Risorse linguistiche in LiLa: un primo abbozzo
Lemmi e morfemi: verso una Knowledge Base
L’ontologia delineata nella sezione precedente consente di descrivere gli aspetti morfologici (tanto flessionali quanto derivazionali) dei lemmi latini allo scopo di connetterli ai corpora lemmatizzati e alle entrate delle risorse lessicali.
Il passo successivo consiste nel creare una collezione la più esaustiva possibile di tali lemmi rappresentati secondo l’ontologia citata. Una risorsa estremamente preziosa per tale scopo è costituita dal già citato LEMLAT. Questo analizzatore morfologico è, infatti, fondato su una base lessicale costituita da 43.433 lemmi tratti da dizionari del latino classico, recentemente arricchita di ulteriori 82.556 lemmi di latino medievale e 26.250 nomi propri ( ), raccolti in un database relazionale; per ognuno degli oltre 150.000 lemmi, LEMLAT registra una serie di informazioni (quali genere, numero e, soprattutto, categoria flessionale) che sono utilizzate per produrre l’analisi dell’input.
Il cuore della Knowledge Base di LiLa è, dunque, rappresentato da questo insieme di lemmi, in cui ad ognuna delle entrate del database di LEMLAT è assegnato un identificatore univoco, le opportune rappresentazioni grafiche e le informazioni morfologiche appropriate definite nell'ontologia. Inoltre, ciascun lemma è collegato ai propri ipolemmi e alle varianti, secondo i criteri illustrati più sopra; poiché gli ipolemmi non sono inclusi tra i lemmi usati da LEMLAT, abbiamo proceduto a generare le forme participiali (presenti, passate e future) di tutti i verbi e gli avverbi deaggettivali.
Le relazioni fra lemmi, classi e proprietà morfologiche sono espresse utilizzando il Resource Description Framework (RDF) ( ) in forma di triple e sono salvate in un triplestore, che può essere interrogato utilizzando il linguaggio di query SPARQL ( ). Al momento, la base lessicale di LiLa comprende 130.925 lemmi, 92.947 ipolemmi, 292.657 written representation relative a lemmi e ipolemmi, 59.945 relazioni tra lemmi e ipolemmi e 6.120 relazioni di lemma variant. Infine, la Knowledge Base comprende 118 suffissi, 39 prefissi e 3.990 basi lessicali.
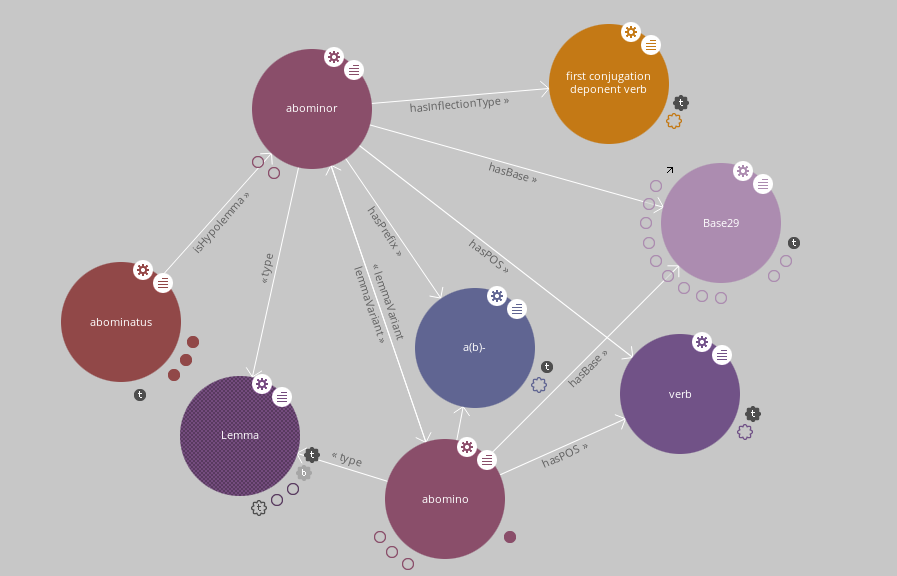
La mostra l’esempio della rete di relazioni intrattenute dal lemma abominor nella Knowledge Base LiLa. Il verbo è connesso alla sua classe flessionale (verbo deponente della prima coniugazione) e alla parte del discorso; inoltre, esso è legato da una relazione reciproca (si notino le frecce bidirezionali) alla sua variante attiva abomino, secondo quell’alternanza non infrequente attivo/deponente che abbiamo citato a mo’ di esempio; infine, esso ha una serie di ipolemmi, tra cui solo il participio passato abominatus è riportato in figura. Le due varianti sono poi entrambe connesse ai due morfemi che ne spiegano la derivazione nella famiglia cui appartiene anche il verbo ominor, ovvero il prefisso a(b)- e la base lessicale (contrassegnata dall’identificativo numerico 29
) condivisa anche dal sostantivo omen. Espandendo quest’ultima entità, la Base 29
, è possibile raggiungere tutti gli altri lemmi connessi alla famiglia derivazionale e mostrare le informazioni morfologiche e le connessioni di ciascuno. Seguendo, invece, il link rappresentato dalla categoria flessionale si possono elencare tutti i verbi deponenti della prima coniugazione registrati in LiLa, espandendo significativamente la rete d’interazioni mostrate.
Le informazioni relative ai lemmi e alle loro proprietà sono accessibili al pubblico sia attraverso uno SPARQL endpoint sia attraverso un'interfaccia di ricerca semplificata; la collezione può essere altresì esplorata attraverso una piattaforma che produce visualizzazioni analoghe a quella riportata nella .
La pagina da cui è possibile interrogare lo SPARQL endpoint include alcune ricerche già predisposte a titolo esemplificativo. In una di esse, ad esempio, è possibile richiedere la lista di lemmi connessi alla base lessicale a cui appartiene il lemma classis
classe, flotta
; i nove risultati includono lemmi come classicus
appartenente ad una classe / alla flotta
o classarii
soldati della flotta
. L’interfaccia di ricerca consente di combinare le proprietà linguistiche descritte nell’ontologia (come ad esempio la parte del discorso, il genere, il collegamento ad una base o ad un affisso) ed ottenere l’elenco dei lemmi che soddisfano i criteri selezionati dall’utente.
Verso l’integrazione dei corpora testuali
La più immediata applicazione della Knowledge Base consiste nel collegare i lemmi alle parole attestate nei corpora che possono essere lemmatizzate sotto di essi. Nel Bellum Gallicum di Cesare, ad esempio, incolunt (1.1.1 e 1.1.4), incoluerant (1.5.3) e incolant (2.3.4) sono forme (tra le tante altre) del verbo incolo e ciascuna di queste occorrenze può essere collegata al nodo di tale lemma in LiLa tramite un’opportuna proprietà dell’ontologia.
Il collegamento fra token e lemma sotto cui la forma può essere lemmatizzata viene esteso alla totalità di un corpus testuale. Naturalmente, un prerequisito imprescindibile è che il corpus che si vuole collegare abbia informazioni granulari sulla lemmatizzazione delle parole. Poiché, come si è accennato, la parte del discorso può contribuire a disambiguare forme e persino lemmi omografi (come ad esempio nel caso di artus, aggettivo, stretto
e artus, sostantivo, arto, articolazione
), è ragionevole includere anche il POS tagging tra i requisiti. Una risorsa testuale, dunque, deve essere annotata come minimo con questi due tipi di informazione per poter essere connessa alla rete delle risorse di LiLa.
I treebank del latino, che come si è accennato includono le informazioni richieste, sono un punto di partenza ottimale per valutare operativamente il procedimento di interconnessione fra le risorse attraverso LiLa.
Un primo passo verso tale integrazione è la conversione dei treebank, che sono distribuiti dai singoli sviluppatori in una varietà di formati, in una semplice rappresentazione RDF in cui frasi e token divengono nodi identificati tramite identificatori unici (URI: Uniform Resource Identifier). In un primo stadio di conversione, la maggior parte delle annotazioni viene registrata come un semplice attributo del nodo in forma di stringa (data property, in RDF), mentre le relazioni sintattiche di dipendenza o le relazioni lineari di sequenza nel testo possono essere rappresentate come link tra nodi.
A questo punto, un’elementare forma di match può essere effettuata confrontando ciascuna delle rappresentazioni scritte dei lemmi alla proprietà del token che registra la stringa usata per lemmatizzare la parola nel corpus. Nel caso in cui il corpus adotti una stringa di lemmatizzazione ambigua come artus, che corrisponde a più lemmi di LiLa, la parte del discorso può essere usata per consentire la disambiguazione. Alcuni casi di effettiva omografia fra parole che hanno la medesima POS, come i verbi uolo, volare
, e uolo, volere
, oppure i sostantivi tempus, tempo
e tempus,
tempia
(che condividono persino il paradigma flessionale), sono tuttavia destinati a rimanere insoluti.
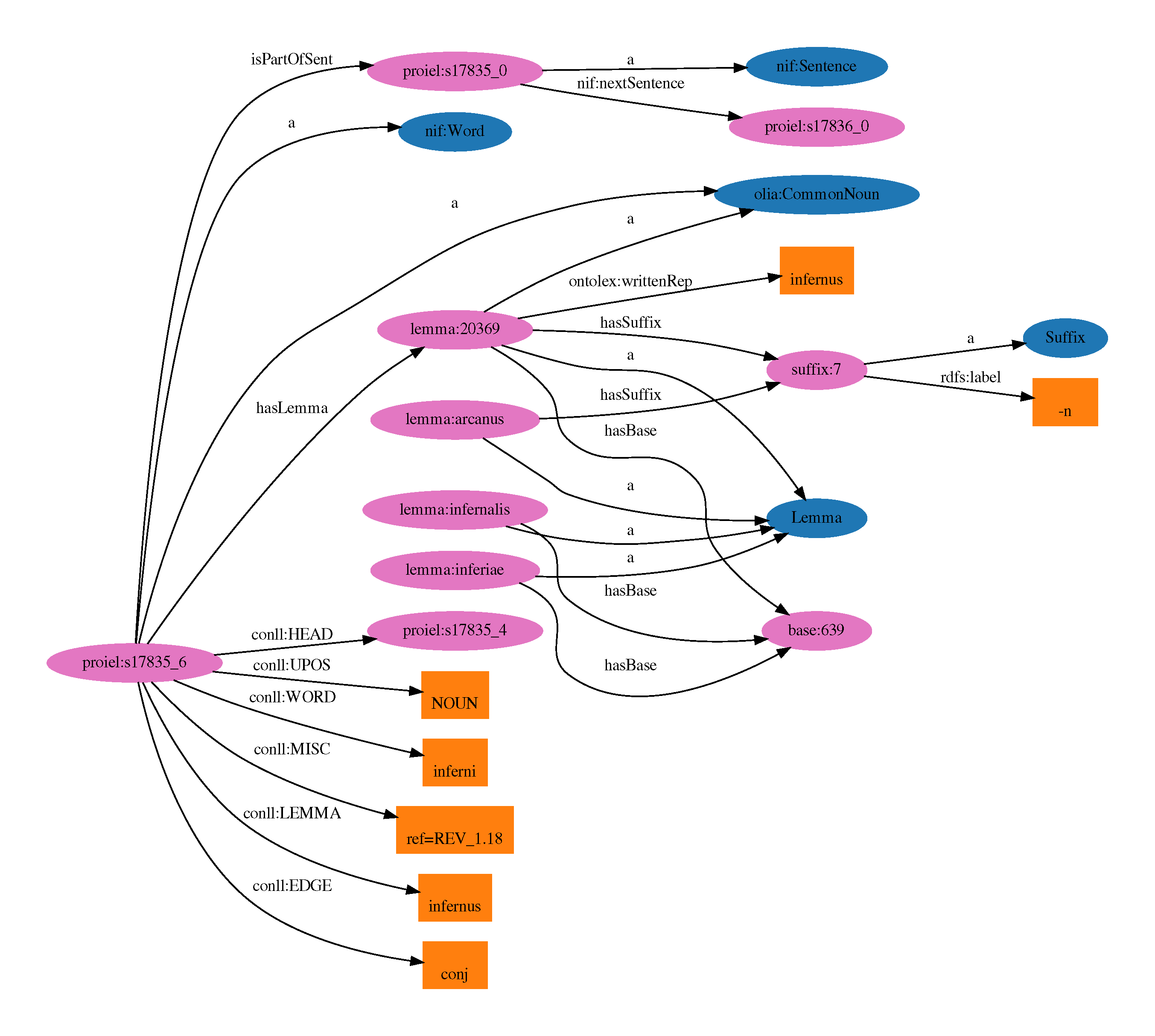
La raffigura un esempio dell’esito di un primo esperimento di collegamento operato sul corpus PROIEL. Il nodo posto alla sinistra nella figura (proiel:s17835_6) rappresenta il token corrispondente alla parola inferni tratta da una frase del corpus. Tra le proprietà che corrispondono alle annotazioni disponibili nella risorsa (i rettangoli arancioni in basso a sinistra) si nota la stringa che rappresenta il lemma: infernus. Tale stringa corrisponde alla rappresentazione scritta di due lemmi di LiLa, l’aggettivo infernus, sotterraneo, infernale
e il sostantivo corrispondente all’italiano inferno
. Solo quest’ultimo, tuttavia, condivide la POS con il token di PROIEL, cosicché la disambiguazione basata sulla parte del discorso lascia un solo candidato possibile.
La creazione di un link fra inferni in PROIEL e il lemma appropriato in LiLa inserisce il token della Apocalisse in una fitta rete di informazioni linguistiche. Il lemma, infatti, è legato a una base lessicale cui appartengono altre parole della medesima famiglia derivazionale, tra cui l’aggettivo inferus, inferiore, infernale
, e il sostantivo inferiae, offerte ai morti
; il nome infernus è poi formato tramite il suffisso -n, lo stesso utilizzato, ad esempio, nella derivazione (che non è mostrata nella figura, ma è immediatamente recuperabile dai dati di WFL connessi a LiLa) di arcanus, segreto, nascosto
, da arca, cassa, scrigno
.