic network of "Cendre", Aujourd'hui n°32, 10 July 1930 (§2). Links from the genetic dossier are in pink; the diary rewriting in green; sub-properties of isReusedInin yellow.
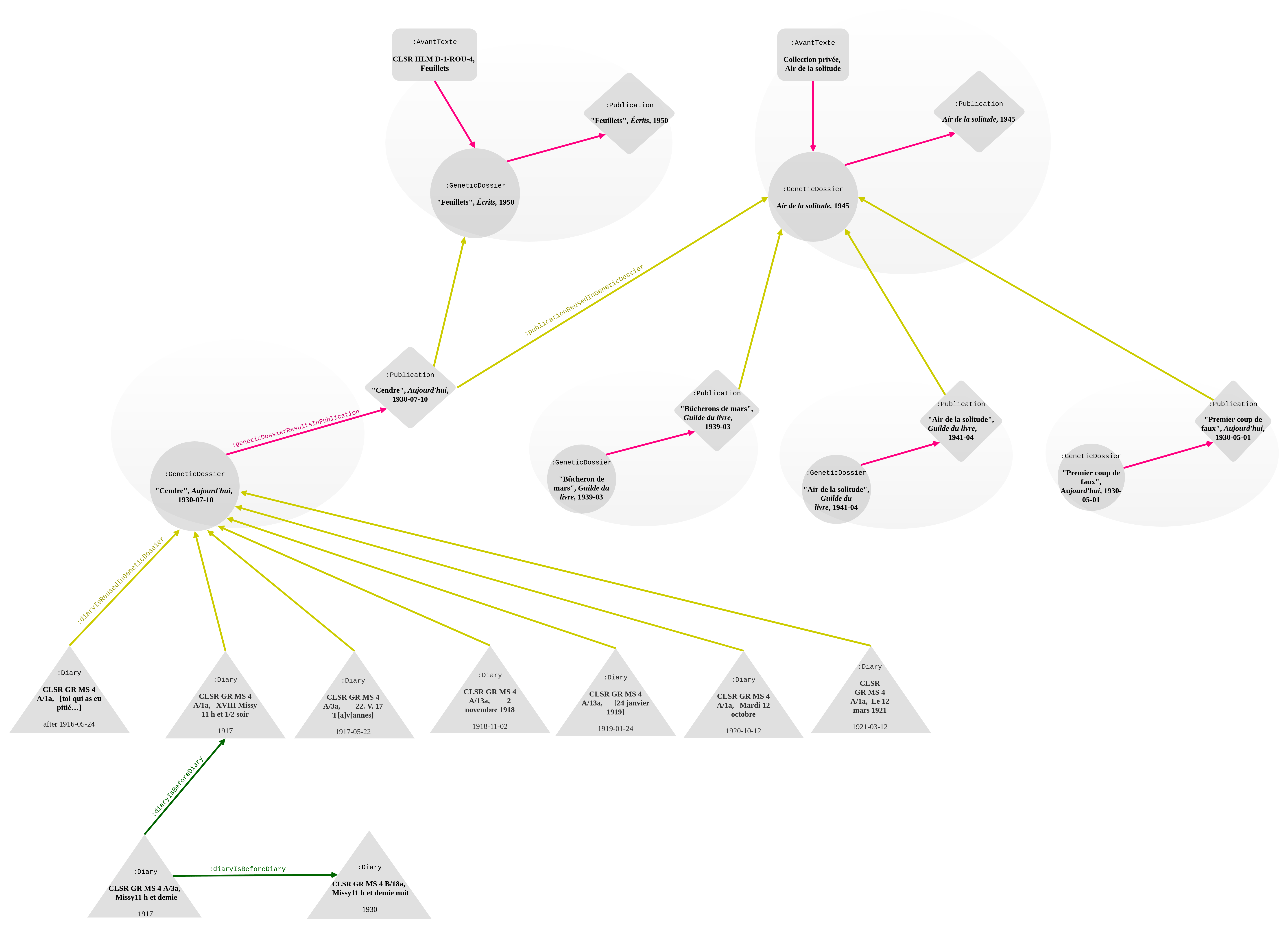
The following step in the composition process is that of the poetry collections: the author would select portions of published texts and re-organize them into a new work. In the case of "Cendre", some notes will be included with few modifications in Air de la Solitude (), while some others will appear as such in the revised version of Feuillets () (:publicationIsReusedInGeneticDossier). This is represented in , together with the other diary notes incorporated into "Cendre" (:diaryIsReusedInGeneticDossier). The model and its visual rendering allows us to pursue the arrangement and creation process, in which Roud undoes the old to form the new: in this way we can follow the journey of the text from the diary to the collection and trace the fragments’ provenance.
Genetic network of "Cendre", Aujourd'hui10 July 1930 (§1-§7), including its reuse in Feuilletsand Air de la solitude(§16-19). Links to (avantTextIsPartOfGeneticDossier) and from the genetic dossier are in pink; the diary rewriting in green; sub-properties of isReusedInin yellow. The labels are not repeated on all of the edges. The date is displayed for each diary entry to maintain chronological order.
4. Case study: Requiem (part 1)
The second case study expounds upon the modelling of the genetic dossier, including multiple avant-textes and of the reuse of published materials.
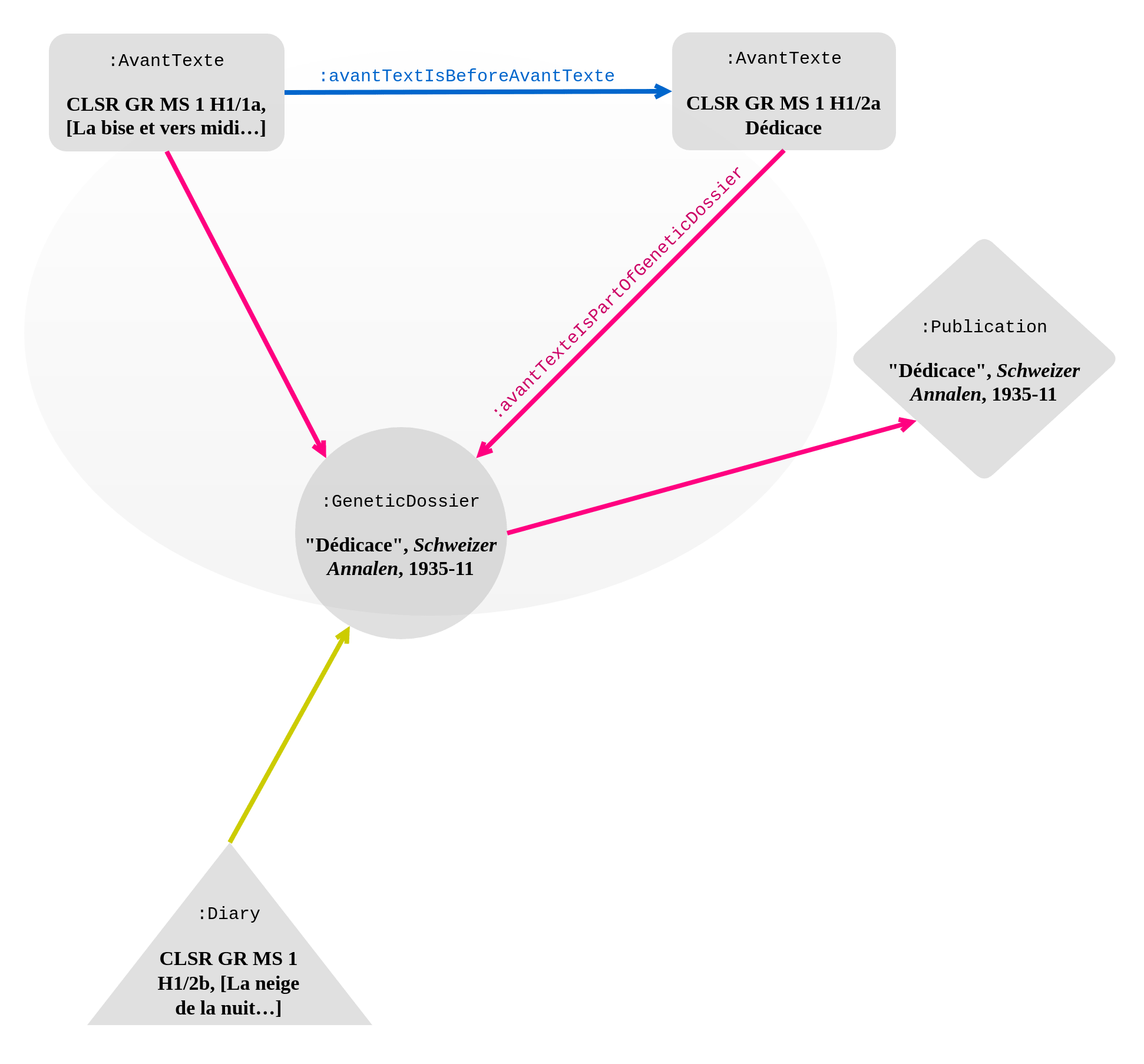
The entire first part of Requiem () had previously been published in journals, in three subsequent versions, each expanding the former. The 1935 text "Dédicace" () sets down what will become the beginning of Requiem; to this article is added new prose and together they form "Deux moments d'une quête" in 1941 (); this text, rearranged, and "Moulin de Lussery" (), published in 1934, converge into "D'une quête" in 1950 (). This last publication therefore builds upon three previous texts, to which are added new passages. In 1967 it will become, after a few modifications, the first part of Requiem.
In , the network for the first text, "Dédicace", is presented. A manuscript draft (CLSR GR MS 1 H1/2a) and a typescript clean copy (CLSR GR MS 1 H1/1a) populate the genetic dossier and are linked through the property :avantTexteisBeforeAvantTexte.
Genetic network of "Dédicace", Schweizer Annalen, November 1935. Links to the genetic dossier are in pink; the blue edges indicate the chronological succession of the documents in the genetic dossier; sub-properties of isReusedInare in yellow. Labels are sometimes omitted to avoid overcrowding the diagram.
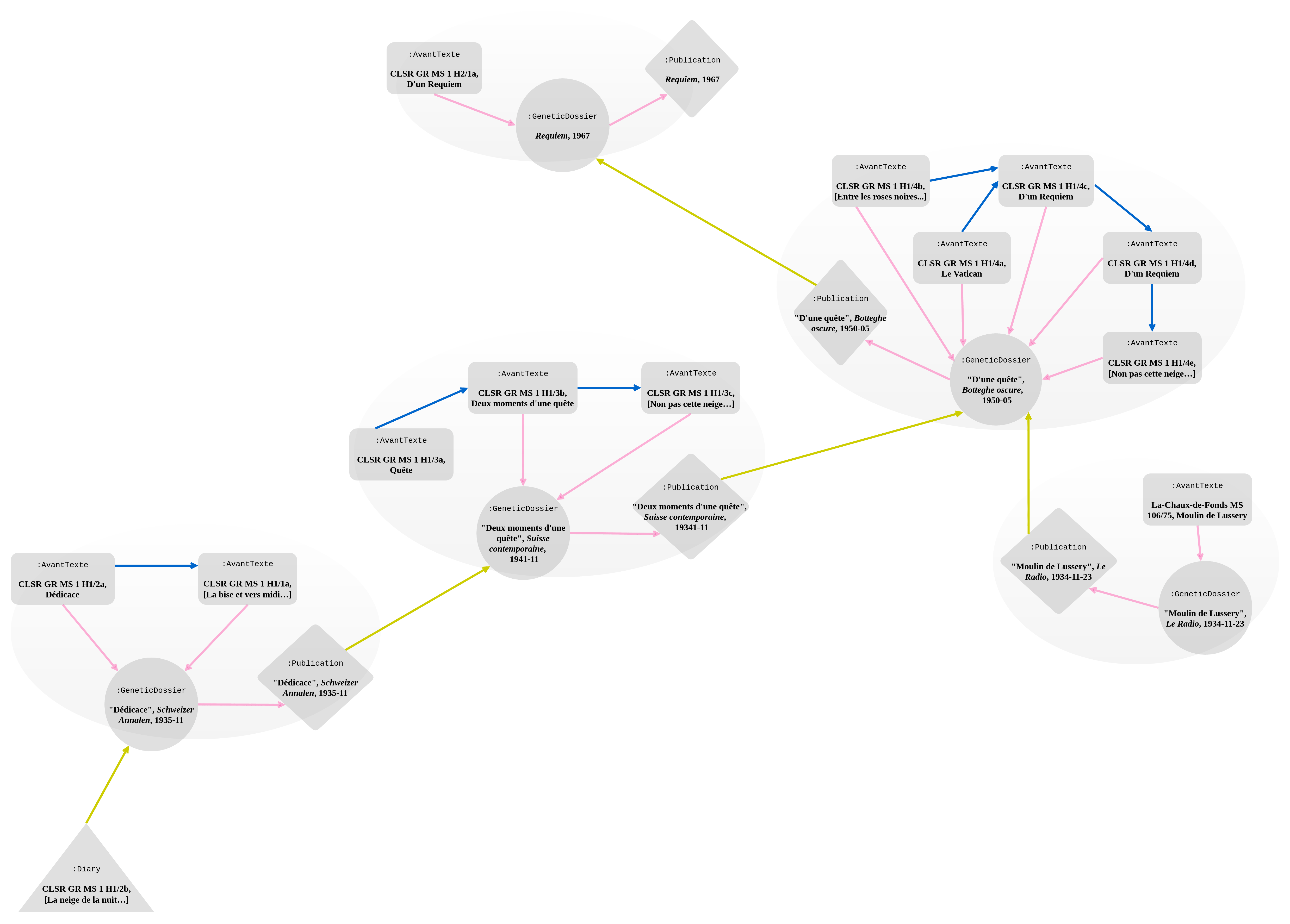
In , the entire genetic network for the first part of Requiem is displayed. In addition to "Dédicace", the genetic dossier of "Deux moments d'une quête", of "Moulin de Lussery" and of "D'une quête" are included. The textual reuse happening here is of different type to that of "Cendre": here the property :isReusedIn indicates the gradual extension of the text, up to "D'une quête", which is integrated in full into Requiem.
A first indication of Roud’s desire to expand the text into a "book" (in French, livre) appears as early as in the draft CLSR GR MS 1H1/2a:
p[our] le livre: récit allusif d’une mort, la chambre sans miroir, le sens des fleurs, les enfants qui ne veulent rien savoir – la parole qui les trahit. Psaume du voyageur, sa lecture par celui qui n’a pas compris.
The first part of Requiem is composed using a sort of amplificatio, where the beginning of the text stays the same and the rest is prolonged, augmented and recast. The model clearly shows this complex process.
Genetic network of Requiem (part 1). Links to and from the genetic dossier are in pinkt; the property avantTexteIsBeforeInAvantTextein blue; sub-properties of isReusedIn in yellow. Labels are sometimes omitted to avoid overcrowding the diagram.
Conclusions
This article presents a data model for genetic criticism, informed by and applied to the scholarly editing project "Gustave Roud, Œuvre complètes". The inclusion of a genetic perspective into a digital scholarly edition obliges us to reflect on formal models that can be implemented in such a context: while genetic and literary criticism makes use of the sources in order to formulate a scholarly discourse, in the edition the scholarly argument is conveyed mainly by the very organisation of the materials. In order to advance the rapprochement between scholarly editing and genetic criticism, we have made a first contribution towards a model that could address the needs of both fields.
Roud's œuvre offers a particularly stimulating corpus for such an endeavour. His writing process challenges the notion of avant-texte as the figurative place where genesis happens. The roots of Roud's texts can rarely be found in plans, lists and drafts, that is, in the avant-texte; far more frequent is the case in which the author gleaned from his diary or from already published works. In section 1, the role of the diary and its definition as a complex object of study are pursued: Roud's Journal should certainly be considered as genetic material, and we have argued why its position in our model is outside the genetic dossier, though directly connected to it. The use of existing texts as provisions for new ones applies not only to the diary but also to the published works: various kinds of reuse are identified, linking articles and poetry collections.
In section 2, our understanding of the corpus from a genetic point of view is translated into a formal model, implemented in an OWL2 ontology. Such a model has the potential to contribute to the scholarship on Roud, as well as to both scholarly editing and genetic criticism, enabling qualitative and quantitative research. The proposed schema responds to the lack of formal models for the creation of genetic networks: digital editions and related modeling proposals can now tackle the annotation of single genetic elements (drafts and other materials) or the analysis of the textual variation between them. Here we suggest a way to enlarge the object of study by modelling the relationships between genetic entities. This model allows to address cases such as those analysed in section 3 and 4, where multiple works converge into a new one and materials from the diary are reused at different stages of the writing process. The temporal dimension is central in the model, thus we use the properties ‘is before’ for the succession of diary level and of avant-textes. In this respect, our model is close to the data visualisation of the digital editions analysed. The difference, however, is that in our model it is possible to specify different kinds of temporal relationships for the various entities to be linked.
Once the entire corpus is annotated following this model, it will be possible to make fine-grained queries to retrieve subsets of it, for example: which of Roud’s works are rooted in his diary; of how many avant-textes is generally composed a genetic dossier; in which works it is reused the article "Cendre" published in the periodical Aujourd'hui in 1930; an avant-texte can belong to various genetic dossiers and, if yes, how many. Quantitative methods, such as stylometry or text-reuse algorithms, can also be applied to the annotated corpus. Eventually, data visualisations of the genetic networks obtained, accompanied by statistical results, can enable new readings of Roud's œuvre.
The work presented in the article should be continued and further tested in order to attain a degree of maturity permitting its use on other corpora. Nevertheless, the model has been conceived for being flexible and possible to adapt. This is why the distinction between documents of different nature is done using a property (:hasGeneticStage) and not defining a class for each stage. A possible refinement of the model would be to distinguish phases inside the avant-texte, separating and linking a pre-redactional stage — in which notes are collected, plans and lists drafted, and information gathered — and a redactional one; also, portions of the text might have different geneses that could be considered separately. All these issues should be addressed with multiple different case studies and involving the genetic criticism community, in order to conceive a conceptual model, or domain ontology, that would define core concepts and allow for its implementation in ontologies finely customized on each corpus.
In conclusion, taking into account the "hypertextual" and open dimension of the genesis allows better representation of the multiple possibilities available to the author during his work, showing the dynamic process that is taking place, and demonstrating the fact that not everything converges towards a published text. The published text itself can be conceived as a network of elements whose origins can be traced. As we have demonstrated, the network can be enlarged to the scale of the entire complete works, putting forward the different types of relationships between the texts, intertwining and responding to each other. Digital methods and technologies can be the editors' allies for modelling and representing this complex network of creative processes and archival documents in a scholarly edition.
Roud, Gustave. 1972. Campagne perdue. Lausanne: Bibliothèque des Arts.
Roud, Gustave. 1982. Journal. Edited by Philippe Jaccottet. Vevey: Bertil Galland.
Roud, Gustave. 2004. Journal: Carnets, Cahiers et Feuillets (1916-1971). Edited by Anne-Lise Delacrétaz and Claire Jaquier. 2 vols. Moudon: Ed. Empreintes.
Roud, Gustave. 2017. Entretiens. Edited by Emilien Sermier. Paris: Fario.
Other works cited
Appel, Bernhard, and Joachim Veit. 2019. Beethovens Werkstatt. Genetische Textkritik Und Digitale Musikedition. Accessed January 30, 2019. https://beethovens-werkstatt.de.
A.V. Les Manuscrits de Madame Bovary. Accessed January 30, 2019. https://www.bovary.fr/.
Bekiari, Chryssoula, Martin Doerr, Patrick Le Bœuf, and Pat Riva. 2016. Definition of FRBRoo. A Conceptual Model for Bibliographic Information in Object-Oriented Formalism. Version 2.4. Accessed January 30, 2019. https://www.ifla.org/files/assets/cataloguing/FRBRoo/frbroo_v_2.4.pdf.
Bellemin-Noël, Jean. 1971. Le Texte et l’Avant-Texte: Les brouillons d’un poème de Milosz. Paris: Librairie Larousse.
Biasi, Pierre-Marc de. 1996. Edition horizontale, édition verticale. Pour une typologie des éditions génétiques (le domaine français 1980-1995). In Éditer des manuscrits: archives, complétude, lisibilité, 159-193, edited by Béatrice Didier, Jacques Neefs, and Georges Benrekassa. Vincennes: PUV.
Bichitra: An Online Electronic Variorum Edition of the Works of Rabindranath Tagore. 2013. Accessed January 30, 2019. http://rabindranathtagore-150.gov.in/online-voriourum.html.
Bleier, Roman, Martina Bürgermeister, Helmut W Klug, Frederike Neuber, and Gerlinde Schneider, eds. 2018. Digital Scholarly Editions as Interfaces. Schriften Des Instituts Für Dokumentologie Und Editorik 12. Norderstedt: Book on Demand. Accessed January 30, 2019. http://www.bod.de/index.php?id=296&objk_id=2544467.
Bohnenkamp-Renken, Anne, Silke Henke, and Fotis Jannidis, eds. 2019. Johann Wolfgang Goethe: Faust. Historisch-Kritische Edition. Frankfurt am Main / Weimar / Würzburg. Accessed January 30, 2019. http://faustedition.net.
Bolioli, Andrea, and Roberto Rosselli del Turco. 2015. D 1.1: Stato dell’arte. ASED - Annotazione semantica per edizioni digitali. 2015. Accessed January 30, 2019. https://ased.celi.it/.
Ciccarese, Paolo, and Silvio Peroni. 2018. Essential FRBR in OWL2 DL (version 1.0.1). Accessed January 30, 2019. http://purl.org/spar/frbr.
Ciotti, Fabio, Marilena Daquino, and Francesca Tomasi. 2015. Text Encoding Initiative Semantic Modeling. A Conceptual Workflow Proposal. In Digital Libraries on the Move, 48–60. Springer. Accessed January 30, 2019. https://doi.org/10.1007/978-3-319-41938-1_5.
Ciotti, Fabio, and Francesca Tomasi. 2016. Formal Ontologies, Linked Data, and TEI Semantics. Journal of the Text Encoding Initiative 9.
Combe, Dominique. 2002. Du ‘recueil’ au ‘Poème-livre’, au ‘Livre-poème.’ Méthode, Le recueil poétique, no. 2: 15–22.
Dängeli, Peter, Wieland Magnus, Irmgard Wirtz, and Simon Zumsteg, eds. 2016. Hermann Burger: Lokalbericht. Digitale Edition. Beta-Version. Bern. http://www.lokalbericht.ch.
Davis, Ian, and Richard Newman. 2005. Expression of Core FRBR Concepts in RDF. Accessed January 30, 2019. http://vocab.org/frbr/core.
Debray-Genette, Raymonde. 1979. Genèse et poétique : Le cas Flaubert. In Essais de critique génétique, edited by Louis Hay, 21–67. Paris: Flammarion.
Debray-Genette, Raymonde. 1988. Métamorphoses du récit: autour de Flaubert. Paris: Editions du Seuil.
Delacrétaz, Anne-Lise. 2002. Sur la réédition du Journal de Gustave Roud. Europe, no. 882 (October): 174–78.
De Nicola, Antonio, and Michele Missikoff. 2016. A Lightweight Methodology for Rapid Ontology Engineering. Commun. ACM 59 (3): 79–86. https://doi.org/10.1145/2818359.
Deppman, Jed, Daniel Ferrer, and Michael Groden, eds. 2004. Introduction: A Genesis of French Genetic Criticism. In Genetic Criticism: Texts and Avant-Textes, 1–16. Philadelphia: University of Pennsylvania Press.
Dillen, Wout, Elena Spadini, and Monica Zanardo. 2016. Il Lexicon of Scholarly Editing: Una bussola nella babele delle tradizioni filologiche. Ecdotica 13.
Eide, Øyvind, Arianna Ciula, and Fabio Ciotti. 2014. Ontologies, Data Modeling, and TEI. Journal of the Text Encoding Initiative 8.
Eide, Øyvind, and Christian-Emil Ore. 2019. Ontologies and Data Modeling. In The Shape of Data in Digital Humanities, edited by Julia Flanders and Fotis Jannidis, 178-196. New York: Routledge.
Felicetti, Achille, and Francesca Murano. 2017. Scripta Manent: A CIDOC CRM Semiotic Reading of Ancient Texts. International Journal on Digital Libraries 18 (4): 263–70. https://doi.org/10.1007/s00799-016-0189-z.
Ferrer, Daniel. 2008. La représentation hypertextuelle des manuscrits : Quelques leçons de douze années d’expériences. In L’Edition du manuscrit. De l’archive de création au scriptorium numérique, edited by Aurèle Crasson, 189–208. Louvain-La-Neuve: Bruylant-Academia
Ferrer, Daniel. 2011. Logiques du brouillon : Modèles pour une critique génétique. Paris: Editions du Seuil.
Flanders, Julia, and Fotis Jannidis. 2016. Data Modeling. In A New Companion to Digital Humanities, edited by Susan Schreibman, Ray Siemens, and John Unsworth, 229–37. Wiley-Blackwell.
Flanders, Julia, and Fotis Jannidis, eds. 2019. The Shape of Data in the Digital Humanities: Modeling Texts and Text-Based Resources. London: Routledge, Taylor & Francis Group.
Fraistat, Neil, Elisabeth Denlinger, and Raffaele Viglianti. 2019. The Shelley-Godwin Archive. Accessed January 30, 2019. http://shelleygodwinarchive.org.
Jaquier, Claire. 2004. Introduction. In Gustave Roud, Journal: Carnets, Cahiers et Feuillets, edited by Claire Jaquier and Anne-Lise Delacrétaz, vol. 1, 7–29. Moudon: Ed. Empreintes.
Kunz Westerhoff, Dominique. 2005. Les harmoniques de l’instant: Le Journal de Gustave Roud. Revue de Belles-Lettres, no. 1/2: 147–73.
Lejeune, Philippe. 2011. Le journal : genèse d’une pratique. Genesis, no. 32: 29–42. Accessed January 30, 2019. https://doi.org/10.4000/genesis.310.
Lovel Beddoes, Thomas. 2007. The Brides’ Tragedy. Romantic Circles. 2007. Accessed January 30, 2019. http://www.rc.umd.edu/editions/beddoes/intro.html.
Maggetti, Daniel. 2001. Naissance de la rhapsodie. In Gustave Roud, Ecrits à Carrouge, 101–6. Saint-Clément-de-Rivière: Fata Morgana.
Mahrer, Rudolf, ed. 2017a. Après le texte: De la réécriture après publication. Genesis 44.
Mahrer, Rudolf. 2017b. La plume après le plomb. Poétique de la réécriture des œuvres déjà publiées. Genesis, no. 44: 17–38. Accessed January 30, 2019. https://doi.org/10.4000/genesis.1731.
Mahrer, Rudolf, and Joël Zufferey. 2019. Variance. Accessed January 30, 2019. http://variance.ch/.
McCarty, Willard. 2004. Modeling: A Study in Words and Meanings. In A Companion to Digital Humanities, edited by Susan Schreibman, Ray Siemens, and John Unsworth. Oxford: Blackwell.
Meynard, Cécile, ed. 2012. Les journaux d’écrivains: Enjeux génériques et éditoriaux. Bern: Peter Lang.
Orlandi, Tito. 1999. Linguistica, Sistemi, Modelli. In Il ruolo del modello nella scienza e nel sapere, 73–90. Roma: Accademia nazionale dei Lincei.
Peroni, Silvio. 2017. A Simplified Agile Methodology for Ontology Development. In OWL: Experiences and Directions – Reasoner Evaluation, edited by Mauro Dragoni, María Poveda-Villalón, and Ernesto Jimenez-Ruiz, 55–69. Lecture Notes in Computer Science. Springer International Publishing.
Pierazzo, Elena. 2015. Digital Scholarly Editing: Theories, Models and Methods. Ashgate.
Ramuz, Charles-Ferdinand. 2005. Œuvres Complètes. Edited by Roger Francillon and Daniel Maggetti. 29 vols. Genève: Slatkine.
Riva, Pat, Patrick Le Bœuf, Patrick, and Maja Žumer. 2017. IFLA Library Reference Model A Conceptual Model for Bibliographic Information. https://www.ifla.org/files/assets/cataloguing/frbr-lrm/ifla-lrm-august-2017_rev201712.pdf.
Rouffiat, Françoise. 2004. Du Journal au poème. In Les chemins de Gustave Roud, edited by Peter Schnyder, 247–72. Strasbourg: Presses universitaires de Strasbourg.
Rousset, Jean. 1987. Sur Le ‘Journal’ de Roud. Cahier Gustave Roud. Approches de l’œuvre de Roud: Actes du colloque de Lausanne, 21 Novembre 1986 5: 23–30.
Schnyder, Peter. 2012. Gustave Roud dans son ‘Journal’, Vers une écriture poétique de l’instantané ? In Les Journaux d’écrivains: Enjeux génériques et éditoriaux, edited by Meynard, Cécile, 179–90. Bern: Peter Lang.
Shotton, Davi, and Silvio Peroni. 2018. FaBiO, the FRBR-Aligned Bibliographic Ontology (version 2.0). Accessed January 30, 2019. http://purl.org/spar/fabio.
Simonet-Tenant, Françoise. 2011. Le journal personnel comme pièce du dossier génétique. Genesis, no. 32: 13–27. Accessed January 30, 2019. https://doi.org/10.4000/genesis.425.
Sutherland, Kathryn, and Marilyn Deegan. 2012. Jane Austen’s Fiction Manuscripts.
Terras, Melissa M., Julianne Nyhan, and Edward Vanhoutte, eds. 2014. Defining Digital Humanities: A Reader. Routledge.
Tomasi, Francesca, Marilena Daquino, and Francesca Giovannetti. 2018. “Linked Data Ed Edizioni Scientifiche Digitali. Esperimenti Di Trasformazione Di Un Quaderno Di Appunti.” In 7th AIUCD Conference. Cultural Heritage in the Digital Age. Bari.
Unsworth, John. 2002. What Is Humanities Computing and What Is Not? Jahrbuch Für Computerphilologie 4: 71–84.
Van Hulle, Dirk. 2016. Modelling a Digital Scholarly Edition for Genetic Criticism: A Rapprochement. Variants, no. 12–13: 34–56. Accessed January 30, 2019. https://doi.org/10.4000/variants.293.
Van Hulle, Dirk, and Mark Nixon. 2011. Samuel Beckett Digital Manuscript Project. 2019 2011. www.beckettarchive.org.
Viollet, Catherine. 2011. Journaux de genèse. Genesis no. 32 (January): 43–62. Accessed January 30, 2019. https://doi.org/10.4000/genesis.314.
Viollet, Catherine, and Marie-Françoise Lemonnier-Delpy, eds. 2006. Métamorphoses du journal personnel: De Rétif de La Bretonne à Sophie Calle. Au coeur des textes 4. Louvain-la-Neuve: Academia-Bruylant.
Last URLs access: 30/01/2019
This article has been written jointly by the co-authors: in particular, Alessio Christen is responsible for sections 1,3,5 and Elena Spadini for the introduction and sections 2,4.
For its application to the critical edition of a Swiss author, see .
In Van Hulle's view, the notion of "macrogenesis" is a relevant point of intersection between genetic criticism and scholarly editing. The distance between scholarly editing and genetic criticism almost disappears in the case of the Italian filologia d'autore. The critique génétique proposed a way of reading the texts and of interpreting their unstable nature, on the basis of a genetic dossier which needed to be available (in printed or digital form): thus the edition of the text(s) is instrumental to the criticism. On the other hand, the goal of the filologia d'autore is to produce a scholarly edition which takes into account the genetic process and, eventually, enables the criticism. While the focus differs, the two traditions have much in common and have long ago started a profitable dialogue ().
The project "Gustave Roud, Œuvres complètes", based at the University of Lausanne and funded by the Swiss National Science Foundation, is directed by Daniel Maggetti and Claire Jaquier. In addition to the authors of this paper, the researchers working on the project are Julien Burri, Raphaëlle Lacord and Bruno Pellegrino. Most of the ideas presented here come from a joint effort of the team, whom we would like to thank here.
This is a large working definition. The term has been first used by Bellemin-Noël in 1972 (); for a diversified look on this concept, see the resources gathered in the corresponding page of the Lexicon of Scholarly Editing, at http://uahost.uantwerpen.be/lse/index.php/lexicon/avant-texte/.
The critical texts of the poetic works, of the articles of art and literary criticism and of the translations are established on the basis of their first edition. The manuscripts will be used to establish the critical text of the unpublished works and of the diary, whose different stages will be published: if a note has multiple stages, it will be present in the edition multiple times. The variants will not be included in the print edition, but will be available online.
Gustave Roud, radio interview with Suzanne Pérusset, recorded on 15 August 1956, broadcasted on 20 August by Radio Suisse romande (: 36).
This kind of intertextuality is so diffuse and fleeting in Roud's works that its inclusion in the genetic network would cause an exponential growth in complexity — of both the scholars' work and of the final product, to the detriment of its usability. A commented close-reading, as well as rules-based or machine learning algorithms, might give an account of the phenomenon.
The most important example from the 20th century is probably André Gide’s Journal des Faux-Monnayeurs. See .
See also : 45: "Que fait l’écrivain quand il prend une note ? Il s’enjoint (ou plutôt se suggère) d’utiliser le matériau recueilli, mais il y a de très grandes différences entre une note précisément orientée vers un passage défini, ou une idée notée dans le vide, au cas où…"
Dirk Van Hulle uses the term epigenesis or epigenetic variance (: 46-47) to refer to the post-editorial development of a single textual genesis. His recent work also aims to implement a conceptualization and a representation of genetic steps, see Modelling Text-Genetic Relationships, with Joshua Schäuble, presented at DH2019https://dev.clariah.nl/files/dh2019/boa/0346.html.
For a clear and synthetic approach to data modelling in the fields of (Digital) Humanities, see ; the same authors pursued the subject in . The contributions of Tito Orlandi (drawing on systems theory) remain fundamental to understand the practice of modelling in Digital Humanities (at least, ). Willard McCarty’s analysis is also widely cited in relation to modelling in Digital Humanities (;). In the field of Textual Criticism, particular attention is devoted to modelling in : 37-40 and elsewhere; see also , now in .
The question of the interface in digital scholarly editions is addressed in .
Other digital editions provide equally fascinating visualisations. Among these, there is the representation of the writing layers in the facsimiles, included in (in particular the VideApp); and the visualisation of the writing sequence of a manuscript in (for L'Innomable, see http://www.beckettarchive.org/writingsequenceofinnommable.jsp).
The dating of the manuscripts and their temporal relationships are also accurately recorded in , which offers an impressive visual representation in its Makrogenese-Lab, available for the entire work as well as for the single scenes (http://faustedition.net/macrogenesis/). Remarkably, in this case each statement (i.e. the absolute or relative dating) is associated with its critical source; conflicting statements are displayed only in the scene graphs and not in the complete graph.
We haven’t completely followed a development methodology for the ontology, but our procedure has points in common with De Nicola-Missikoff (). This approach has been retained because of its relative easyness of application in the context of a Digital Humanities project in which the domain experts have a prominent role. The creation of a motivation scenario and of competency questions have been added to this methodology, for clarity and testing purposes, as promoted among others in .
For a dynamic rendering of the ontology, use the service at http://visualdataweb.de/webvowl/, entering the ontology IRI. WebVOWL add the class :Thing, when a property has no rdfs:domain specified; this is the case when the property has sub-properties with the same object but different subjects, as for :isReusedIn.
In the field of genetic criticism, see e.g. : 8: "the material of textual genetics is not a given but rather a critical construction", and, in particular on the avant-texte, : 38: "The avant-texte does not therefore designate the material manuscripts […] but rather the critical discourse by which the geneticist, having established the objective results of their analysis (transcriptions, relative dating, classification, etc.), reads them as successive moments of a process".
See for example Debray-Genette, already in 1979 (republished in 1988): "si l’on avait pensé jusqu’ici la génétique en termes d’évolution, le plus souvent même en termes de progrès, il semble qu’il faudrait incliner à la penser en termes de différence, lui accorder un fonctionnement plus autonome, lui accorder sa propre poétique" (: 19).
See : 52: "Ce qui est un grave échec pour un pirate est une fatalité pour les écrivains : leurs plans n’aboutissent jamais totalement, même dans les genèses les mieux assurées"; and : 68: "L’œuvre n’est pas un mobile se déplaçant comme un point immatériel repérable à chaque instant le long de la trajectoire représentée par la genèse, car l’œuvre, qu’il s’agisse d’un haïku ou d’un roman-fleuve, n’est ni ponctuelle ni instantanée".
The authors of state that "FRBRoo [...] deals only marginally with the concept of manuscript, and mainly in a modern sense, referring mostly as autographs created by authors, often as an avant-texte for possible future publication" (: 266). If it is true that FRBRoo mention authors' manuscripts multiple times in the examples, the relationships between them and to the publication is not analysed.
In this visual rendering the horizontal axis seems to convey a chronological development. While this is indeed a visualisation, the figure represents exactly how the data are stored in the database according to the model presented in section 2, and there is no attempt here to work on the visualisation itself. This step will be addressed later in the project and data visualisation will be provided on the project edition website, as it is done in the web applications discussed in section 2.1.
These are the competency questions used during the development of the ontology. See https://github.com/gen-o/geno.